ElasticSearch 基础查询

概述
查询是 ElasticSearch 核心功能,也是最为丰富有趣的功能,接下来我们开始学习全文查询、词项查询、复合查询、嵌套查询、位置查询、特殊查询等查询功能
正排索引
在关系型数据库中用到的索引,就是“正排索引”,假如有一张博客表:
| id | 作者 | 标题 | 内容 |
|---|---|---|---|
| 1 | 张三 | 博客标题1 | 查询是 ElasticSearch 核心功能 |
| 2 | 李四 | 博客标题2 | 也是最为丰富有趣的功能 |
索引描述
针对这个表建立 id 和标题字段的索引(正排索引):
| 索引 | 内容 |
|---|---|
| 1 | 查询是 ElasticSearch 核心功能 |
| 2 | 也是最为丰富有趣的功能 |
| 博客标题1 | 查询是 ElasticSearch 核心功能 |
| 博客标题2 | 也是最为丰富有趣的功能 |
当我们通过 id 或者标题去查询文章内容时,就可以快速找到。
但如果我们通过文章内容的关键字去查询,就只能去内容中做字符匹配了,查询效率相当慢!为了提高查询效率,就要考虑使用倒排索引。
倒排索引
倒排索引就是以文章内容的关键字建立索引,通过索引找到文档id,进而找到整个文档:
| 索引 | 文档id=1 | 文档id=2 |
|---|---|---|
| 查询 | √ | |
| 是 | √ | √ |
| 丰富有趣 | √ | |
| 功能 | √ | √ |
组成部分
一般来说,倒排索引分为两个部分:
- 词项词典:记录所有的文档词项,以及词项与倒排列表的关联关系。
- 倒排列表:记录词项与文章内容的关联关系,由一系列倒排索引项组成,倒排索引项包括文档 id、词频(词项在文档中出现的次数,评分时使用)、位置(词项在文档中分词的位置)、偏移(记录词项开始和结束的位置)
