分布式锁架构设计
锁用来解决什么问题呢
在我们编写的应用程序或者高并发程序中,不知道大家有没有想过一个问题,就是我们为什么需要引入锁?锁为我们解决了什么问题呢?
在很多业务场景下,我们编写的应用程序中会存在很多的 资源竞争 的问题。而我们在高并发程序中,引入锁,就是为了解决这些资源竞争的问题。
电商超卖问题
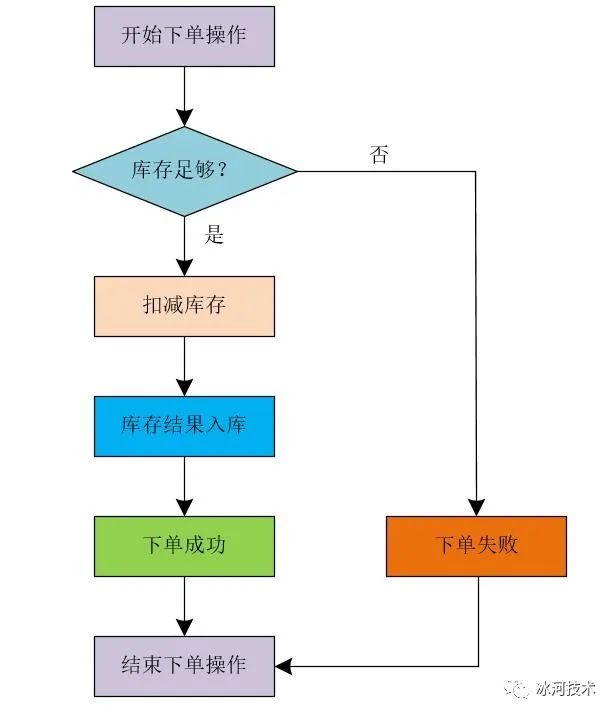
这里,我们可以列举一个简单的业务场景。比如,在电子商务(商城)的业务场景中,提交订单购买商品时,首先需要查询相应商品的库存是否足够,只有在商品库存数量足够的前提下,才能让用户成功的下单。下单时,我们需要在库存数量中减去用户下单的商品数量,并将库存操作的结果数据更新到数据库中。整个流程我们可以简化成下图所示。
我们可以使用下面的代码片段来表示用户的下单操作,我这里将商品的库存信息保存在了Redis中。
1 |
|
上述的代码看似是没啥问题的,但是我们不能只从代码表面上来观察代码的执行顺序。这是因为在JVM中代码的执行顺序未必是按照我们书写代码的顺序执行的。即使在JVM中代码是按照我们书写的顺序执行,那我们对外提供的接口一旦暴露出去,就会有成千上万的客户端来访问我们的接口。所以说,我们暴露出去的接口是会被并发访问的。
试问,上面的代码在高并发环境下是线程安全的吗?答案肯定不是线程安全的,因为上述扣减库存的操作会出现并行执行的情况。
