ElasticSearch 相关查询

相关性查询概述
相关性算分描述了一个文档和查询语句匹配的程度,es会对每个匹配查询条件的结果进行算分打分的本质是排序,将相关性高的文档排在最前面
在全文检索]中,检索结果与查询条件的相关性是一个极为重要的问题,优秀的全文检索引擎应该将那些与查询条件相关性高的文档排在最前面。想象一下,如果满足查询条件的文档成千上万,让用户在这些文档中再找出自己最满意的那一条,这无异于再做一次人工检索,用户一般很少会有耐心在检索结果中翻到第3页,所以处理好检索结果的相关性对于检索引擎来说至关重要。
Google公司就是因为发明了Page Rank算法,巧妙地解决了网页检索结果的相关性问题,才在众多搜索公司中迅速崛起。
相关性问题有两方面问题要解决,一是如何评价单个查询条件的相关性,二是如何将多个查询条件的相关性组合起来。
什么是相关性评分
全文检索与数据库查询的一个显著区别,就是它并不一定会根据查询条件做完全精确的匹配。
除了模糊查询以外,全文检索还会根据查询条件给文档的相关性打分并排序,将那些与查询条件相关性高的文档排在最前面,相关性( Relevance)或相似性(Similarity)是指两个事物间相互关联的程度,在检索领特指检索请求与检索结果之间的相关程度。
在 Elaticsearch返回的每条结果中都会包含一个_score字段,这个字段的值就是当前文档匹配检索请求的相关性评分,我们也可以称为相关度。
解决相关性问题的核心是计算相关度的算法和模型,相关度算法和模型是全文检索文章最重要的技术之一。相关度算法和相关度模型并非完全相同的概念,相关度模型可以认为是具有相同理论基础的算法集合,所以在实际应用时都是指定到具体的相关度算法,相关度模型则是从理论层面对相关度算法的归类。
相关度模型
Elasticsearch支持多种相关度算法,它们通过类型名称来标识,包括boolean、BM25、DFR等等很多,这些算法分别归属于几种不同的理论模型,它们是布尔模型、向量空间模型、概率模型、语言模型等。
布尔模型
布尔模型( Boolean Model)是最简单的相关度模型,最终的相关度只有1或0两种
如果检索中包含多个查询条件,则查询条件之间的相关度组合方式取决它们之间的逻辑运算符,即以逻辑运算中的与、或、非组合评分,文档的最终评分为1时会被添加到检索结果中,而评分为0时则不会出现在检索结果中,这与使用SQL语句查询数据库有些类似,完全根据查询条件决定结果,非此即彼,在Elasticearch支持的相关度算法中,boolean算法即采用布尔模型,有些地方也部分地采用了布尔模型。
向量空间模型
向量空间模型(Vector Space Mode)组合多个相关度时采用的是基于向量的算法
在向量空间模型中,多个查询条件的相关度以向量的形式表示,向量实际上就是包含多个数的一维数组,例如[1,2, 3,4, 5, 6]就是一个6维向量,其中每个数字都代表一个查询条件的相关度。
文档对于n个查询条件会形成一个n维的向量空间,如果定义1个查询条件最佳匹配的n维向量,那么与这个向量越接近则相关度越高,从向量的角度来看,就是两个向量之间的夹角越小相关度越高,所以n个相关度的组合就转换为向量之间夹角的计算。
简单理解,可以只考虑一个二维向量,也就是查询条件只有两个,这样就可以将两个相关度映射到二维坐标图的X轴和Y轴上,假设两个查询条件权重相同,那么最佳匹配值就可以设置为[1, 1],如果某文档匹配了第一个条件,部分地匹配了第二个条件,则该文档的向量值为[1, 0.2],将这两个向量绘制在二维坐标图中,就得到了它们的夹角。
对于多维向量来说,线性代数提供了余弦近似度算法,专门用于计算两个多维向量的夹角。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性,0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间,例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
概率模型
概率模型是基于概率论构建的模型,BM25、DFR、DFI都属于概率模型中的一种实现算法,背后有着非常严谨的概率理论依据。
以其中最为流行的BM25为例,它背后的概率理论是贝叶斯定理,而这个定理在许多领城中都有广泛的应用,BM25法将检索出来的文档(D)分为相关文档(R)和不相关文档(NR)两类,使用P(R|D)代表文档属于相关文档的概率,而使用P(NR|D)表示文档属于不相关文档的概率,则当P(R|D)>P(NR|D)时认为这个文档与用户查询相关。根据贝叶斯公式将P(R|D)>P(NR|D)转换为对某个比值的计算。在此基础上再进行一此转换,就可以得到不同的相关度算法。
语言模型
语言模型最早并不是应用于全文检索领域,而是应用于语音识别、机器翻译、拼写检查等领域。
在全文检索中,语言模型为每个文档建立不同的计算模型,用以判断由文档生成某一查询条件的概率是多少,而这个概率的值就可以认为是相关度。可见,语言模型与其他检索模型正好相反,其他检索模型都是从查询条件查找满足条件的文档,而语言模型则是根据文档推断可能的查询条件。
相关度算法
下面我们看一下常见的几种相关度算法
TF/IDF
对于一篇几百字几千字的文章,如何生成足以准确表示该文章的特征向量呢?
