ElasticSearch 聚合查询

指标聚合
指标聚合比较简单,大多数都是对查询返回的数据进行简单的数值处理
Max
Max 聚合可以统计最大值,类似 MySQL 数据库中的 max 函数
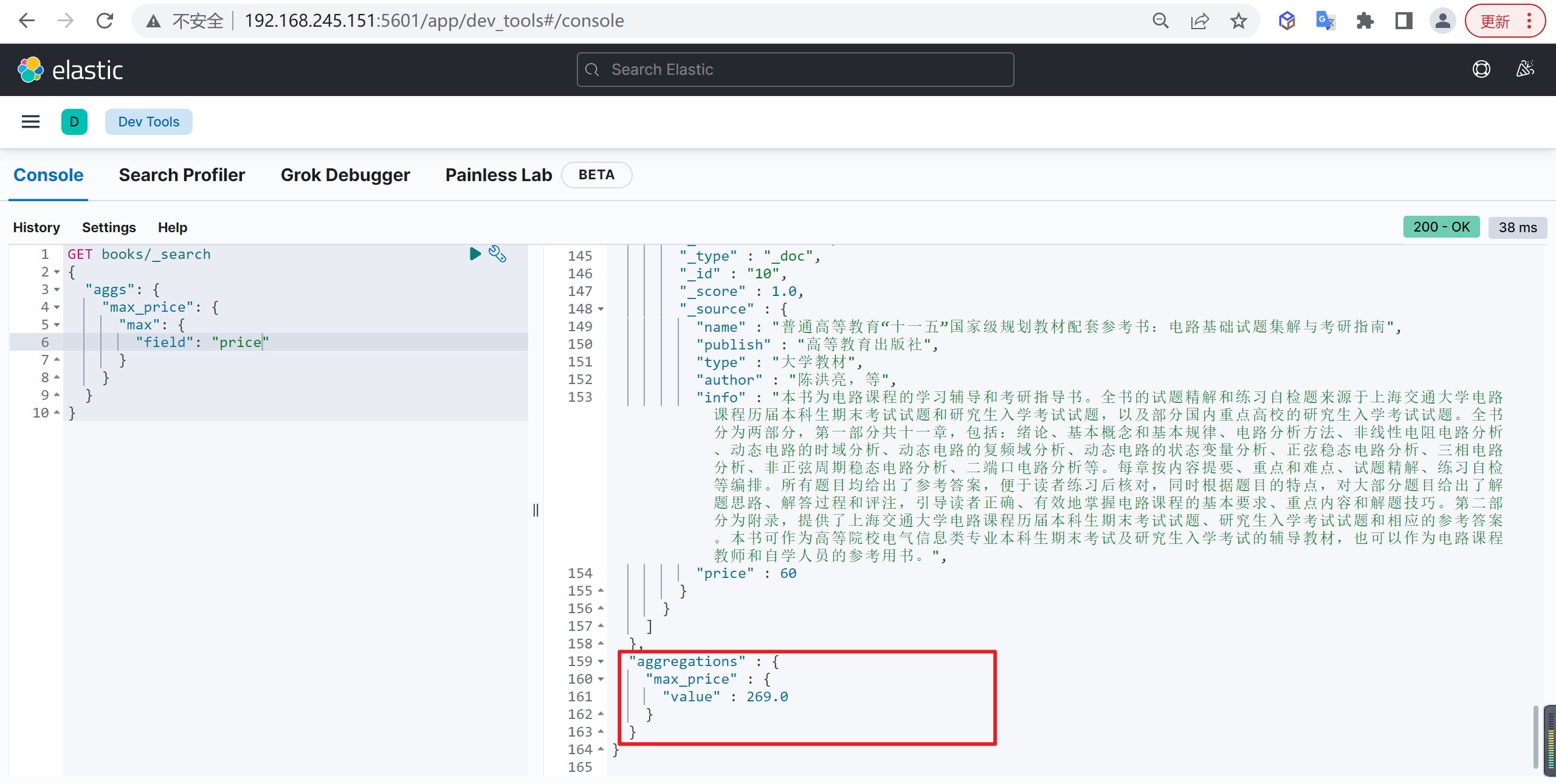
基本查询
例如查询价格最高的书籍
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price"
}
}
}
}
|
聚合结果在最下面,我们发现数据最大的值是269
设置默认值
有些文档没有price字段,还可以使用 missing 来设置默认值
插入文档
插入的字段没有price
1
2
3
4
5
6
7
8
| POST books/_doc
{
"name": "测试数据",
"publish" :"高等教育出版社",
"type" :"大学教材",
"author" :"大方哥",
"info": "高等教育出版社高等教育出版社高等教育出版社高等教育出版社高等教育出版社"
}
|
基本查询
我们下面就进行查询,使用 missing 参数,设置 price 空字段值为 1000
1
2
3
4
5
6
7
8
9
10
11
| GET books/_search
{
"aggs": {
"max_price": {
"max": {
"field": "price",
"missing": 1000
}
}
}
}
|
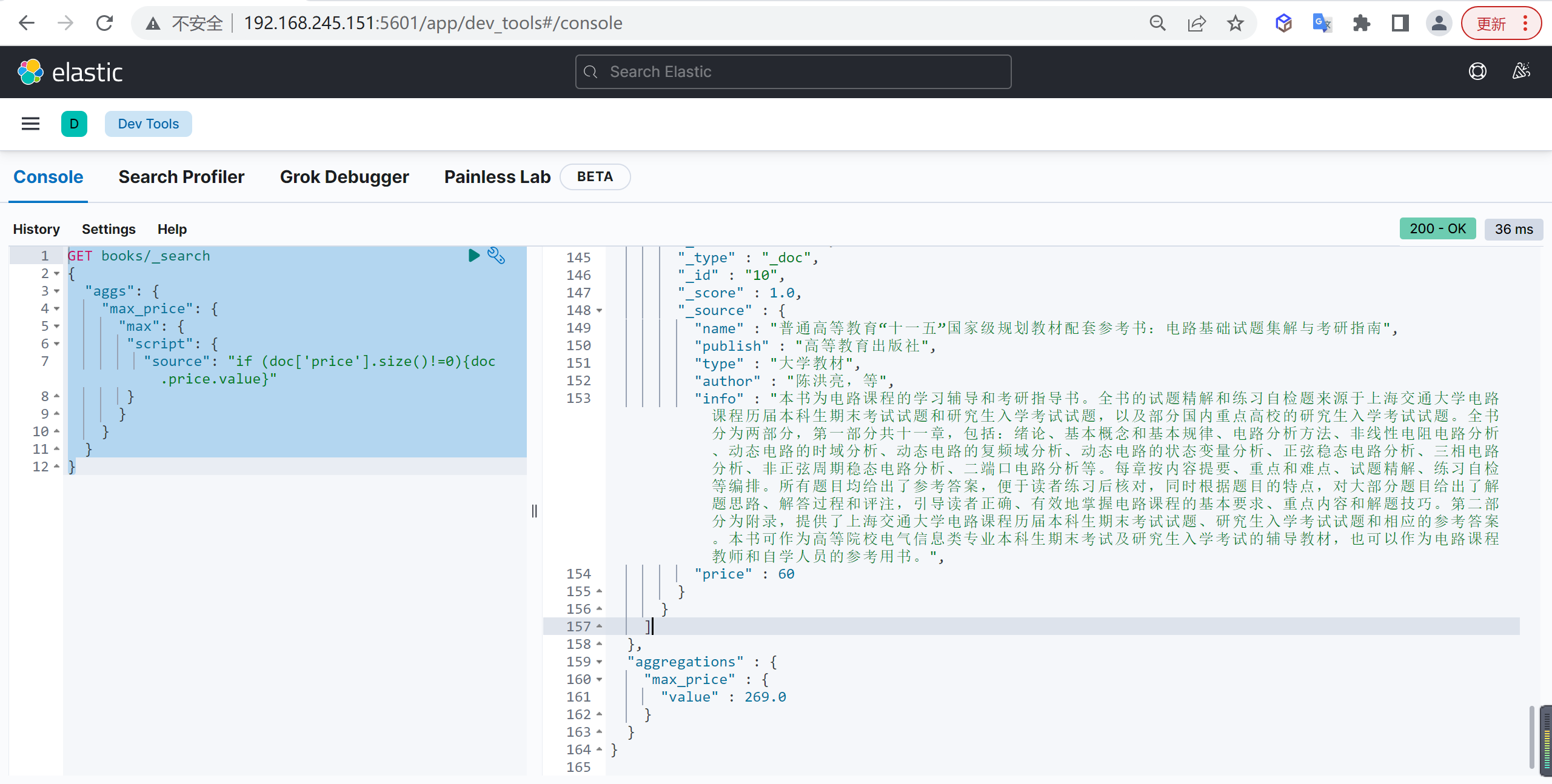
忽略问题文档
有时候我们需要排除不存在price字段的数据,我们可以使用script进行处理,
基本查询
可以先通过 doc['price'].size()!=0 去判断文档是否有对应的属性
1
2
3
4
5
6
7
8
9
10
11
12
| GET books/_search
{
"aggs": {
"max_price": {
"max": {
"script": {
"source": "if (doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
|
Min
统计最小值,用法和 Max 基本一致:
基本查询
1
2
3
4
5
6
7
8
9
10
11
| GET books/_search
{
"aggs": {
"min_price": {
"min": {
"field": "price",
"missing": 1000
}
}
}
}
|
忽略问题文档
1
2
3
4
5
6
7
8
9
10
11
12
| GET books/_search
{
"aggs": {
"min_price": {
"min": {
"script": {
"source": "if (doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
|
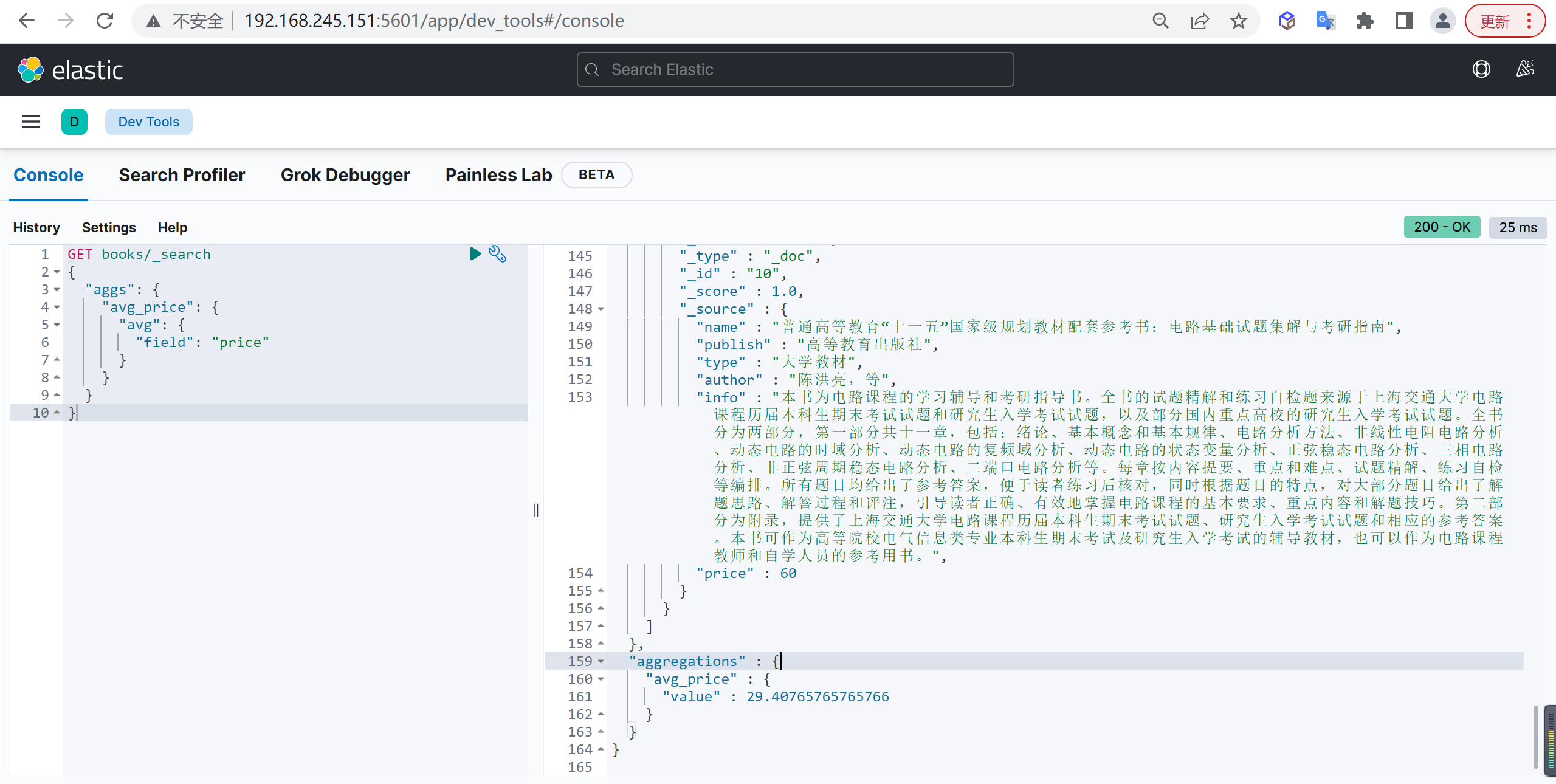