查询过程
ElasticSearch 的查询分为两个过程
创建索引
当向索引中保存文档时,默认情况下,ElasticSearch 会保存两份内容,一份是 _source 中的数据,另一份则是通过分词、排序等一系列过程生成的倒排索引文件,倒排索引中保存了词项和文档之间的对应关系
查询
当 es 接收到用户的查询请求之后,就会去倒排索引中查询,通过的倒排索引中维护的倒排记录表找到关键词对应的文档集合,然后对文档进行评分、排序、高亮等处理,处理完成后返回文档。
导入数据
因为需要查询,我们先导入一些数据
创建索引
创建一个书籍管理的索引
1 | PUT books |
导入脚本
执行命令导入数据脚本
1 | curl -XPOST "http://192.168.245.151:9200/books/_bulk?pretty" -H "content-type:application/json" --data-binary @bookdata.json |
基本查询
简单查询
我们查询所有文档
1 | get books/_search |
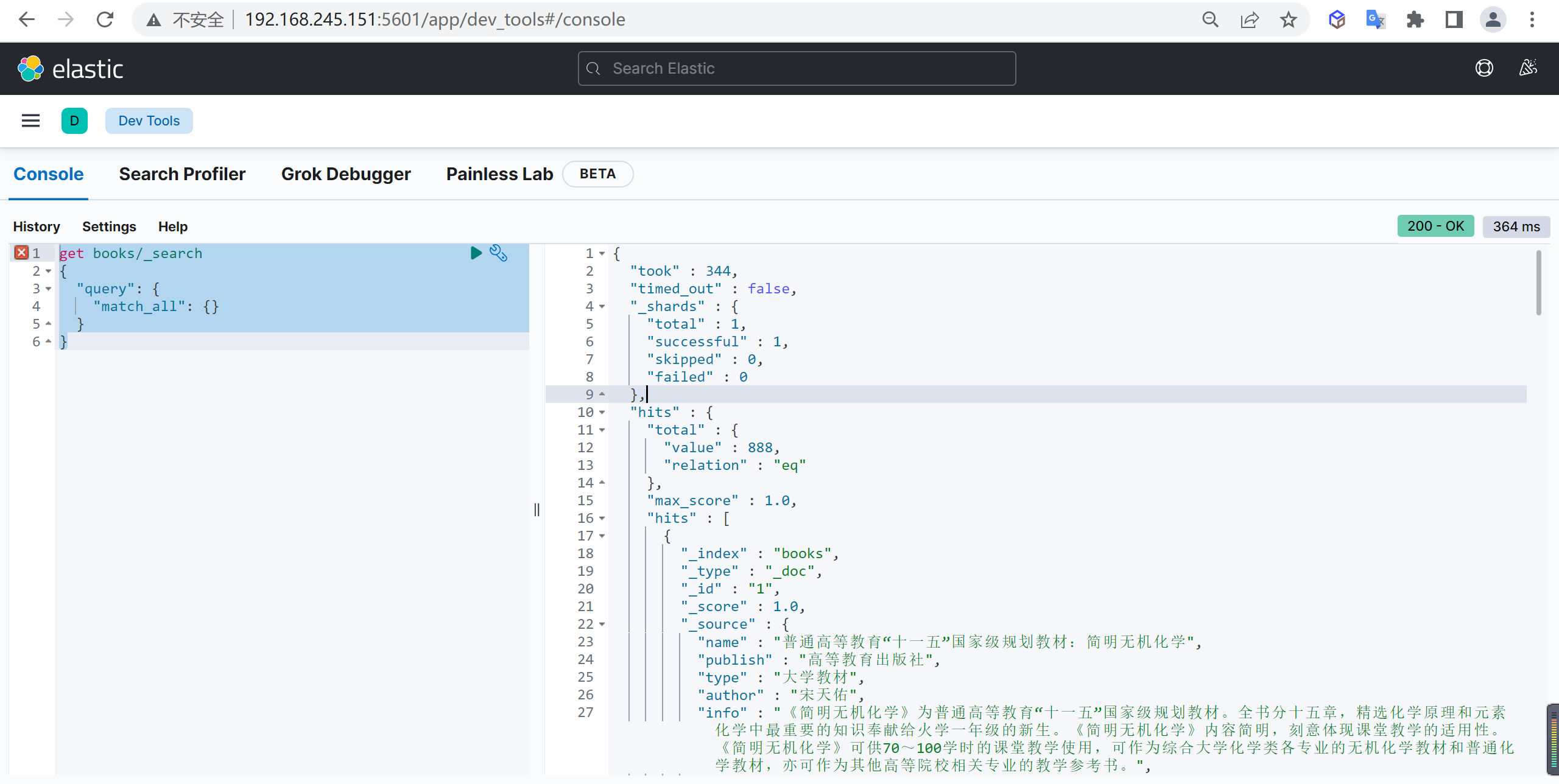
hits 中是查询结果,total 是符合查询条件的文档数,简单查询默认查询 10 条记录。
词项查询
词项查询即
term查询,根据分词查询,查询指定字段中包含给定单词的文档
term 查询不被解析,只有查询的词和文档中的词精确匹配,才会返回文档,应用场景如:人名、地名等等
查询 name 字段中包含“计算机”的文档
1 | get books/_search |
分页查询
查询默认返回前 10 条数据