就像论文一样,摘要、关键词毫无疑问就是全篇最核心的内容,因此,我们要设法提取一篇文档的关键词,并对每个关键词计算其对应的特征权值,从而形成特征向量,这里涉及一个非常简单但又相当强大的算法,即TF-IDF算法。
TF/IDF实际上两个影响相关度的因素,即TF和IDF,其中TF是词项频率简称词频,指一个词项在当前文档中出现的次数,而IDF则是逆向文档频率,指词项在所有文档中出现的次数。
Elasticsearch提供的几种算法中都或多或少有TF/IDF的思想,例如BM25算法虽然是通过概率论推导而来,但最终的计算公式与TF/IDF在本质上也是一致的。
词频 - TF
词频,英文缩写为TF,英文全写为Term Frequency,词频用于描述
检索词在一篇文档中出现的频率,即:检索词出现的次数除以文档的总字数。
衡量一条查询语句和结果文档相关性的简单方法:简单地将搜索语句中的每一个词的TF进行相加。
例如,我的苹果,即为:TF(我) + TF(的) + TF(苹果)。
停用词,英文名为Stop Word,例如我的苹果中的的在文档中可能出现很多次,但贡献的相关度却几乎没有用处,因此不应该考虑他们的词频。
逆文档频率 - IDF
相对于逆文档频率,我们先来说说文档频率。
文档频率,英文缩写为DF,英文全写为Document Frequency,用于检索词在所有文档中出现的频率。
苹果在相对较少的文档中出现我在相对较多的文档中出现的在大量的文档中出现
逆文档频率,英文全写为:Inverse Document Frequency,简单说也就是:
log(全部文档数 / 检索词出现过的文档总数)
TF-IDF
TF-IDF的本质就是将
TF求和变成了加权求和,TF(我)*IDF(我)+TF(的)*IDF(的)+TF(苹果)*IDF(苹果)
| 出现的文档数 | 总文档数 | IDF | |
|---|---|---|---|
| 我 | 5亿 | 10亿 | log(2) = 1 |
| 的 | 10亿 | 10亿 | log(1) = 0 |
| 苹果 | 200万 | 10亿 | log(500) = 8.96 |
可见,在使用TF/IDF计算评分时必须要用到词项在文档中出现的频率,即词频,默认情况下文档text类型字段在编入索引时都会记录词频,Elasticsearch中的classic算法实际上是使用Lucene的实用评分函数(Practical Scoring Function),这个评分函数结合了布尔模型、TF/IDF和向量空间模型来共同计算分值,该算法是早期Elasticsearch运算相关度的算法,现在已经改为BM25了。
BM25
BM25是Best Match25的简写,由于最早应用于一个名为Okapi的系统中,所以很多文献中也称之为 Okapi BM25
BM25算法被认为是当今最先进的相关度算法之一,Elasticsearch文档字段的默认相关度算法就是采用BM25,它属于概率模型,依据贝叶斯公式,经过一系列的严格推导以后,得出了一个关于IDF的公式
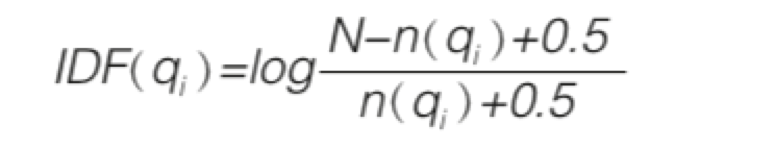