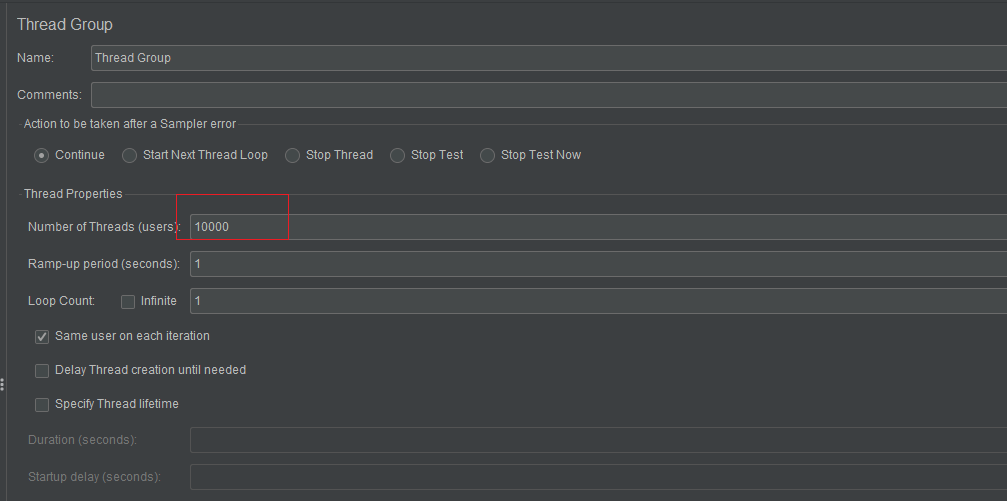
Jmeter 压测
我们可以使用Apache JMeter来对上述接口进行测试,这里,我使用Apache JMeter对上述接口进行测试。
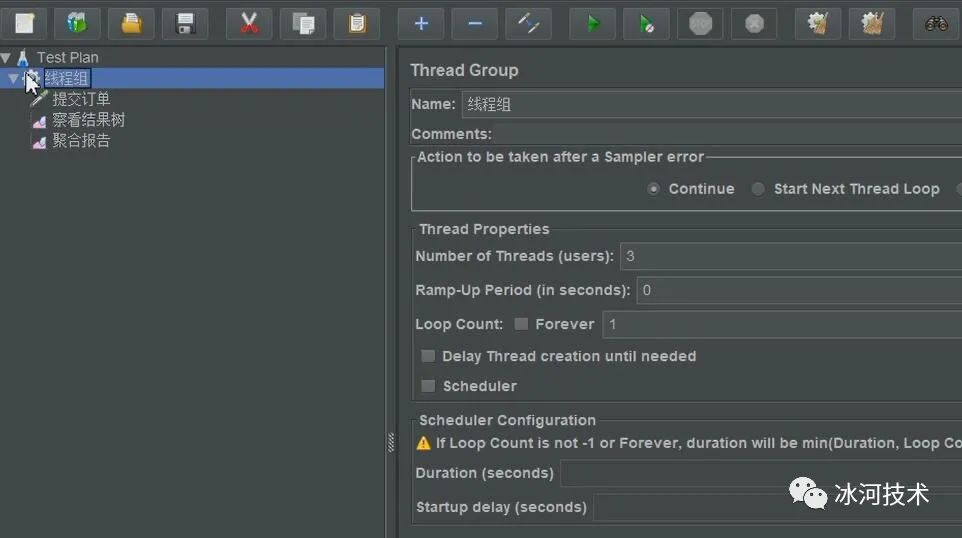
在Jmeter中,我将线程的并发度设置为3,接下来的配置如下所示。
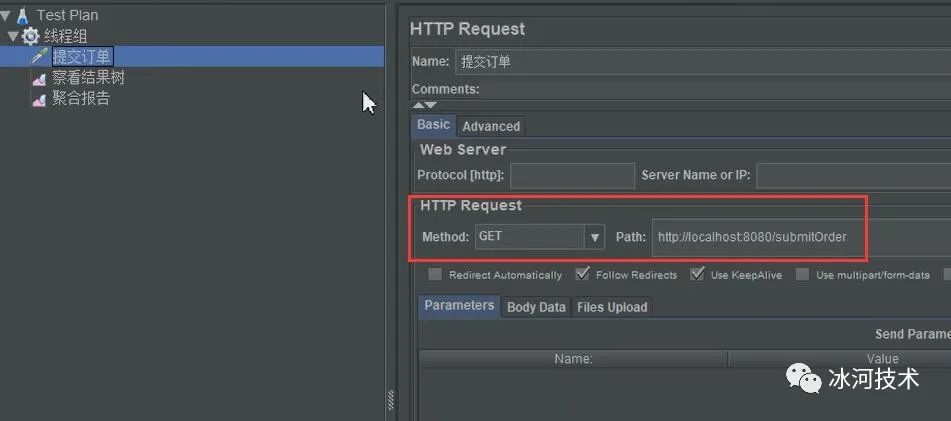
以HTTP GET请求的方式来并发访问提交订单的接口。此时,运行JMeter来访问接口,命令行会打印出下面的日志信息。
1 | 库存扣减成功,当前库存为:49 |
超卖现象
这里,我们明明请求了3次,也就是说,提交了3笔订单,为什么扣减后的库存都是一样的呢?这种现象在电商领域有一个专业的名词叫做 “超卖” 。
如果一个大型的高并发电商系统,比如淘宝、天猫、京东等,出现了超卖现象,那损失就无法估量了!架构设计和开发电商系统的人员估计就要通通下岗了。所以,作为技术人员,我们一定要严谨的对待技术,严格做好系统的每一个技术环节。
JVM中提供的锁
JVM中提供的synchronized和Lock锁,相信大家并不陌生了,很多小伙伴都会使用这些锁,也能使用这些锁来实现一些简单的线程互斥功能。那么,作为立志要成为架构师的你,是否了解过JVM锁的底层原理呢?