Avg
统计平均值
基本查询
我们统计数据价格的平均值
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
|
书籍的平均价格是29.4元
忽略问题文档
1
2
3
4
5
6
7
8
9
10
11
12
| GET books/_search
{
"aggs": {
"avg_price": {
"avg": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
|
Sum
对字段求合
基本查询
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"field": "price"
}
}
}
}
|
忽略问题文档
1
2
3
4
5
6
7
8
9
10
11
12
| GET books/_search
{
"aggs": {
"sum_price": {
"sum": {
"script": {
"source": "if(doc['price'].size()!=0){doc.price.value}"
}
}
}
}
}
|
Cardinality
Cardinality 聚合用于基数统计,类似于 MySQL 中的 distinct count(0),去重后再计数。
注意事项
ElasticSearch 中 text 字段类型是分析型,默认不允许进行聚合操作,如果有聚合操作的需求,可以考虑以下两种方式:
- 设置
text 字段类型的 fielddata 属性为 true。
- 将字段类型或者字段的子域在设置成
keyword 。
设置fielddata
设置 text 字段类型的 fielddata 属性为 true
重置索引
因为 books 索引已经存在,我们要先删除,再新建索引设置 fielddata,导入数据后再进行 Cardinality 统计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| DELETE books
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fielddata": true
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
|
重新导入数据
到 bookdata.json 文件目录下,用 cmd 命令行工具,重新导入数据:
1
| curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json
|
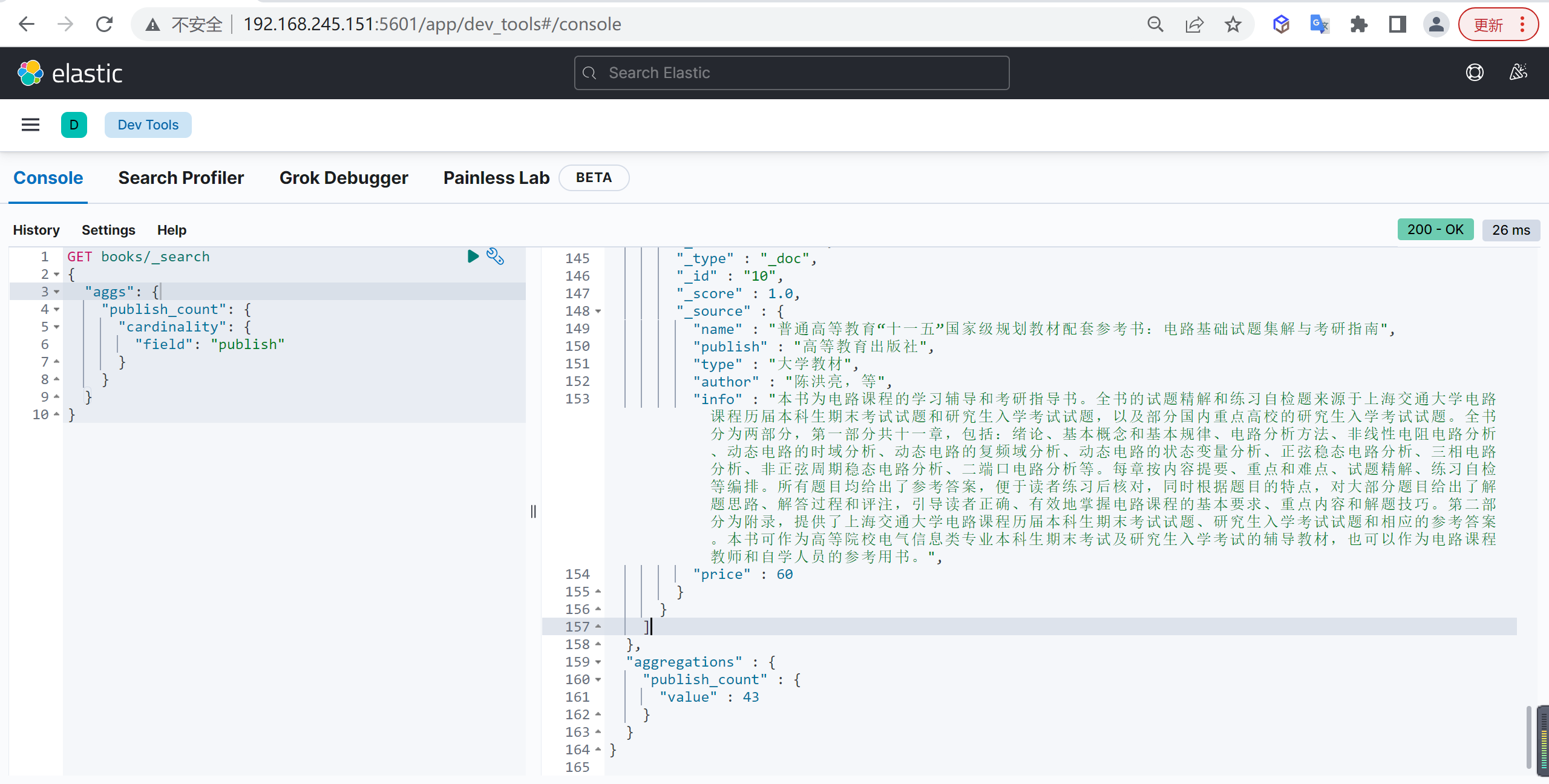
基础查询
现在就可以使用 cardinality 查询出版社的总数量
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}
|
查询出来的数据是43
主要事项