同时在这个基础上,最终的公式上加入了对TF、当前文档的长度、词频饱和度、长度归一化等因素的考虑:

词频饱和度
所谓词频饱和度指的是当词频超过一定数量之后,它对相关度的影响将趋于饱和
换句话说,词频10次的相关度比词频1次的分值要大很多,但100次10次之间差距就不会那么明显了。在BM25算法中,控制词频饱和度的参数是k1,默认值为1.2,参数k1的值越小词频对相关度的影响就会越快趋于饱和,而值越大词频饱和度变化越慢。
举例来说,如果将k1设置为1,词频达到10时就会趋于饱和;而当k1设置为100时词频在100时才会趋于饱和,一般来说k1的取值范围为[1.2, 2.0]。
长度归一化
一般来说, 查询条件中的词项出现在较短的文本中,比出现在较长的文本中对结果的相关性影响更大。
举例来说,如果一篇文章的标题中包含elasticsearch,那么这篇文章是专门介绍elasticsearch的可能性比只在文章内容中出现elasticsearch的可能要高很多,但这种比较其实是建立在两个不同的字段上,而在实际检索时往往是针对相同的字段做比较。
比如在两篇文章的标题中都出现了elasticsearch,那么哪一篇文章的相关度更高呢?
BM25针对这种情况对文本长度做了所谓的归一化处理,即考虑当前文档字段的文本长度与所有文档的字段平均长度的比值,而这个比值就是长度归一化因素。
为了控制长度归一化对相关度的影响,在长度归一化中加了一个控制参数b,这个值的取值范围为[0.0, 1.0],取值0.0时会禁用归一化,而取值1.0则会完全启用归一化,默认值为0. 75。