JVM锁原理
说到JVM锁的原理,我们就不得不限说说Java中的对象头了。
Java中的对象头
每个Java对象都有对象头。如果是⾮数组类型,则⽤2个字宽来存储对象头,如果是数组,则会⽤3个字宽来存储对象头。在32位处理器中,⼀个字宽是32位;在64位虚拟机中,⼀个字宽是64位。
| 长度 | 内容 | 说明 |
|---|---|---|
| 32/64bit | Mark Word | 存储对象的hashCode或锁信息等 |
| 32/64bit | Class Metadata Access | 存储到对象类型数据的指针 |
| 32/64bit | Array length | 数组的长度(如果是数组) |
Mark Work的格式如下所示。
| 锁状态 | 25bit或31bit | 1bit是否是偏向锁? | 2bit锁标志位 |
|---|---|---|---|
| 无锁 | 0 | 01 | |
| 偏向锁 | 线程ID | 1 | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 此时这一位不用于标识偏向锁 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 此时这一位不用于标识偏向锁 | 10 |
| GC标记 | 此时这一位不用于标识偏向锁 | 11 |
可以看到,当对象状态为偏向锁时, Mark Word 存储的是偏向的线程ID;当状态为轻量级锁时, Mark Word 存储的是指向线程栈中 Lock Record 的指针;当状态为重量级锁时, Mark Word 为指向堆中的monitor对象的指针
JVM锁原理
简单点来说,JVM中锁的原理如下。
在Java对象的对象头上,有一个锁的标记,比如,第一个线程执行程序时,检查Java对象头中的锁标记,发现Java对象头中的锁标记为未加锁状态,于是为Java对象进行了加锁操作,将对象头中的锁标记设置为锁定状态。第二个线程执行同样的程序时,也会检查Java对象头中的锁标记,此时会发现Java对象头中的锁标记的状态为锁定状态。于是,第二个线程会进入相应的阻塞队列中进行等待。
这里有一个关键点就是Java对象头中的锁标记如何实现。
JVM锁的短板