这种方式虽然可以进行聚合操作,但是无法满足精准聚合,因为 text 类型会进行分词。
而且 fielddata 是动态创建到内存中,如果文档很多时,可能有动态创建慢,占内存等问题,所以推荐使用下面第二种方式
设置keyword
将字段类型或者字段的子域设置成 keyword
重置索引
同样需要删除索引再新建,这次将 publish 字段子域设置成 keyword
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| DELETE books
PUT books
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"publish":{
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"size": {
"type": "keyword"
}
}
},
"type":{
"type": "text",
"analyzer": "ik_max_word"
},
"author":{
"type": "keyword"
},
"info":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "double"
}
}
}
}
|
重新导入数据
到 bookdata.json 文件目录下,用 cmd 命令行工具,重新导入数据:
1
| curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json
|
基础查询
再次使用 cardinality 查询出版社的总数量
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"publish_count": {
"cardinality": {
"field": "publish"
}
}
}
}
|
Stats
stats 表示基本统计聚合,可以同时返回 min、max、sum、count、avg 结果
基本查询
1
2
3
4
5
6
7
8
9
10
11
| GET books/_search
{
"aggs": {
"stats_agg": {
"stats": {
"field": "price"
}
}
}
}
|

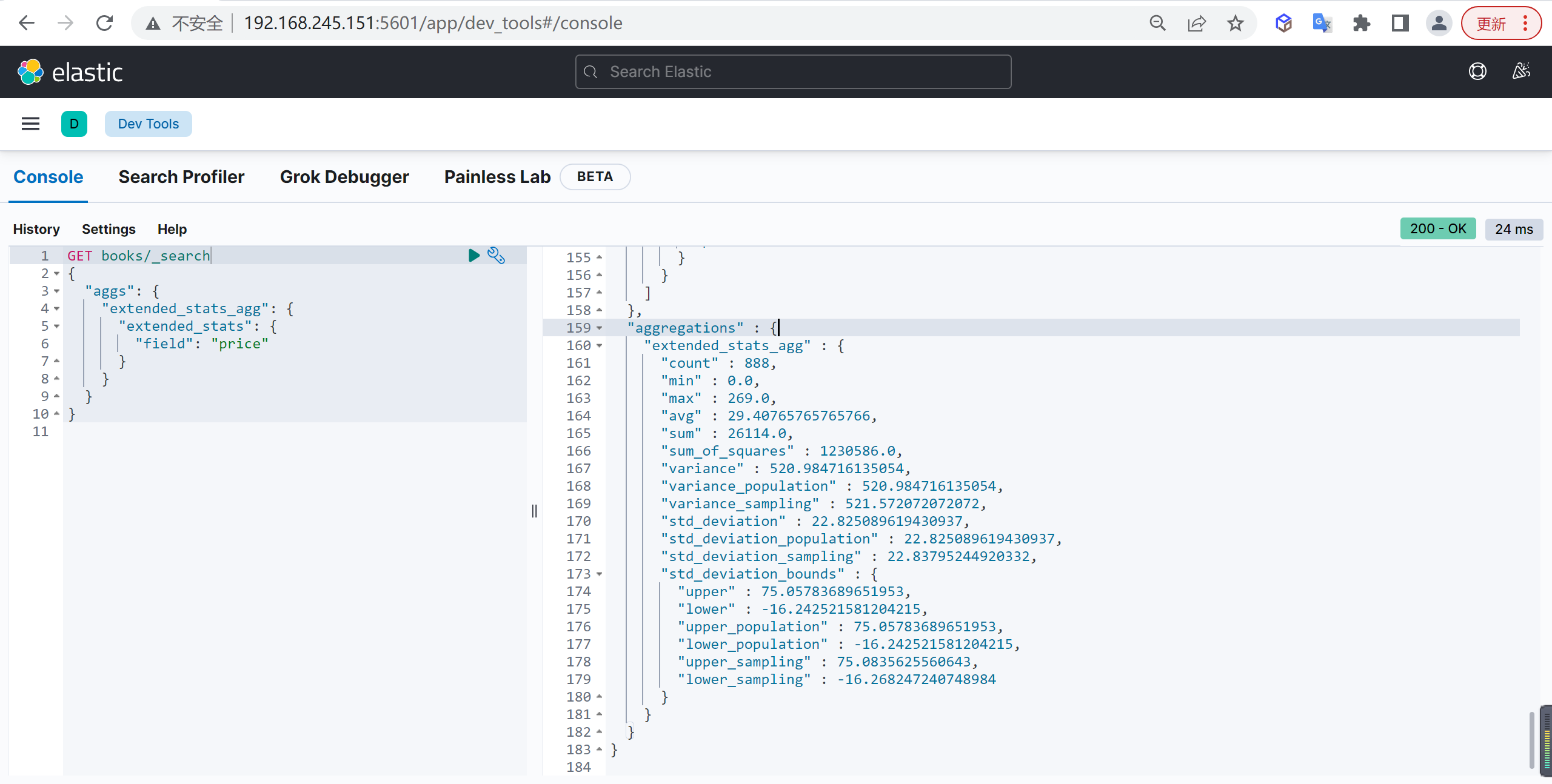
Extends Stats
Extends Stats 表示高级统计聚合,比 stats 聚合返回更多的内容
基本查询
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"extended_stats_agg": {
"extended_stats": {
"field": "price"
}
}
}
}
|
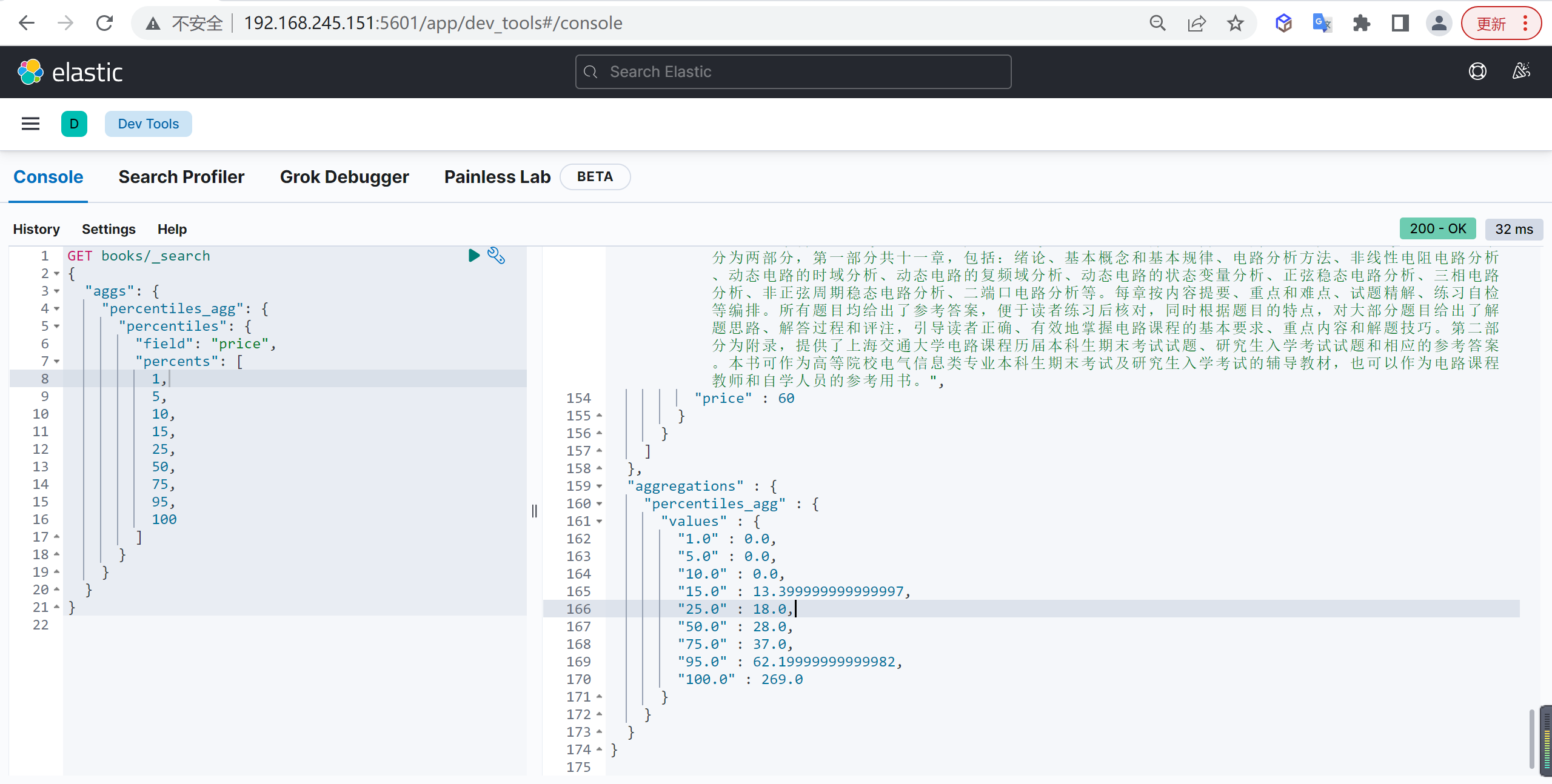
Percentiles