ElasticSearch中也可以像关系型数据库一样,设置分页参数,size 设置查询多少条数据, from 设置查询开始的位置
1 | get books/_search |
过滤返回字段
如果返回的字段比较多,又不需要这么多字段,可以通过
_source指定返回的字段
1 | get books/_search |
过滤最低评分
有的文档得分特别低,说明这个文档和我们查询的关键字相关度很低,可以通过
min_score设置一个最低分,只有得分超过最低分的文档才会被返回
1 | get books/_search |
高亮显示
通过
highlight设置查询关键字高亮,这样可以更好的显示搜索的关键字
Highlight就是我们所谓的高亮,即允许对一个或者对个字段在搜索结果中高亮显示,比如字体加粗或者字体呈现和其他文本普通颜色等。
1 | GET books/_search |
全文查询
match
match会对查询语句进行分词,分词后,如果查询语句中的任何一个词项被匹配,则文档就会被索引到。
不相关查询
查询两个不相关的关键字
1 | GET books/_search |
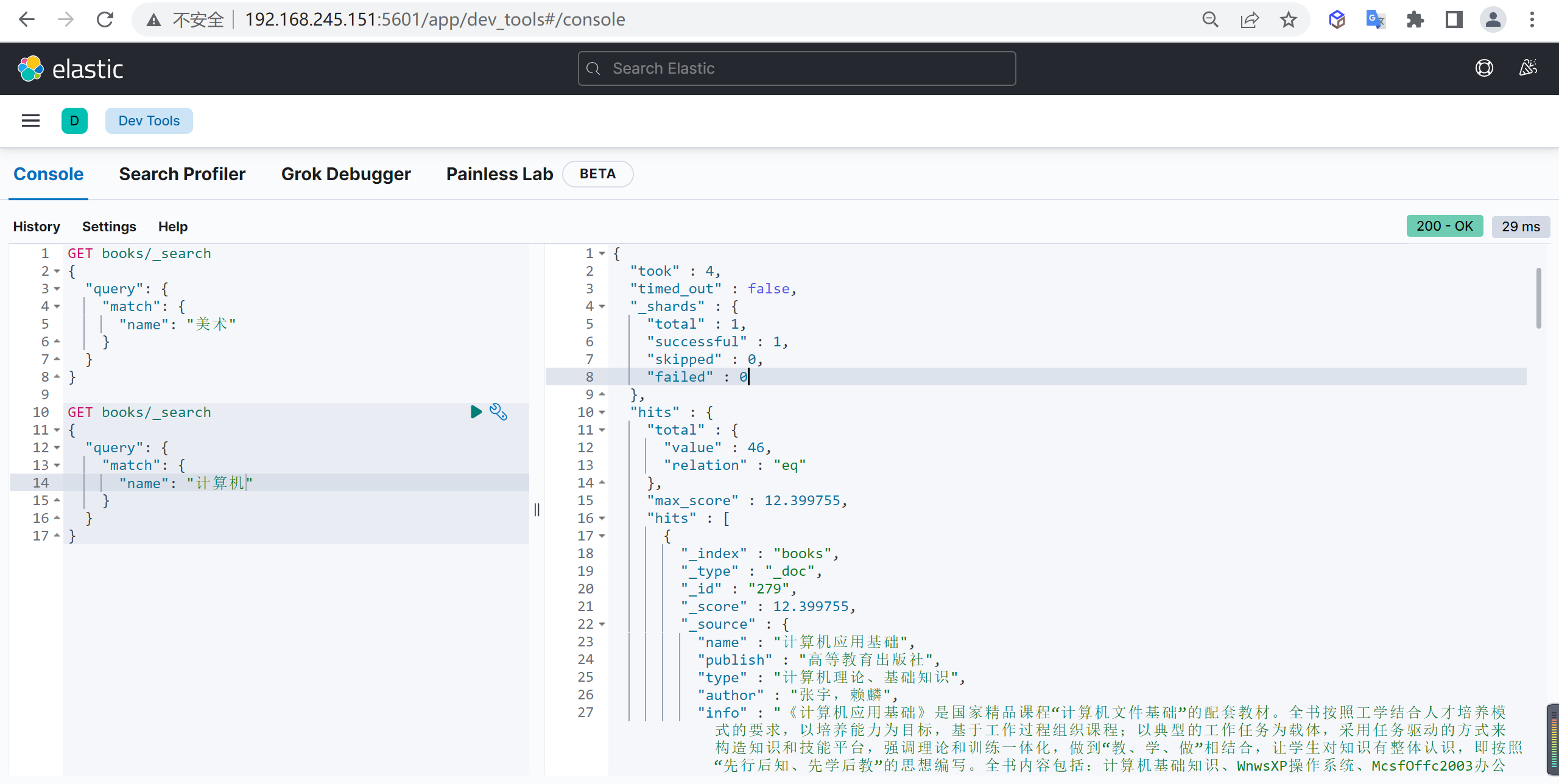
单独查询美术和计算机时,查询到符合条件的文档数分别是 9 和 46 条。
合并查询
我们在进行合并查询
1 | GET books/_search |
合并查询时会对美术计算机进行分词,分词之后再去查询,只要文档中包含任意一个分词,就回返回文档,最后查询到符合条件的文档树正好是55条。

可以看到,分词后词项之间是 OR 的关系,如果想要修改,也可以通过
operator改为 AND
1 | GET books/_search |
match_phrase