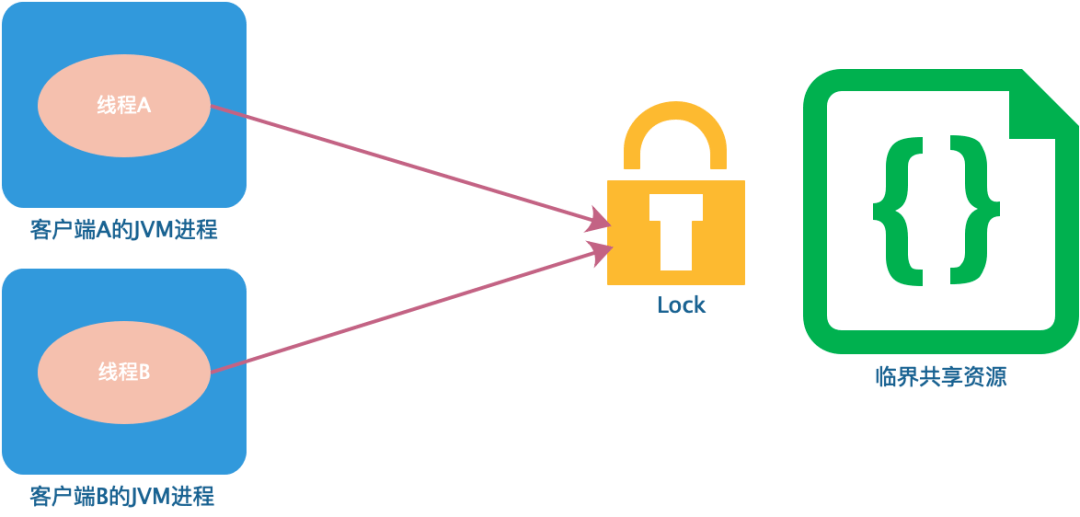
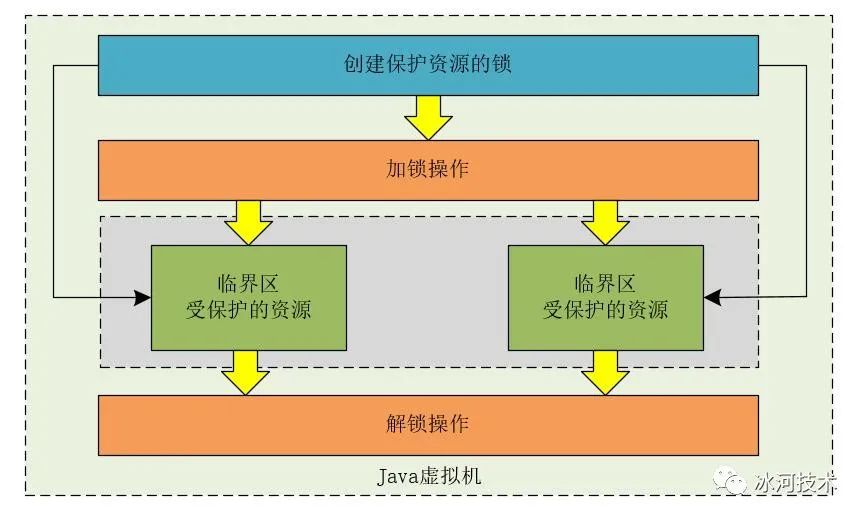
JVM中提供的synchronized和Lock锁都是JVM级别的,大家都知道,当运行一个Java程序时,会启动一个JVM进程来运行我们的应用程序。synchronized和Lock在JVM级别有效,也就是说,synchronized和Lock在同一Java进程内有效。如果我们开发的应用程序是分布式的,那么只是使用synchronized和Lock来解决分布式场景下的高并发问题,就会显得有点力不从心了。
synchronized和Lock支持JVM同一进程内部的线程互斥
synchronized和Lock在JVM级别能够保证高并发程序的互斥,我们可以使用下图来表示。
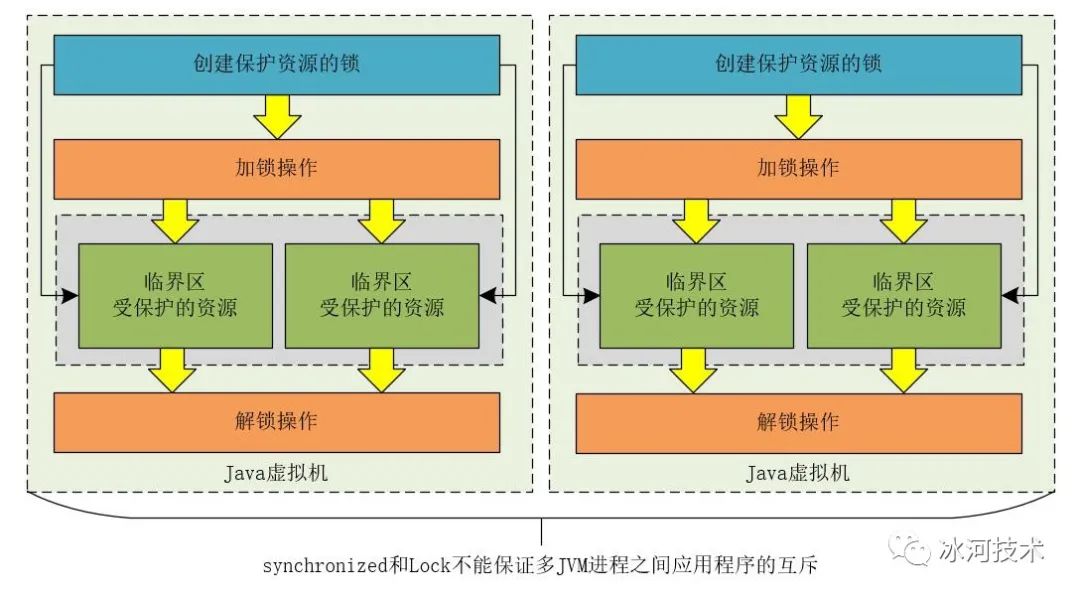
但是,当我们将应用程序部署成分布式架构,或者将应用程序在不同的JVM进程中运行时,synchronized和Lock就不能保证分布式架构和多JVM进程下应用程序的互斥性了。
synchronized和Lock不能实现多JVM进程之间的线程互斥
分布式架构和多JVM进程的本质都是将应用程序部署在不同的JVM实例中,也就是说,其本质还是多JVM进程
什么是分布式锁
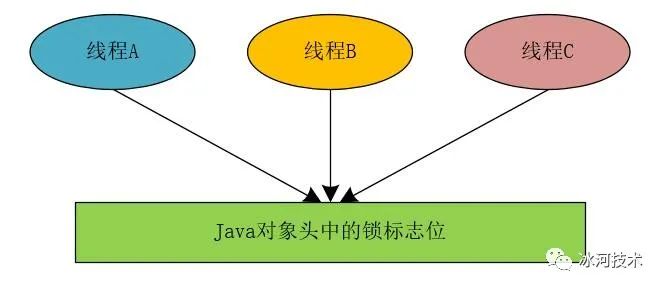
我们在实现分布式锁时,可以参照JVM锁实现的思想,JVM锁在为对象加锁时,通过改变Java对象的对象头中的锁的标志位来实现,也就是说,所有的线程都会访问这个Java对象的对象头中的锁标志位。
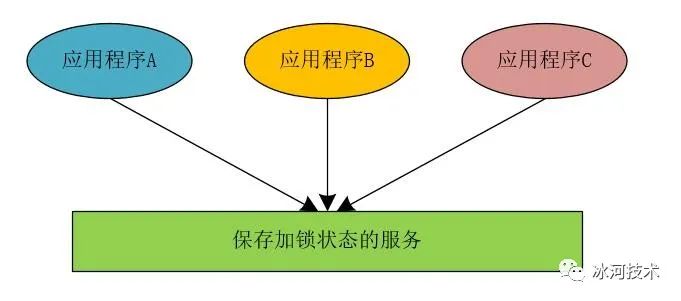
我们同样以这种思想来实现分布式锁,当我们将应用程序进行拆分并部署成分布式架构时,所有应用程序中的线程访问共享变量时,都到同一个地方去检查当前程序的临界区是否进行了加锁操作,而是否进行了加锁操作,我们在统一的地方使用相应的状态来进行标记。
分布式锁分类
控制分布式架构中多个模块访问的优先级,要介绍分布式锁,首先要提到与分布式锁相对应的是线程锁、进程锁。
线程锁