Percentiles 是百分位数值统计,运用于统计学中:将一组数据从小到大排序,并计算相应的累计百分位,则某一百分位所对应数据的值就称为这一百分位的百分位数。
基本查询
文字解释看起来比较难理解,还是拿书籍价格举例,分别看一下 25%、50%、75%、100% 这四个百分位上的书籍价格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| GET books/_search
{
"aggs": {
"percentiles_agg": {
"percentiles": {
"field": "price",
"percents": [
1,
5,
10,
15,
25,
50,
75,
95,
100
]
}
}
}
}
|
可以看到,中位数 50% 的书籍价格是 28 元,也就是说有一半的书籍价格比 28 元低,另一半比 28 元高,对应的 25%、75%、100% 也是类似。
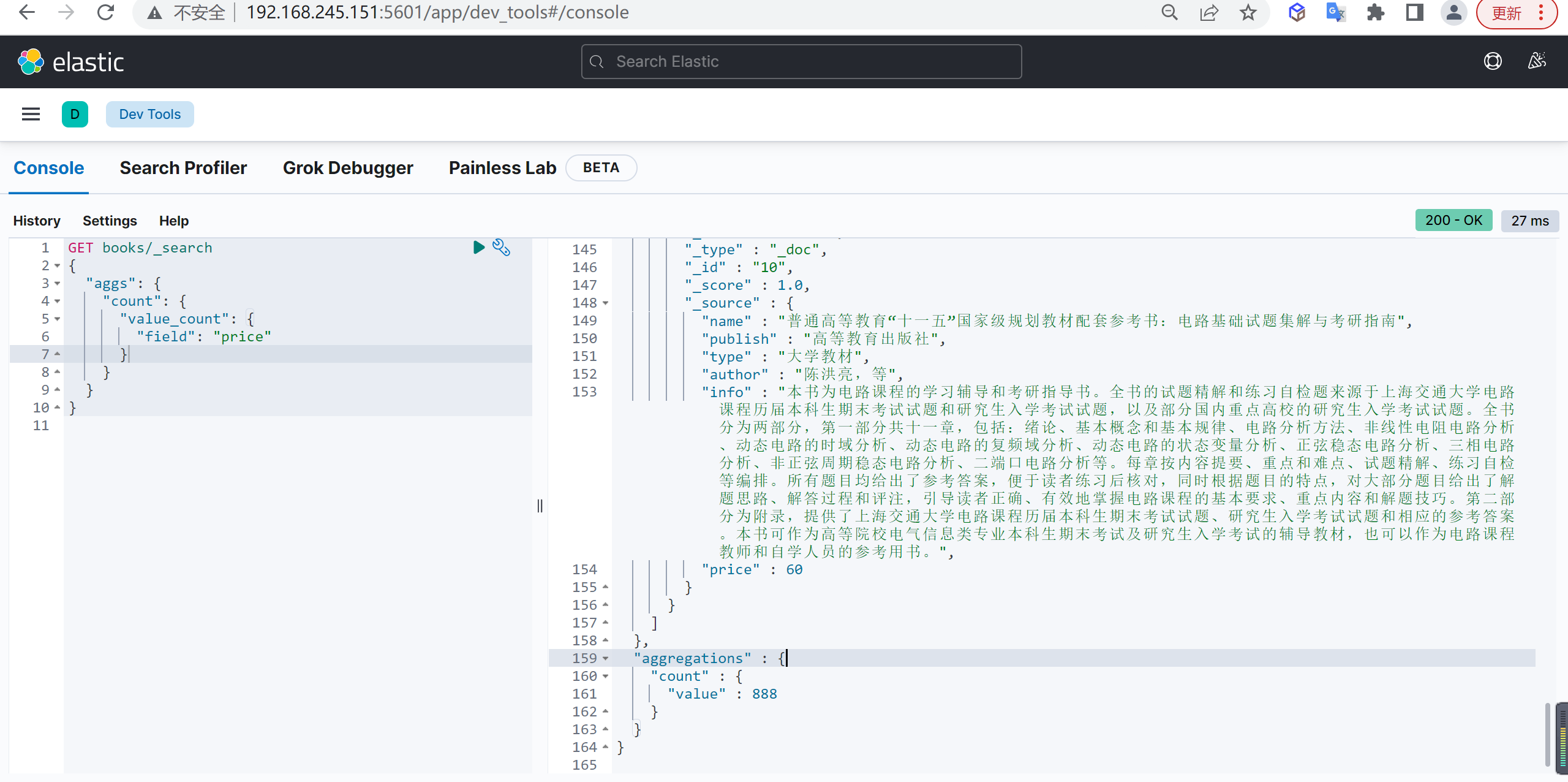
Value count
Value count 可以按照字段统计文档数量,该字段值为空 null 的文档会被丢弃
基本查询
1
2
3
4
5
6
7
8
9
10
11
| GET books/_search
{
"aggs": {
"count": {
"value_count": {
"field": "price"
}
}
}
}
|
桶聚合
Terms
Terms 用于分组聚合,例如,统计各个出版社出版的图书总数量
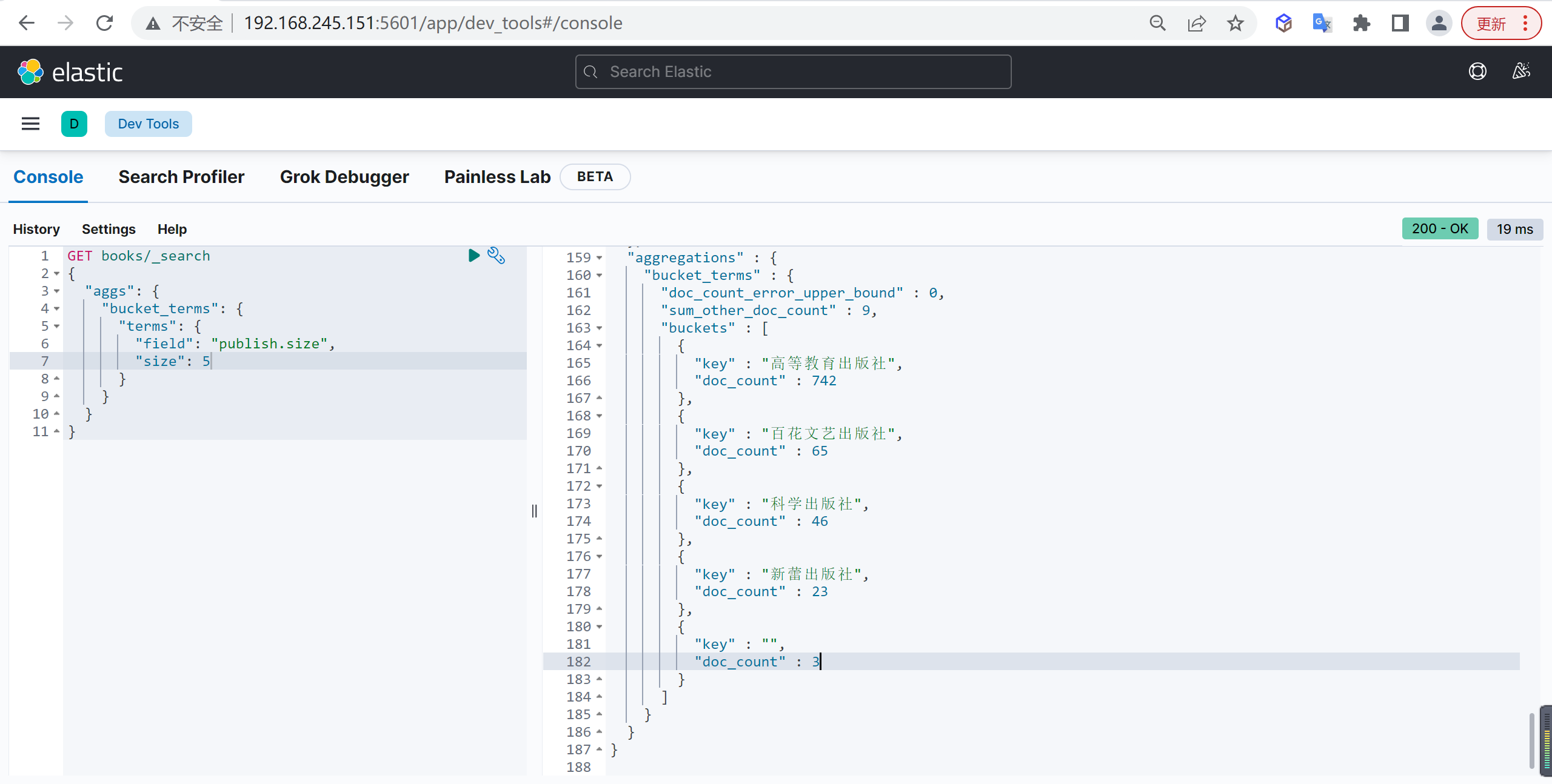
基本查询
统计各出版社图书总数量,并列出前五个
1
2
3
4
5
6
7
8
9
10
11
| GET books/_search
{
"aggs": {
"bucket_terms": {
"terms": {
"field": "publish.size",
"size": 5
}
}
}
}
|
terms 分组聚合不能作用于 text 类型,这里我们用的是 keyword 类型的子域 publish.size
价格统计
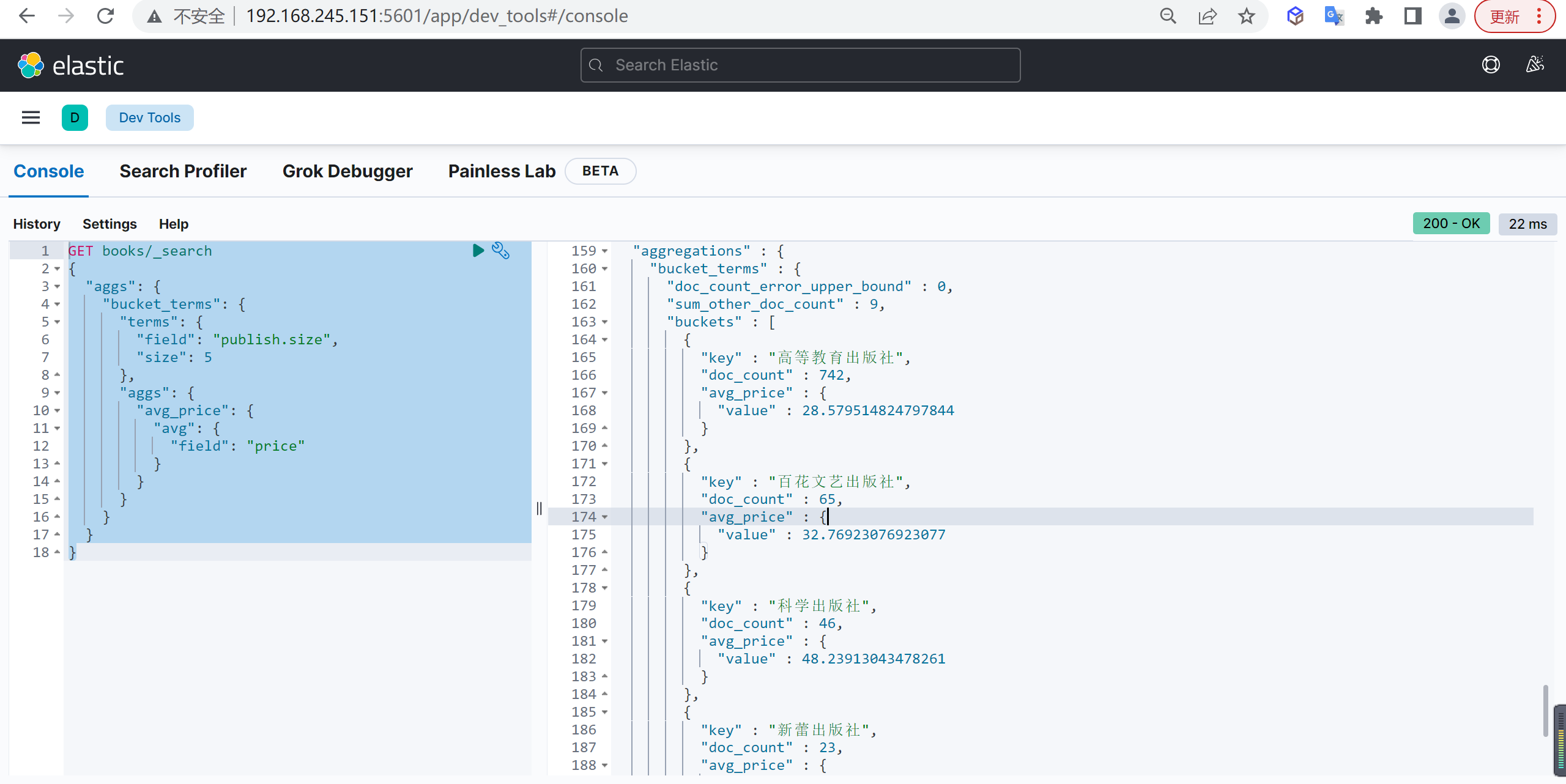
在 terms 分组聚合的基础上,还可以对每个桶进行指标聚合,统计不同出版社所出版的图书平均价格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| GET books/_search
{
"aggs": {
"bucket_terms": {
"terms": {
"field": "publish.size",
"size": 5
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
|
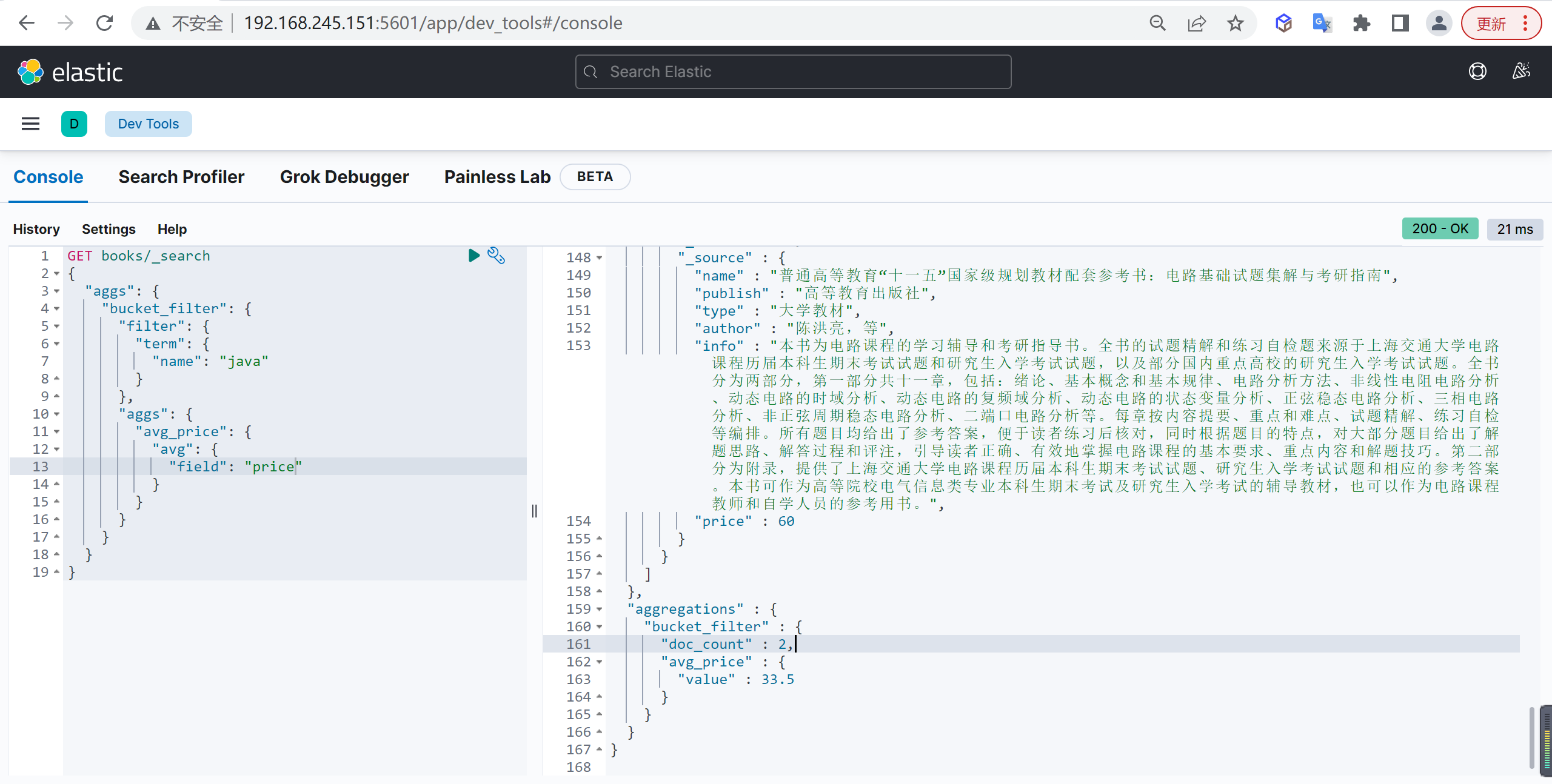
Filter
Filter 是过滤器聚合,可以将符合过滤器中条件的文档分到一个桶中,然后可以求其平均值
基本查询