match_phrase就是短语查询,也会对查询的关键字进行分词,但是它分词后有两个特点:
- 分词后的词项顺序必须和文档中词项的顺序一致
- 所有的词都必须出现在文档中
phrase match,就是要去将多个term作为一个短语,一起去搜索,只有包含这个短语的doc才会作为结果返回,match是只在包含其中任何一个分词就返回
什么是近似匹配
现假设有两个句子
1. 普通高等教育“十一五”国家级规划教材:大学计算机基础
2. 普通高等教育“十一五”国家级规划教材:计算机控制系统(第2版)(配光盘)
进行查询
1 | "query": { |
match query进行搜索,只能搜索到包含
十一五或计算机的document,包含十一五或计算机的doc都会被返回回来
增加需求
假如要增加如下需求
十一五计算机,就靠在一起,中间不能插入任何其他字符,就要搜索出来这种doc但是要求,
十一五和计算机两个单词靠的越近,doc的分数越高,排名越靠前我们搜索时,文档中必须包含`十一五计算机这两个文档,且他们之间的距离不能超过5
要实现上述三个需求,用match做全文检索,是搞不定的,必须得用proximity match(近似匹配),proximity match分两种,短语匹配(phrase match)和近似匹配(proximity match)
DSL分析
- 检索词“十一五计算机”被分词为两个Token【十一五,Position=0】【计算机,Position=1】
- 倒排索引检索时,等价于sql:【where Token = 十一五 and 十一五_Position=0 and Token = 计算机 and 计算机_Position=1】;