主要用来给方法、代码块加锁。当某个方法或代码使用锁,在同一时刻仅有一个线程执行该方法或该代码段。线程锁只在同一JVM中有效果,因为线程锁的实现在根本上是依靠线程之间共享内存实现的,比如synchronized是共享对象头,显示锁Lock是共享某个变量(state)。
进程锁
为了控制同一操作系统中多个进程访问某个共享资源,因为进程具有独立性,各个进程无法访问其他进程的资源,因此无法通过synchronized等线程锁实现进程锁。
分布式锁
当多个进程不在同一个系统中,用分布式锁控制多个进程对资源的访问。
分布式锁现状
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。
分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。也就是说单纯的Java Api并不能提供分布式锁的能力。所以针对分布式锁的实现目前有多种方案。
分布式锁实现方案
分布式锁的实现,目前比较常用的有以下3种方案:
- 基于数据库实现分布式锁
- 基于缓存(redis,memcached,tair)实现分布式锁
- 基于Zookeeper实现分布式锁
分布式锁定义
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁。
基于数据库
简单的方式就是建立一张锁表,通过操作该表的数据来实现了。
这种锁的设计是用数据库的乐观锁实现的,可以满足基本的交易的并发以及交易重试的幂等性。 大概实现就是,根据锁字段查找该锁是否存在,如果存在,则判断该锁状态,根据业务需要是否成功拿锁;如果不存在,则插入锁;
问题演示
假设现在订单已经生成成功,那么就会涉及到扣减库存的操作。当高并发下同时扣减库存时,非常容易出现数据错误问题。
扣减库存数据错误
通过jemeter进行测试,可以发现。当模拟一万并发时,最终的库存数量是错误的。这主要是因为当多线程访问时,一个线程读取到了另外线程未提交的数据造成。


synchronized失效问题
对于现在的问题,暂不考虑秒杀设计、队列请求串行化等,只考虑如何通过锁进行解决,要通过锁解决的话,那最先想到的可能是synchronized。根据synchronized定义,当多线程并发访问时,会对当前加锁的方法产生阻塞,从而保证线程安全,避免脏数据。但是,真的能如预期的一样吗?