例如查询书名中包含 java 的图书的平均价格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| GET books/_search
{
"aggs": {
"bucket_filter": {
"filter": {
"term": {
"name": "java"
}
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
|
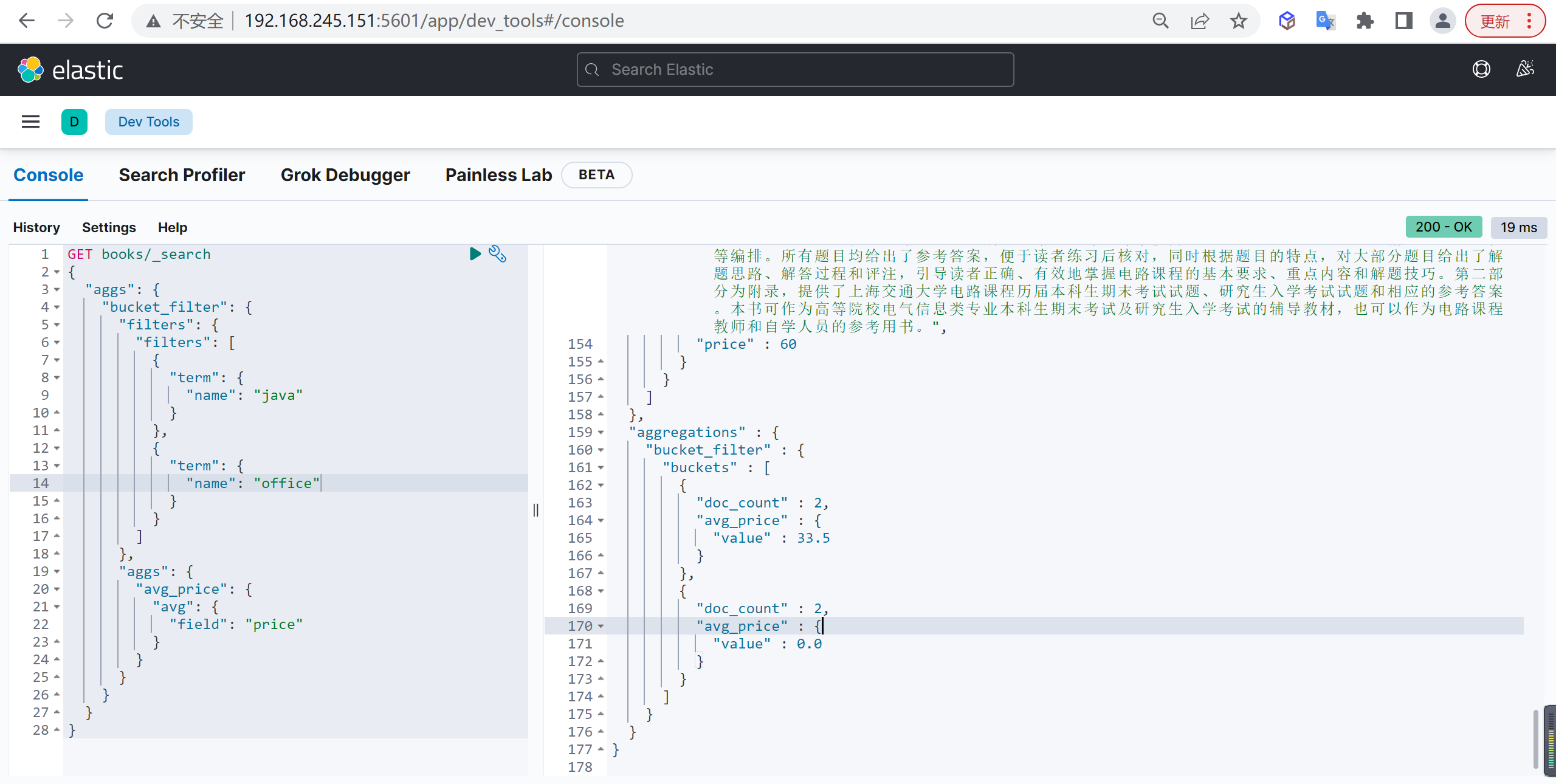
Filters
多过滤器聚合,过滤条件可以有多个
基本查询
例如查询书名中包含 java 或者 office 的图书的平均价格:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| GET books/_search
{
"aggs": {
"bucket_filter": {
"filters": {
"filters": [
{
"term": {
"name": "java"
}
},
{
"term": {
"name": "office"
}
}
]
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
|
Range
按照范围聚合,在某一个范围内的文档数统计
基本查询
例如统计图书价格在 0-50、50-100、100-150、150以上的图书数量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| GET books/_search
{
"aggs": {
"bucket_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 150
},
{
"from": 150
}
]
}
}
}
}
|
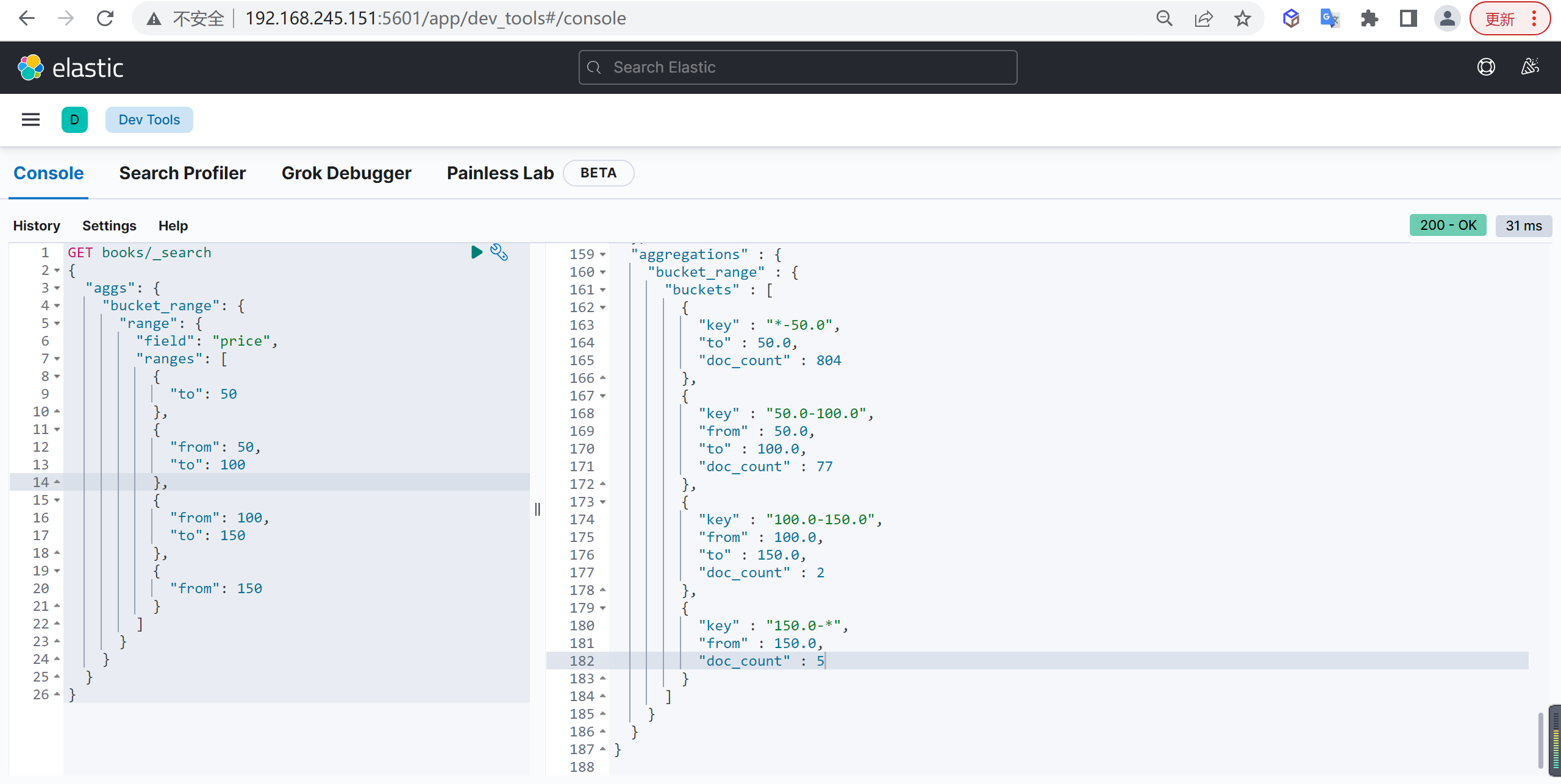
出版社统计
基于上面的架构聚集结果,在统计出来每一个分桶中出版社的数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| GET books/_search
{
"aggs": {
"bucket_range": {
"range": {
"field": "price",
"ranges": [
{
"to": 50
},
{
"from": 50,
"to": 100
},
{
"from": 100,
"to": 150
},
{
"from": 150
}
]
},
"aggs": {
"publish_size": {
"cardinality": {
"field": "publish.size"
}
}
}
}
}
}
|
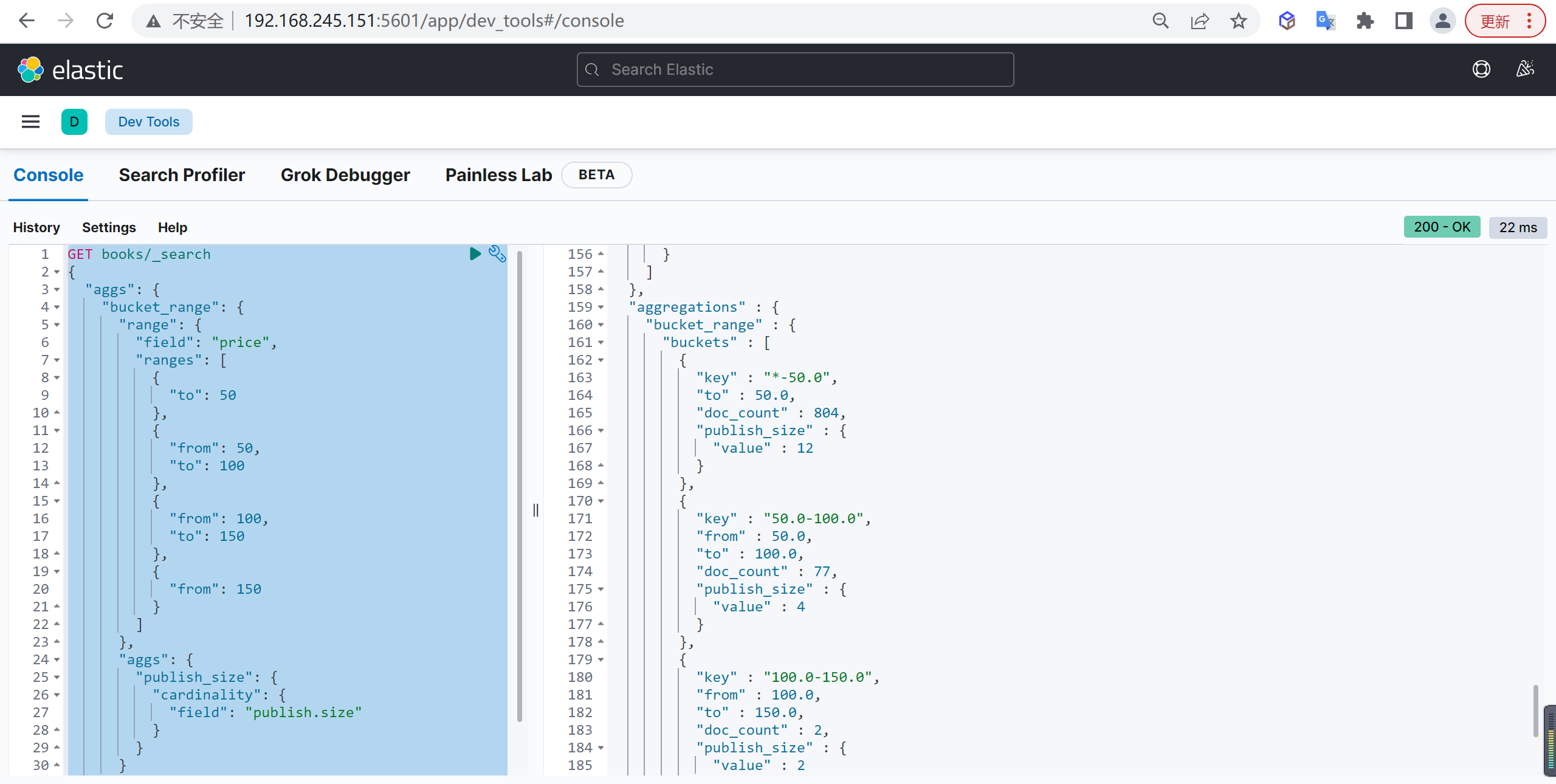
Date Range
ange 聚合和 Date Range 聚合都可以可以统计日期,后者的优势在于可以使用日期表达式