如果我们不要求这两个单词相邻,希望放松一点条件,可以添加slop参数,slop代表两个token之间相隔的最多的距离(最多需要移动多少次才能相邻)
需求分析
这里直接使用前面十一五计算机短语,并不能查询到文档,因为分词之后,关键字之间还间隔这国家级规划教材:大学这些内容
这种情况可以使用 slop 参数来指定关键字之间的距离,注意这个距离,不是指关键字之间间隔的字数,而是指它们之间的 position 位置的间隔。
什么是 position
每份文档中的字段被分词器解析之后,解析出来的词项都包含一个 position 字段表示词项的位置,每份文档的 position 都从 0 开始,每个词项递增 1
分词测试
因为我们使用的分词器是
ik_max_word,这里我们就是用ik_max_word测试分词
1 | GET books/_analyze |
下面是分词的结果
1 | { |
分词后 十一五 最后出现的 position = 6 ,而 计算机 第一次出现的 position = 13,中间间隔了 6 个位置,所以只需要设置
slop为 6 即可查询到文档
查询
1 | GET books/_search |
match_phrase_prefix
类似于
match_phrase查询,只不过这里多了一个通配符,match_phrase_prefix将最后一个词项作为前缀去查询匹配,但是这种匹配方式效率较低,了解即可,不推荐使用
1 | GET books/_search |
这个查询过程,会自动进行词项匹配,会自动查找以 计 开始的词项,默认是 10 个,我们可以通过 max_expansions 控制值匹配的词项个数。例如以 计 开始的词项控制匹配个数为 1 、2 、3 时,匹配到的词项分别为 计分、计划、计算 。
注意