和TF/IDF
下面我们看看BM25和TF/IDF的区别
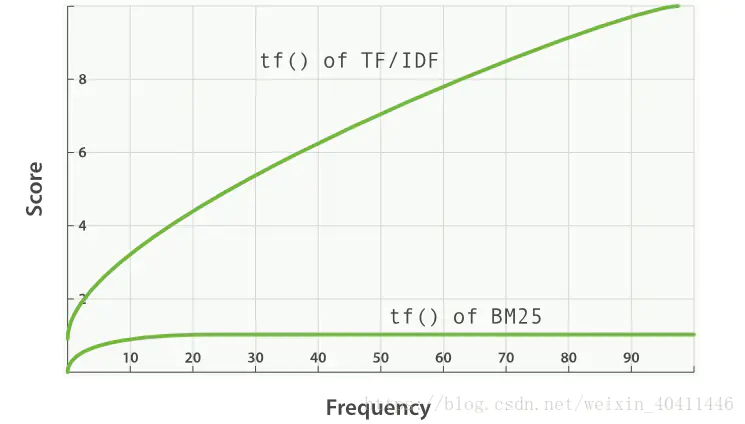
- 从Elasticsearch5.0开始,默认算法由TF-IDF改为BM25
- 和经典的TF-IDF相比,当TF无限增加时,BM25计算的相关性分数会趋于一个固定数值。
相关性查询
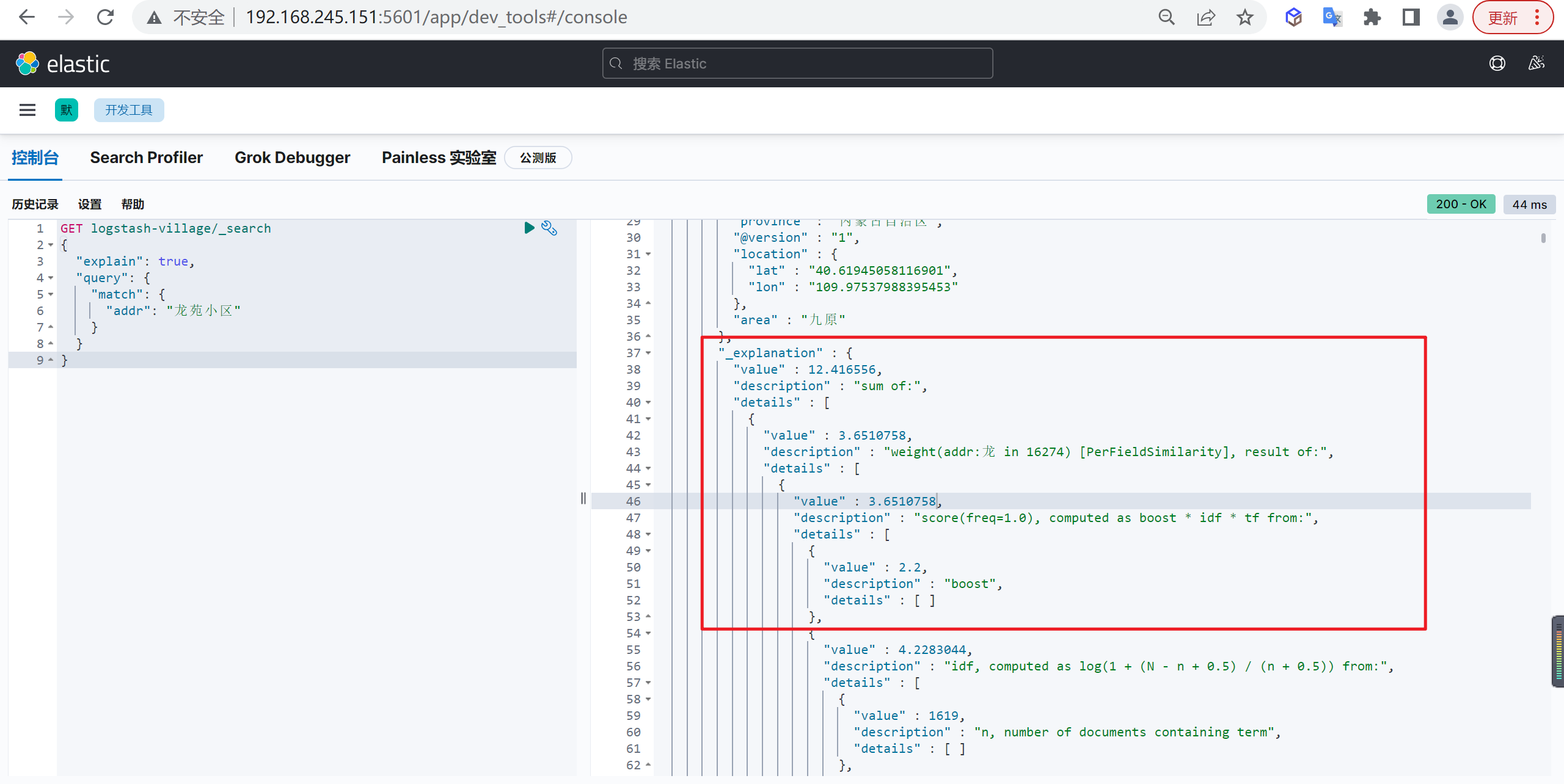
查看TF-IDF
在查询语句时,我们可通过explain查看TF-IDF
1 | GET logstash-village/_search |
查询后可以看到TF-IDF的相关性评分
Boosting
Boosting是控制相关度的一种手段。
可选参数
返回匹配positive查询的文档,并降低匹配negative查询的文档相似度分
- 当boost > 1时,打分的权重相对性提升
- 当0 < boost <1时,打分的权重相对性降低
- 当boost <0时,贡献负分
这样就可以在不排除某些文档的前提下对文档进行查询,搜索结果中存在只不过相似度分数相比正常匹配的要低
应用场景
希望包含了某项内容的结果不是不出现,而是排序靠后
正常查询
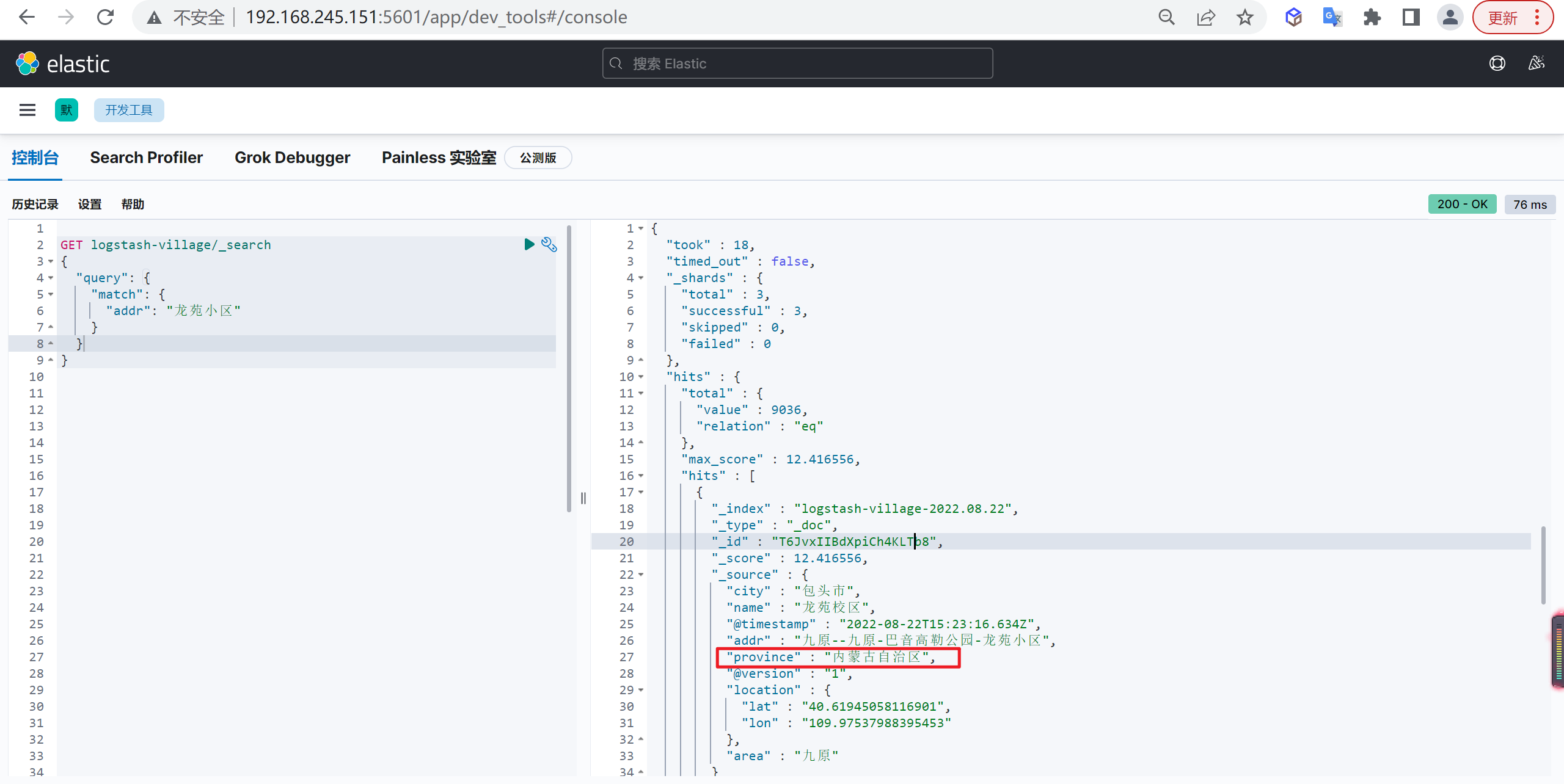
1 | GET logstash-village/_search |
正常查询的时候我们发现内蒙古排在第一位
降低评分
我们不需要不太关注于内蒙古地区的数据,我们可以将内蒙古相关评分降低