插入数据
首先造一些测试数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| PUT blog/_doc/1
{
"title":"java",
"date":"2018-12-30"
}
PUT blog/_doc/2
{
"title":"java",
"date":"2020-12-30"
}
PUT blog/_doc/3
{
"title":"java",
"date":"2022-10-30"
}
|
基本查询
统计一年前到一年后的微博数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| GET blog/_search
{
"aggs": {
"bucket_date_range": {
"date_range": {
"field": "date",
"ranges": [
{
"from": "now-10M/M",
"to": "now+1y/y"
}
]
}
}
}
}
|

Date Histogram
时间直方图聚
基本查询
例如统计各个月份的博客数量
1
2
3
4
5
6
7
8
9
10
11
| GET blog/_search
{
"aggs": {
"bucket_date_his": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
}
}
}
}
|
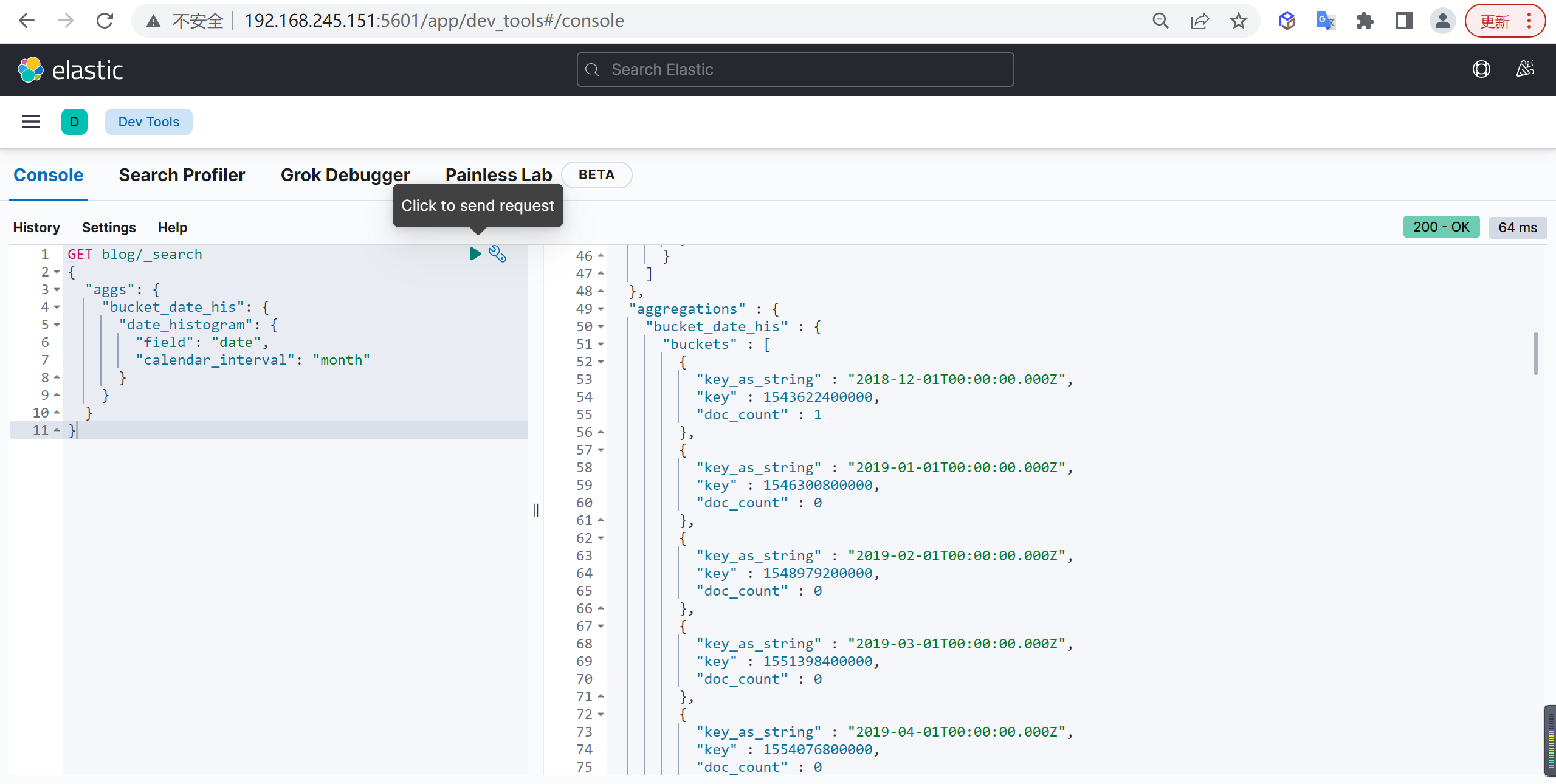
Missing
空值聚合
基本查询
统计所有没有 price 字段的文档:
1
2
3
4
5
6
7
8
9
10
| GET books/_search
{
"aggs": {
"bucket_missing": {
"missing": {
"field": "price"
}
}
}
}
|
Children
可以根据父子文档关系进行分桶
基本查询
查询子类型为 student 的文档数量
1
2
3
4
5
6
7
8
9
10
11
| GET stu_class/_search
{
"aggs": {
"bucket_children": {
"children": {
"type": "student"
}
}
}
}
|
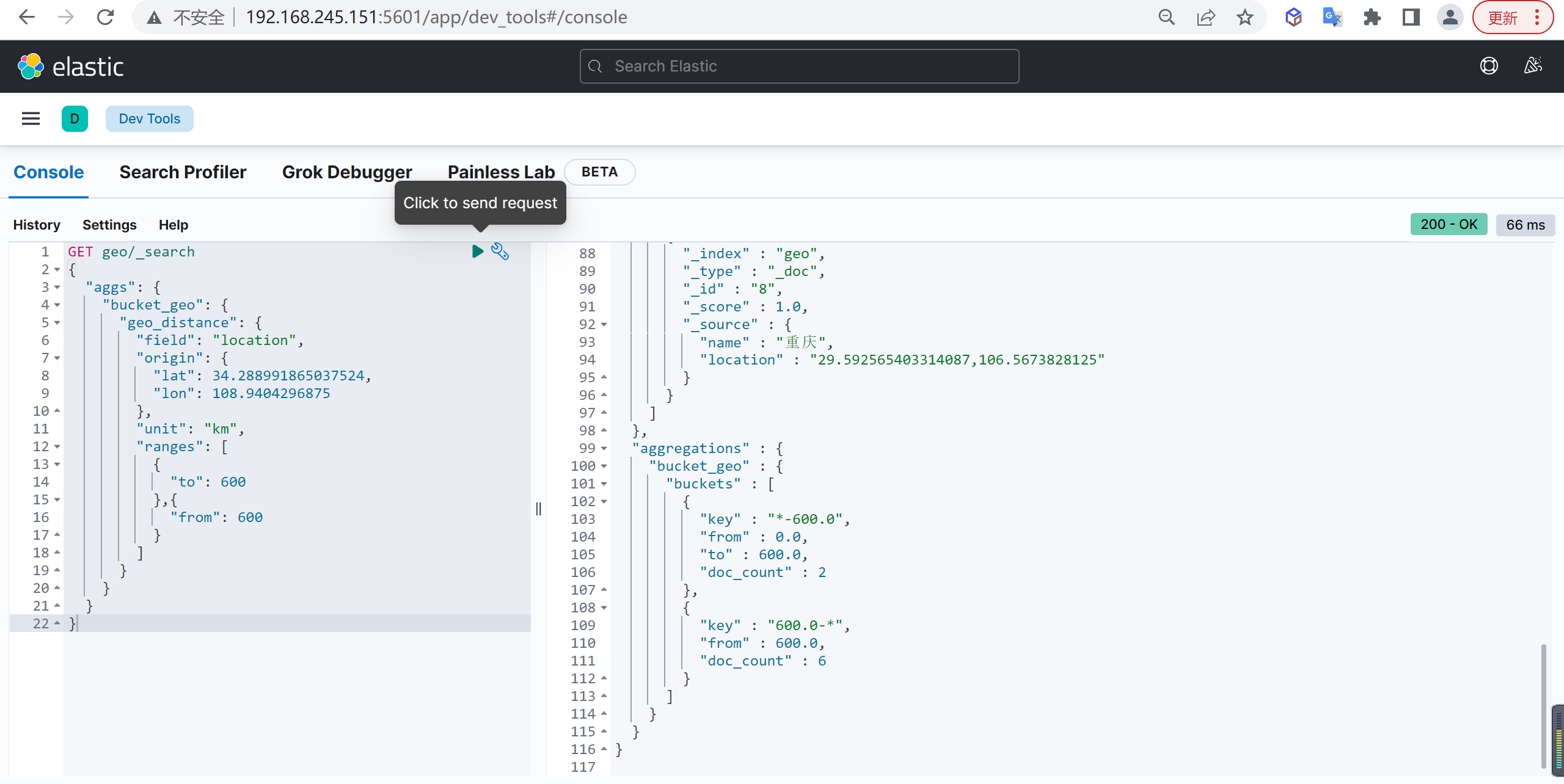
Geo Distance
对地理位置数据做统计
基本查询
例如分别统计 (34.288991865037524,108.9404296875) 坐标方圆 600KM 和 超过 600KM 的城市数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| GET geo/_search
{
"aggs": {
"bucket_geo": {
"geo_distance": {
"field": "location",
"origin": {