match_phrase_prefix` 是针对分片级别的查询,每个分片匹配的词项可能不一致。我们现在练习创建的索引分片数为 1 ,所以使用起来并不会有什么问题。但是如果分片数大于 1 时,查询结果就可能有问题。
以 match_phrase_prefix 为 1 ,分片数为 3 举例,可能会查询出 3 个匹配词项对应的文档:
| 分片数 | 匹配词项 | 文档数 |
|---|---|---|
| 分片1 | 计分 | 2 |
| 分片2 | 计划 | 1 |
| 分片3 | 计算 | 46 |
multi_match
multi_match查询提供了一个简便的方法用来对多个字段执行相同的查询
查询
同时查询
name以及info字段包含java的文档
1 | GET books/_search |
参数
- query: 来自用户输入的查询短语
fields: 数组,默认支持最大长度1024,可以单独为任意字段设置相关度权重,支持通配符;fields可以为空,为空时会取mapping阶段配置的所有支持term查询的filed组合在一起进行查询
query_string
query_string 是 ES DSL 查询中最为强大的查询语句,支持非常复杂的语法,适合用来做自己的搜索引擎
基本查询
查询
name字段包含十一五和计算机的文档
1 | GET books/_search |
更多待补充
simple_query_string
这个是
query_string的升级,可以直接使用 +、|、- 代替 AND、OR、NOT 等
simple_query_string 使用 fields 来指定查询的字段,即使只指定一个字段,值也必须为数组类型
1 | GET books/_search |
词项查询
词项查询,也就是
term查询,以及以term延伸的词项查询