1 |
|
当前已经在在方法上添加了synchronized,对当前方法对象进行了锁定。 通过Jemeter,模拟一万并发对其进行访问。可以发现,仍然出现了脏数据。

事务导致锁失效
该问题的产生原因,就在于在方法上synchronized搭配使用了**@Transactional。首先synchronized锁定的是当前方法对象,而@Transactional会对当前方法进行AOP增强,动态代理出一个代理对象,在方法执行前开启事务,执行后提交事务。 所以synchronized和@Transactional其实操作的是两个不同的对象,换句话说就是@Transactional的事务操作并不在synchronized**锁定范围之内。
假设A线程执行完扣减库存方法,会释放锁并提交事务。但A线程释放锁但还没提交事务前,B线程执行扣减库存方法,B线程执行后,和A线程一起提交事务,就出现了线程安全问题,造成脏数据的出现。
MySQL乐观锁实现
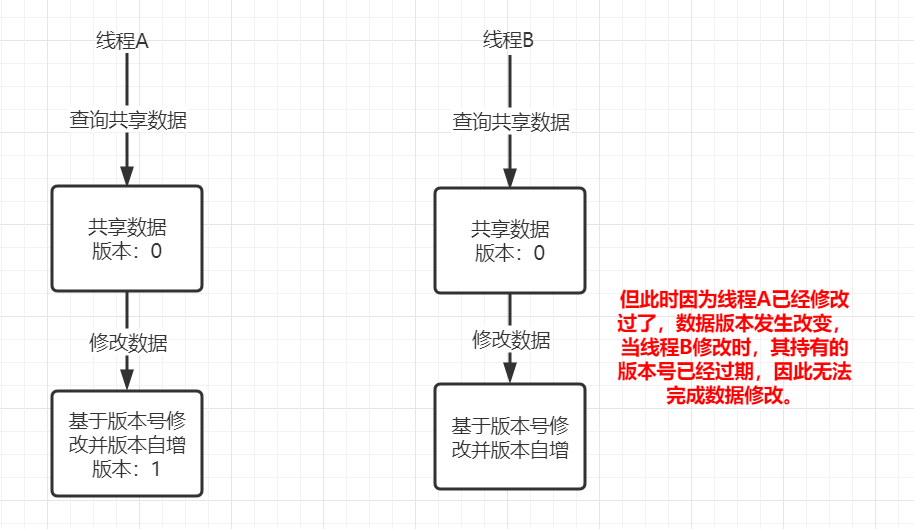
基于版本号实现
MySQL乐观锁是基于数据库完成分布式锁的一种实现,实现的方式有两种:基于版本号、基于条件。但是实现思想都是基于MySQL的行锁思想来实现的。
修改数据表,添加version字段,默认值为0
修改StockMapper添加基于版本修改数据方法
1 |
|
- 测试模拟一万并发进行数据修改,此时可以发现当前版本号从0变为1,且库存量正确。
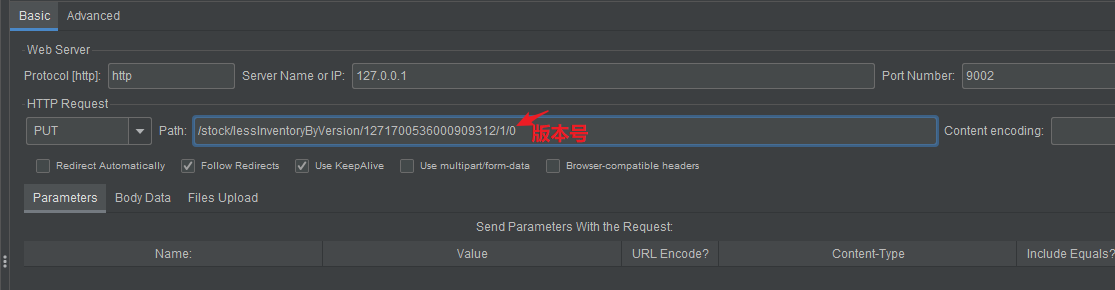

基于条件实现
通过版本号控制是一种非常常见的方式,适合于大多数场景。但现在库存扣减的场景来说,通过版本号控制就是多人并发访问购买时,查询时显示可以购买,但最终只有一个人能成功,这也是不可以的。其实最终只要商品库存不发生超卖就可以。那此时就可以通过条件来进行控制。
修改StockMapper
1 |
|
修改StockController
1 |
|
通过jemeter进行测试,可以发现当多人并发扣减库存时,控制住了商品超卖的问题。