"lat": 34.288991865037524,
"lon": 108.9404296875
},
"unit": "km",
"ranges": [
{
"to": 600
},{
"from": 600
}
]
}
}
}
}
|
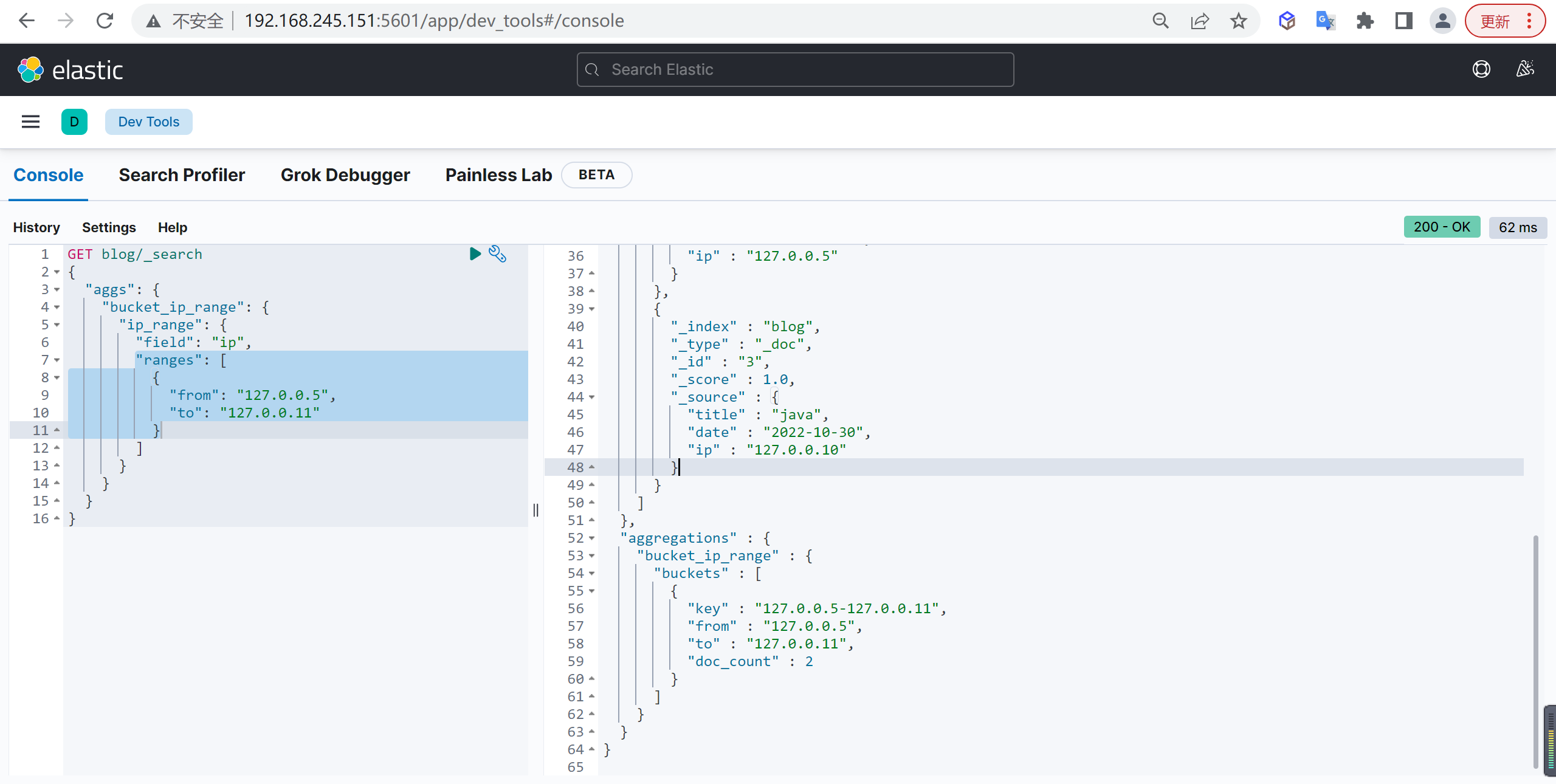
IP Range
IP 地址范围聚合
准备数据
之前的 blog 索引没有设置 ip 字段,删掉重新设置一下
重置索引
1
2
3
4
5
6
7
8
9
10
11
12
| DELETE blog
PUT blog
{
"mappings": {
"properties": {
"ip": {
"type": "ip"
}
}
}
}
|
插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| PUT blog/_doc/1
{
"title":"java",
"date":"2018-12-30",
"ip":"127.0.0.1"
}
PUT blog/_doc/2
{
"title":"java",
"date":"2020-12-30",
"ip":"127.0.0.5"
}
PUT blog/_doc/3
{
"title":"java",
"date":"2022-10-30",
"ip":"127.0.0.10"
}
|
基本查询
例如查询指定 IP 地址的博客数量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| GET blog/_search
{
"aggs": {
"bucket_ip_range": {
"ip_range": {
"field": "ip",
"ranges": [
{
"from": "127.0.0.5",
"to": "127.0.0.11"
}
]
}
}
}
}
|
管道聚合
管道聚合相当于在之前聚合的基础上,进行再次聚合
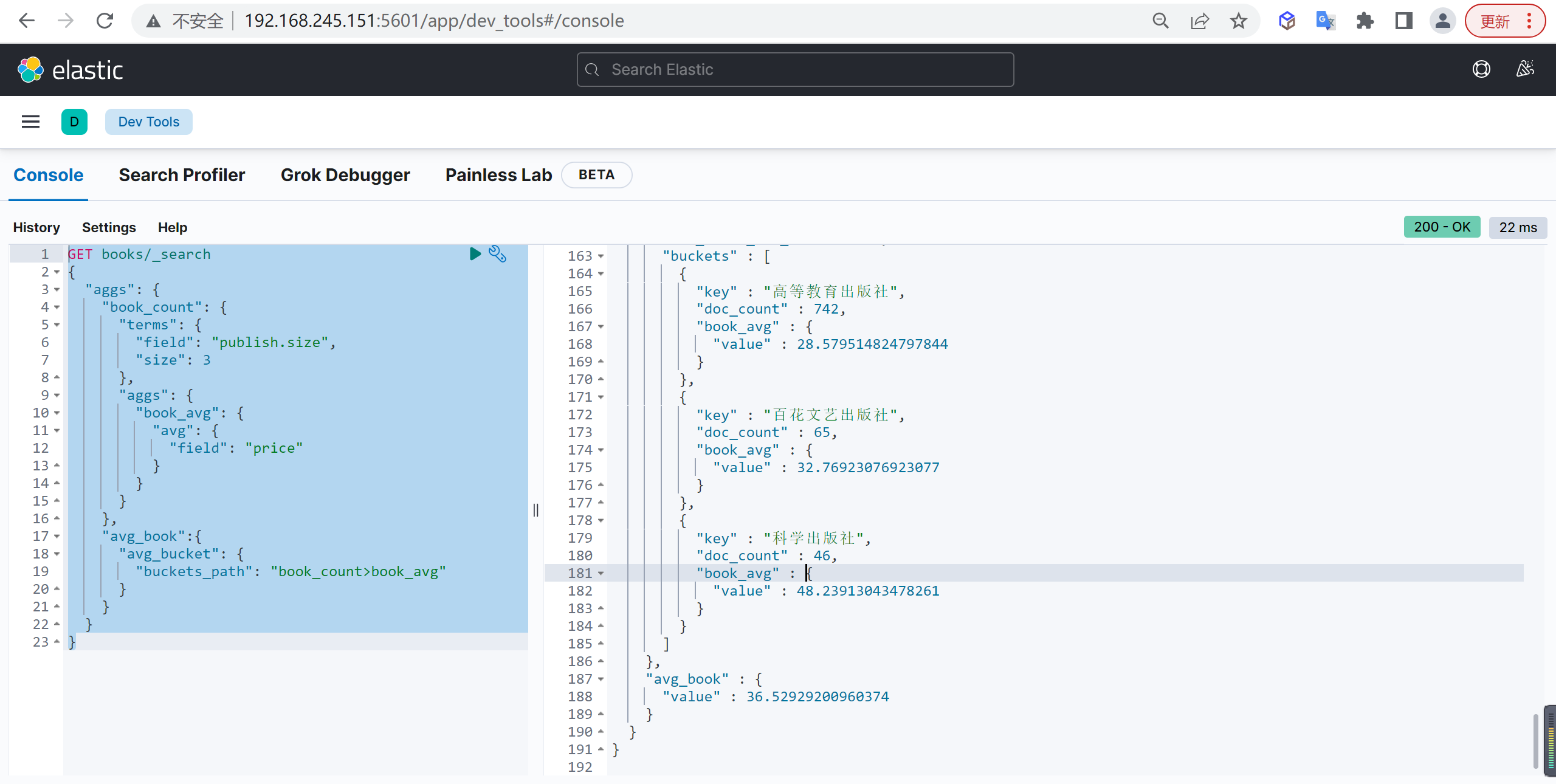
Avg Bucket
计算聚合平均值
基本查询
统计每个出版社所出版图书的平均值,然后再统计所有出版社的平均值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"avg_book":{
"avg_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|
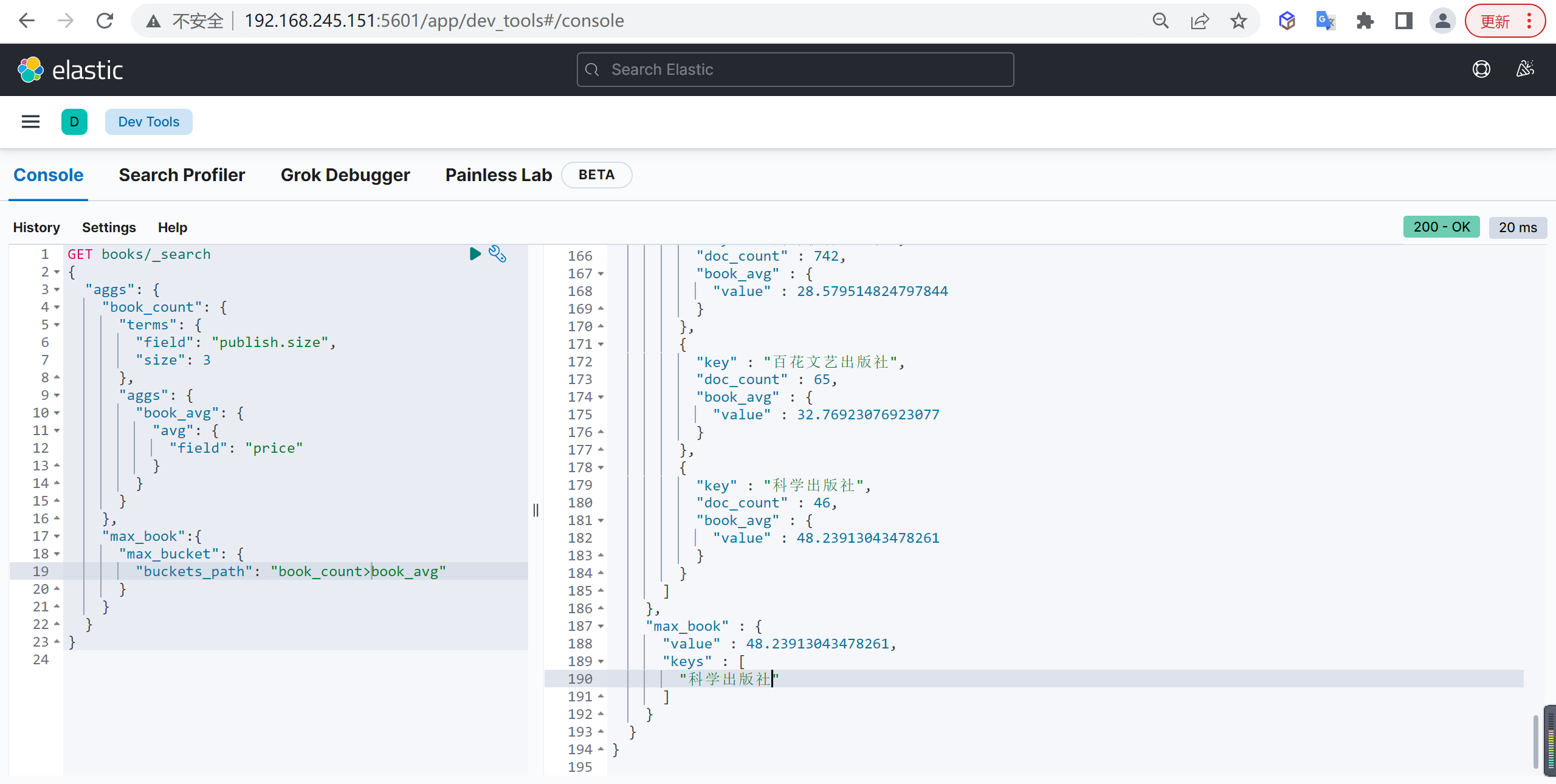
Max Bucket
计算聚合最大值
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值中的最大值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"max_book":{
"max_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|