我们已经多次涉及到这个技能点,但是没有细讲,今天我们就来从头理一下 term 查询
term
term不会对查询字符进行分词,直接拿查询字符去倒排索引中比对
基本查询
下面我们查询以下
计算机为关键字进行查询
1 | GET books/_search |
我们发现是可以查询出来数据的
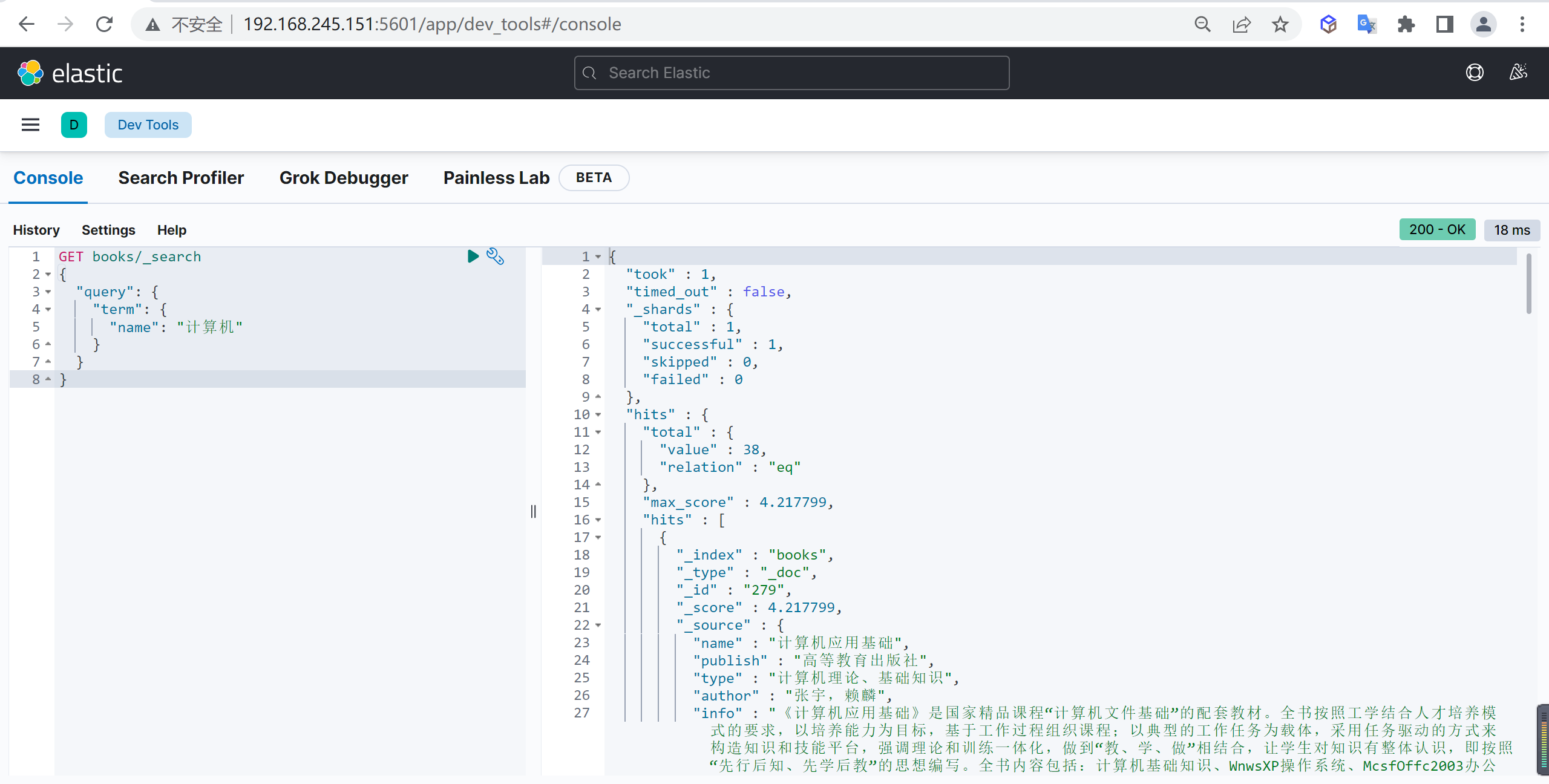
语句查询
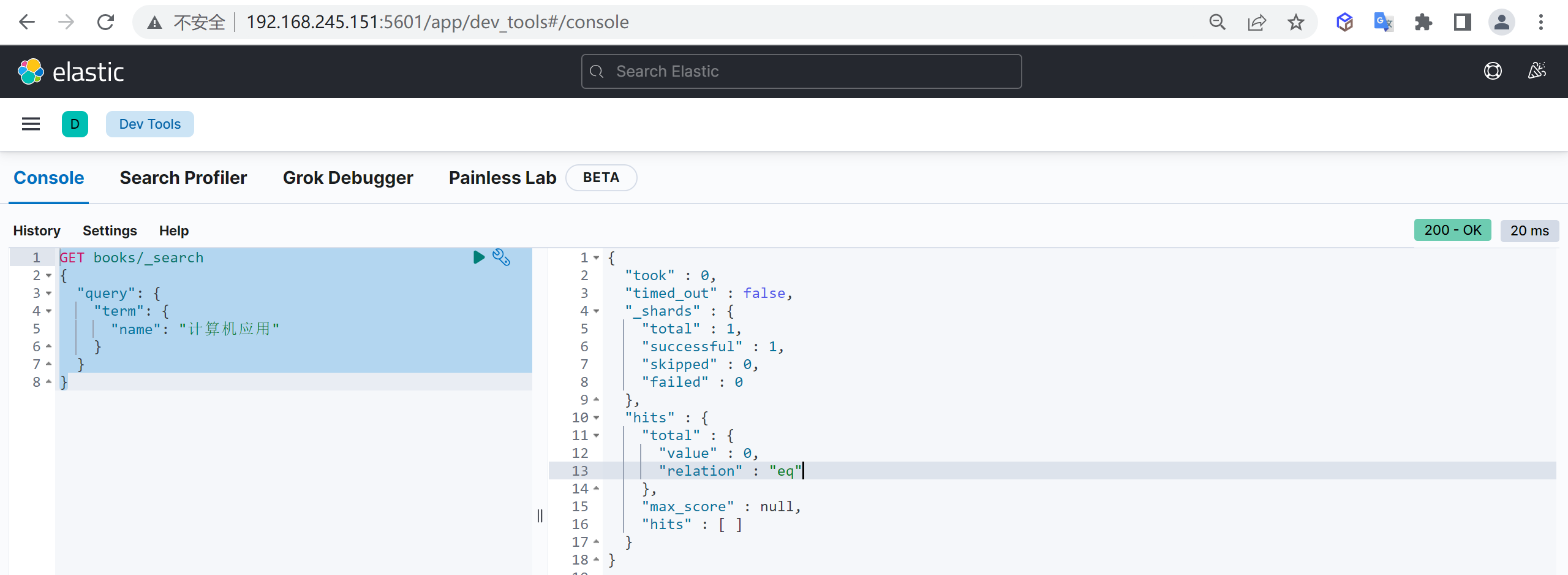
下面我们找一个未分词的
计算机应用进行查询
1 | GET books/_search |
因为直接到倒排词库查询,所以是查询不出来结果的
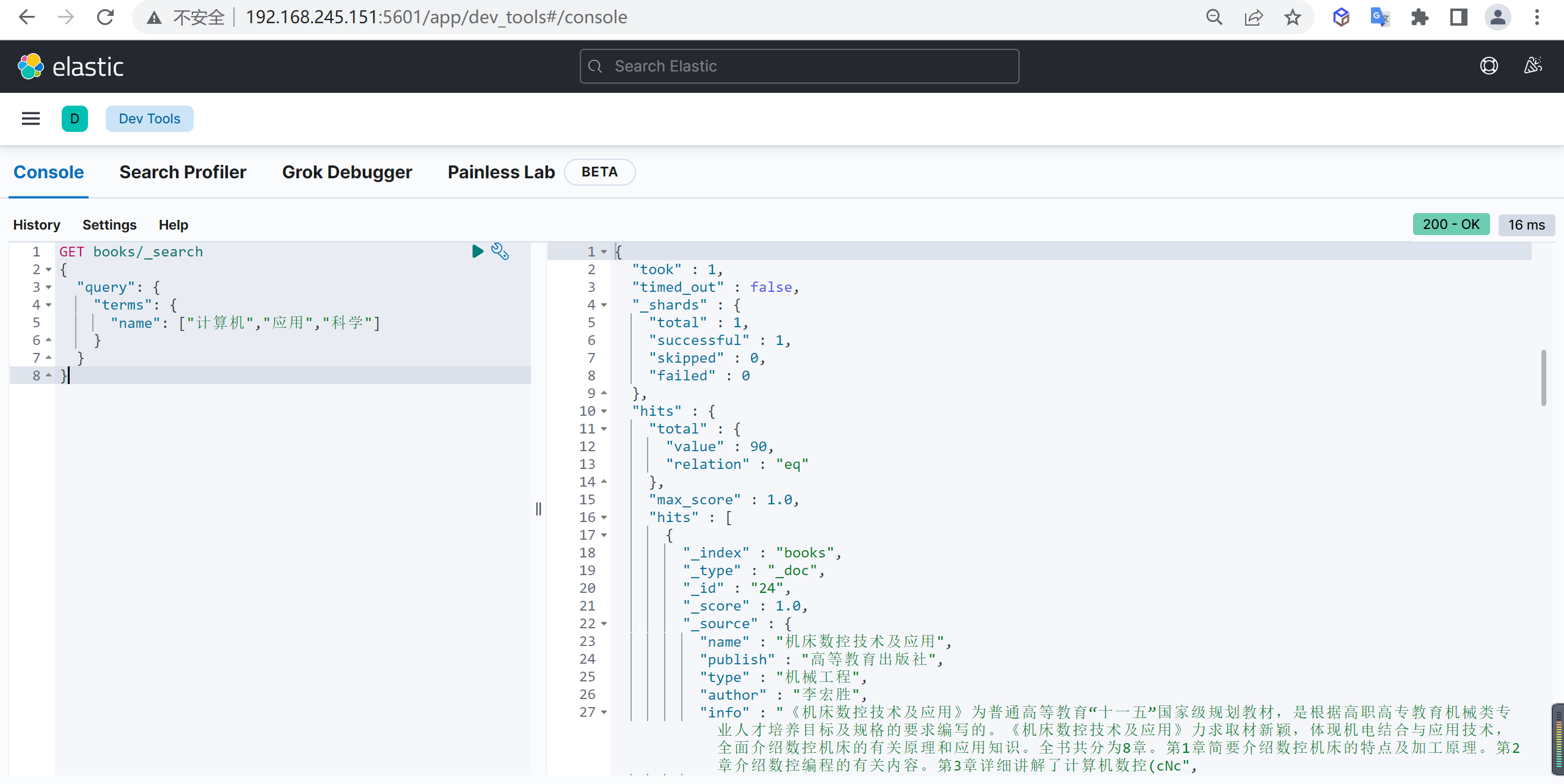
terms
使用多个关键字进行查询,参数为数组类型,关键字之间的关系为 OR 。
基本查询
只要
name任意包含下面的任意一个就可以查询出来
1 | GET books/_search |
Terms lookup
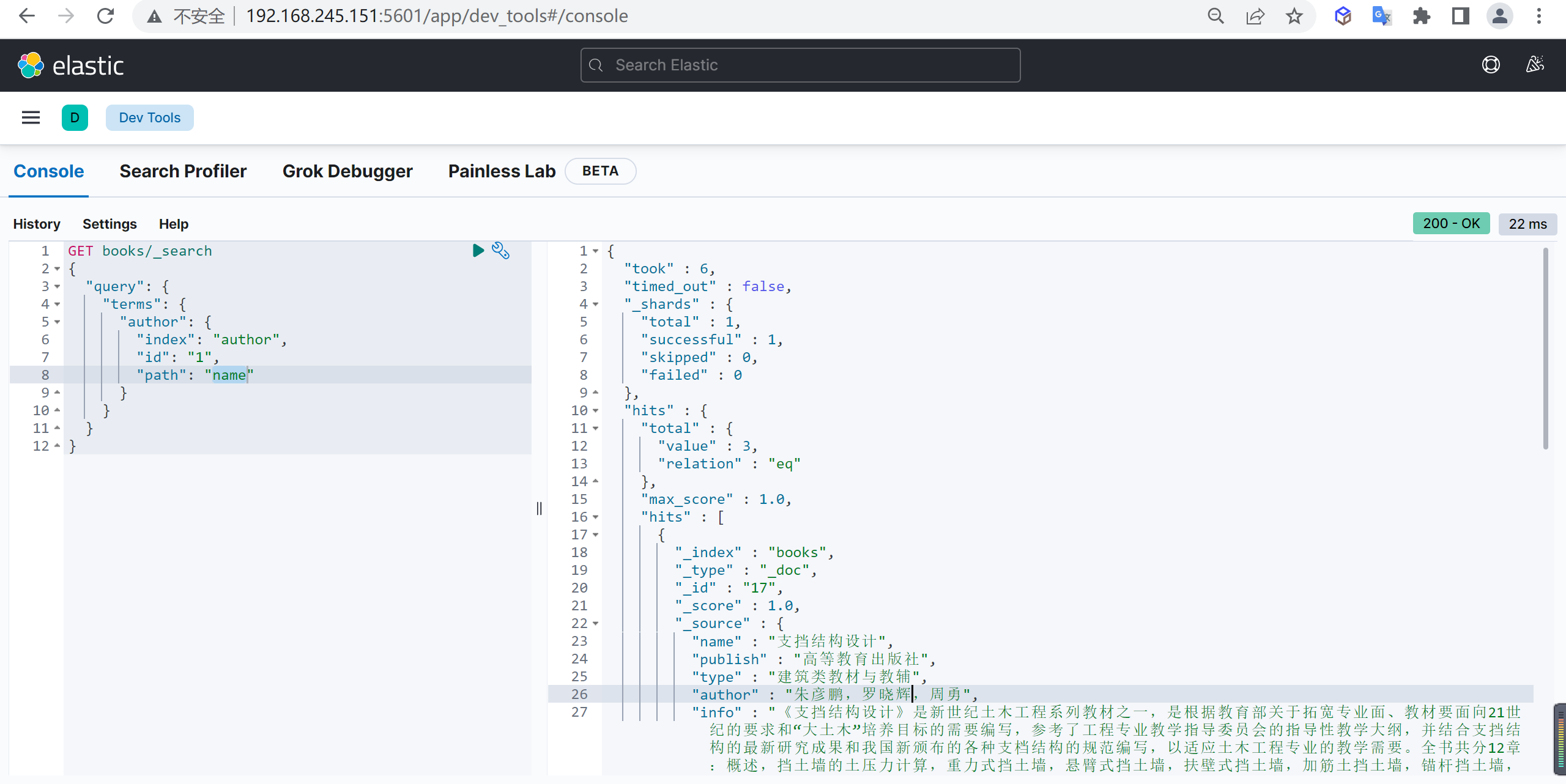
terms中除了简单的多个关键字查询,还支持 Terms lookup 查询
先查询获取已知文档的字段值,然后再将这些值用作关键字查询其他文档,有点类似于关系型数据库中的子查询,支持跨字段或者跨索引。
参数介绍
首先介绍一下 Terms lookup 的参数:
| 字段 | 内容 |
|---|---|
| index | 必填,已知文档所在的索引。 |
| id | 必填,已知文档的ID。 |
| path | 必填,需要获取的文档字段值。 |
| routing | 选填,文档的路由值,如果在为文档建立索引时提供了自定义路由值,则此参数是必需的。 |