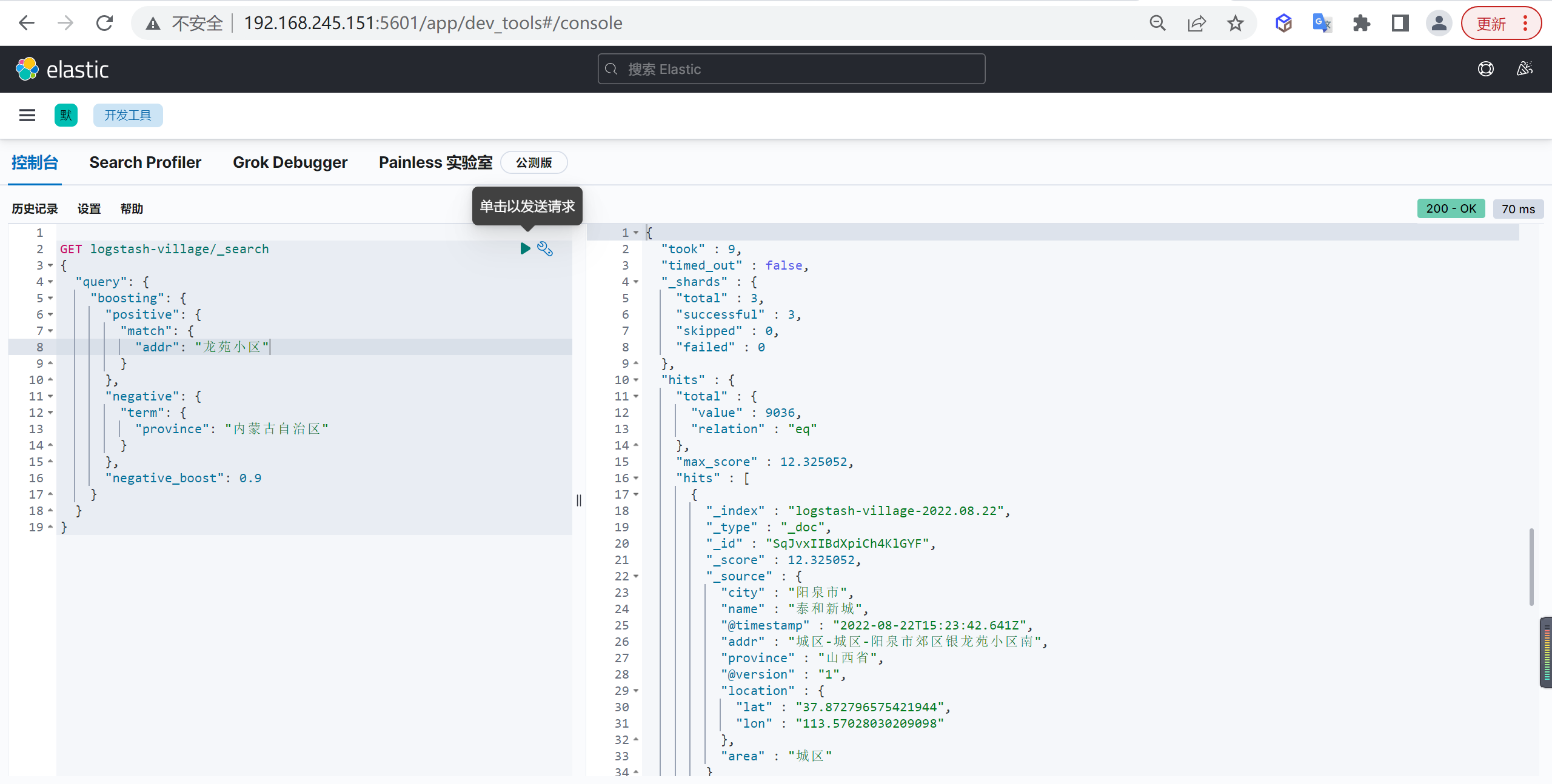
1 | GET logstash-village/_search |
我们设置
"negative_boost": 0.9,这样相关性评分就会降低,我们发现数据已经变了
布尔查询
一个bool查询,是一个或者多个查询子句的组合,总共包括4种子句,其中2种会影响算分,2种不影响算分
相关查询
- must: 相当于
&&,必须匹配,贡献算分 - should: 相当于
||,选择性匹配,贡献算分 - must_not: 相当于
!,必须不能匹配,不贡献算分 - filter: 必须匹配,不贡献算法
查询方式
在Elasticsearch中,有Query和 Filter两种不同的查询方式
- Query : 相关性算分
- Filter : 不需要算分 ,可以利用Cache,获得更好的性能
相关性并不只是全文本检索的专利,也适用于yes | no 的子句,匹配的子句越多,相关性评分越高,如果多条查询子句被合并为一条复合查询语句,比如 bool查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中
bool查询
子查询可以任意顺序出现,可以嵌套多个查询,如果你的bool查询中,没有must条件,should中必须至少满足一条查询
1 | GET logstash-village/_search |
通过bool查询查询地址包含
龙苑小区,并且绿化率大于30%非公寓住宅,并且在省份在河南省或者安徽省,并且建造年份在2010-2020的小区住房