Min Bucket
计算聚合最小值
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值中的最小值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"min_book":{
"min_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|
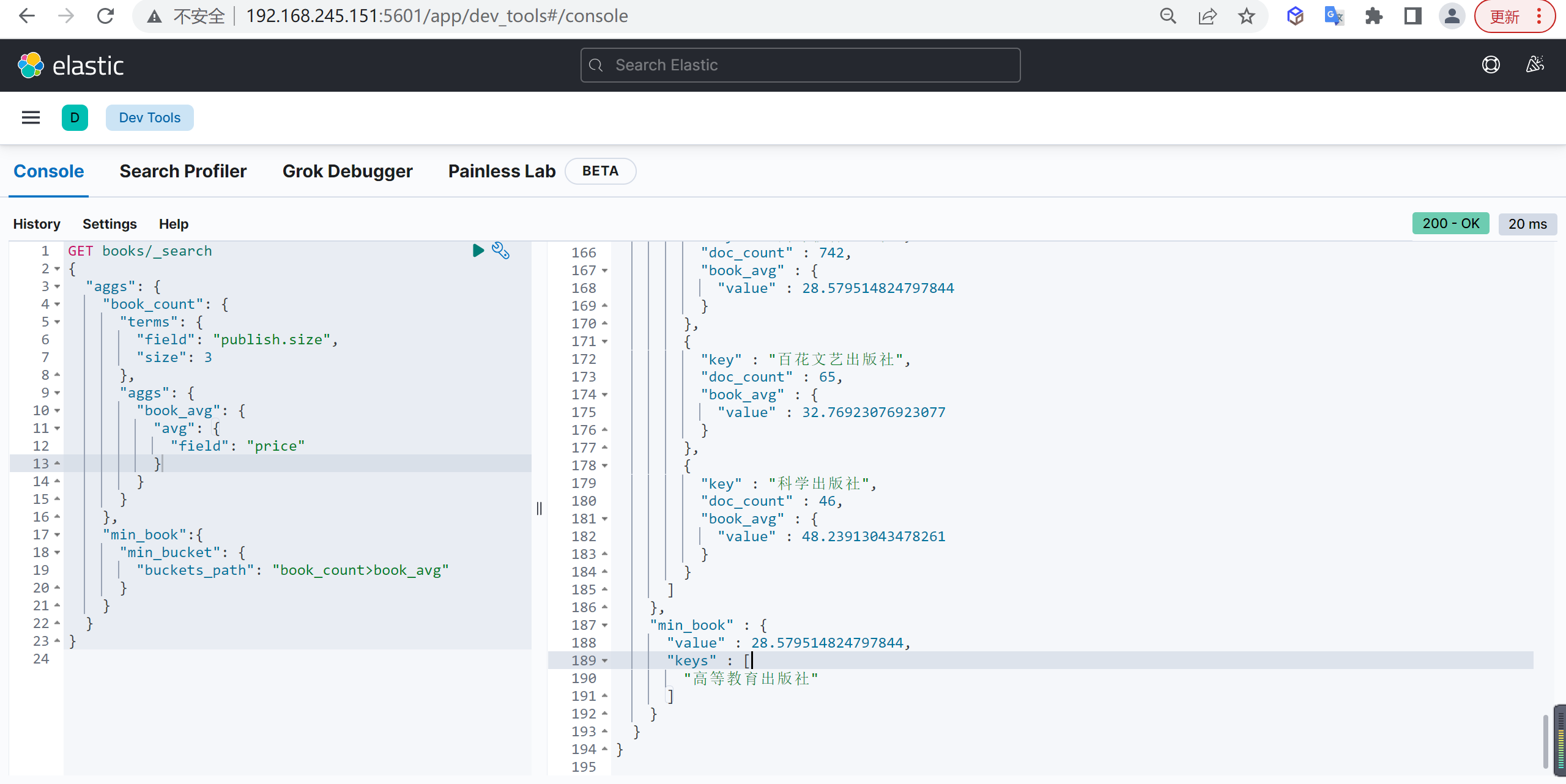
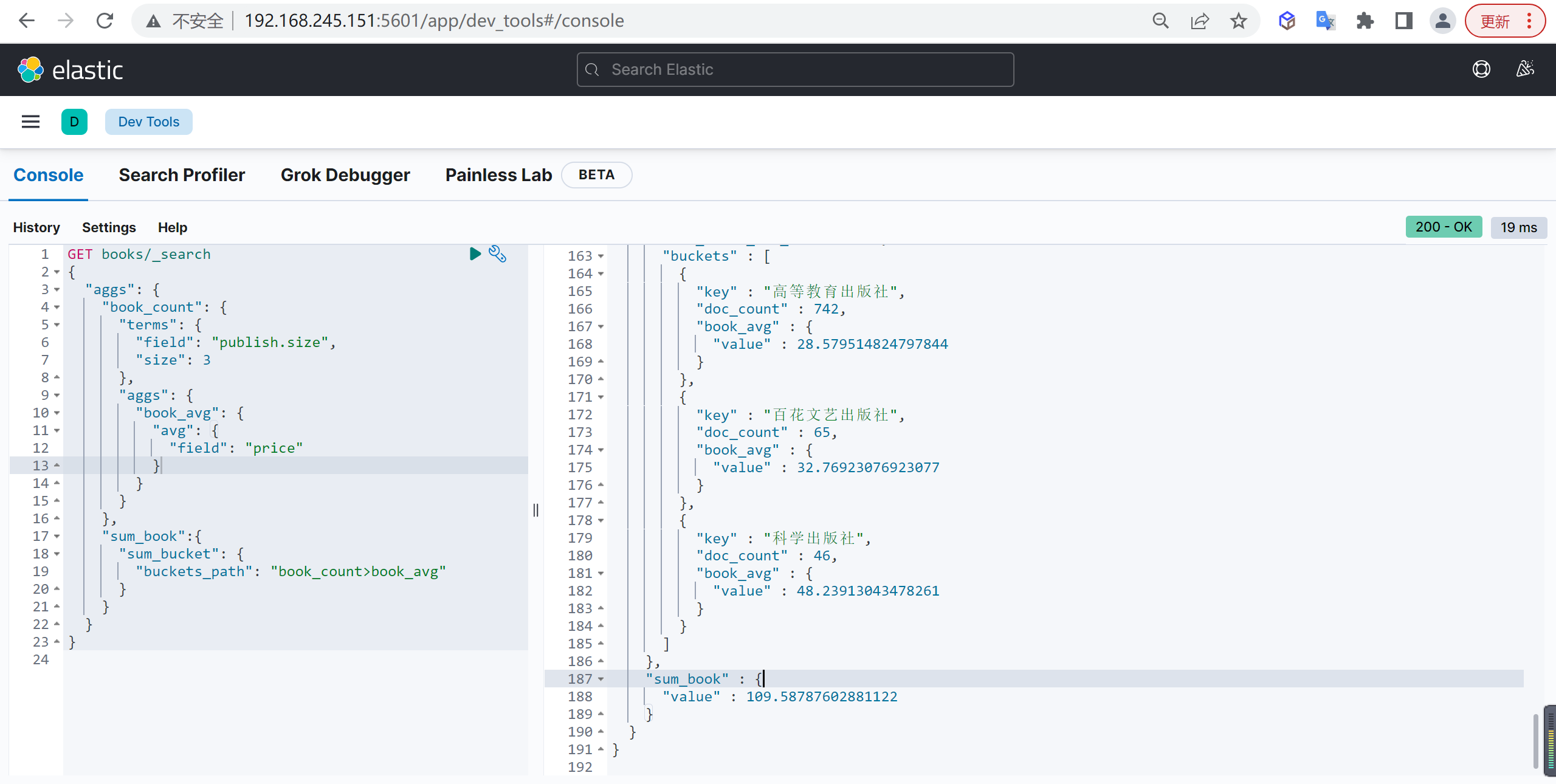
Sum Bucket
计算聚合累加
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值之和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"sum_book":{
"sum_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|
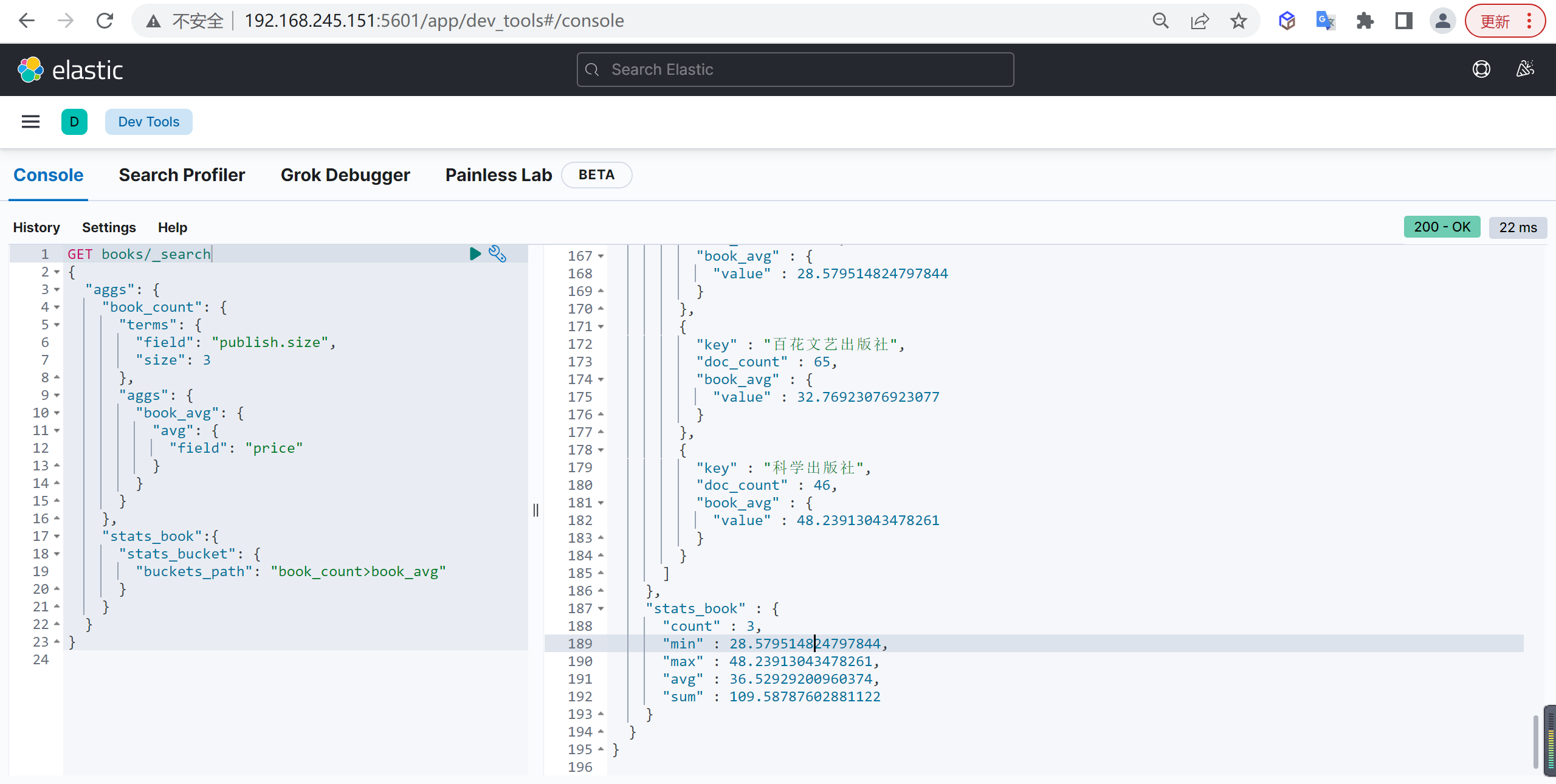
Stats Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"stats_book":{
"stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|
Extended Stats Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的各种数据,比 Stats Bucket 统计多了一些方差之类的数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"extended_book":{
"extended_stats_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|

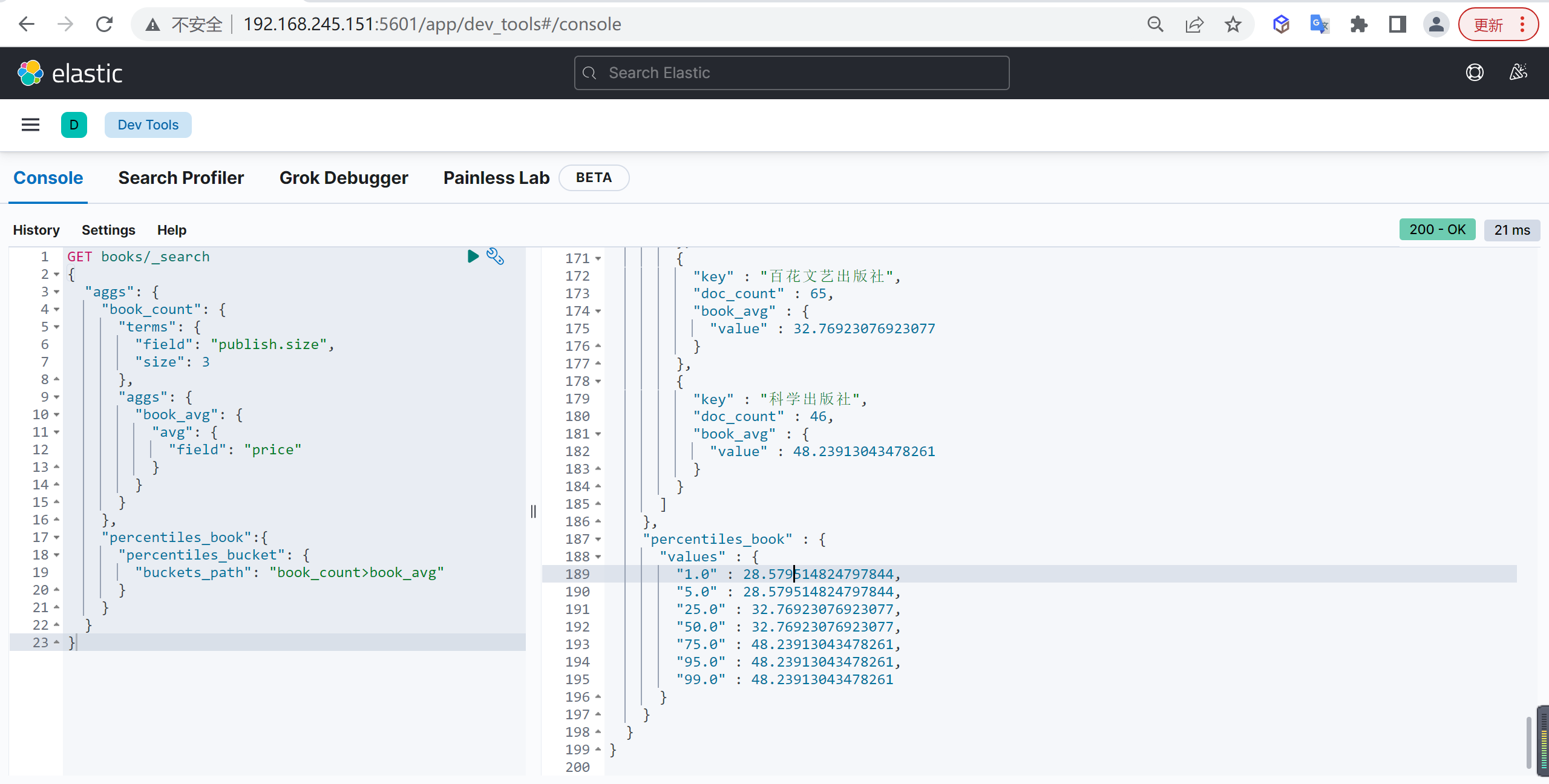
Percentiles Bucket
基本查询
统计每个出版社所出版图书的平均值,然后再统计平均值的百分位数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET books/_search
{
"aggs": {
"book_count": {
"terms": {
"field": "publish.size",
"size": 3
},
"aggs": {
"book_avg": {
"avg": {
"field": "price"
}
}
}
},
"percentiles_book":{
"percentiles_bucket": {
"buckets_path": "book_count>book_avg"
}
}
}
}
|