准备数据
新建索引,添加一个文档,name 字段包含三个作者的名字
1 | PUT author/_doc/1 |
查询数据
使用 author 索引中 id 为 1 的 name 字段值作为查询关键字
1 | GET books/_search |
注意事项
默认情况下,Elasticsearch 将 terms 查询限制为最多65536个关键字,包括 Terms lookup 查询出来的关键字,可以通过 index.max_terms_count修改限制
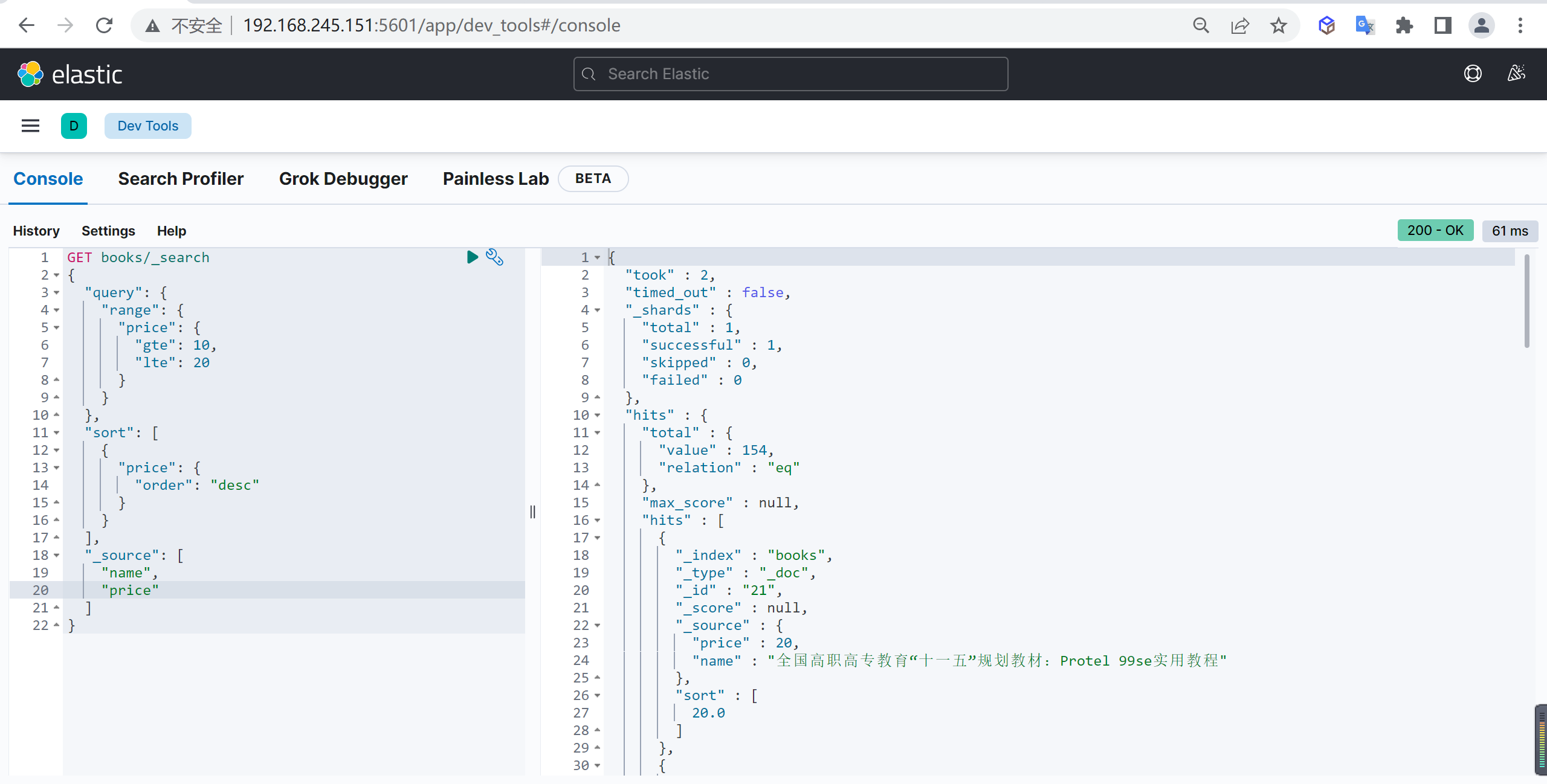
range
range可以进行范围查询,按照日期范围、数字范围等查询。
参数介绍
range中的主要参数:
| 字段 | 内容 |
|---|---|
| gt | 大于 |
| gte | 大于或等于。 |
| lt | 小于。 |
| lte | 小于或等于。 |
| format | 日期格式,如果不指定将使用 mapping 中定义日期格式。 |
| relation | 指定范围查询如何匹配 range 字段的值,可选值为:- INTERSECTS (默认值):将文档的范围字段值与查询范围相交。 - CONTAINS:使用范围字段值完全包含查询范围的文档进行匹配。 - WITHIN:使用范围字段值完全在查询范围内的文档进行匹配。 |
基本查询
查询价格范围是10-20之间的书籍,并且对价格进行倒序排序
1 | GET books/_search |
exists
exists可以判断字段是否为空,可以指定多个字段,只返回指定字段中至少有一个非空值的文档
基本查询
books 中不存在 amby 字段的书籍
1 | GET books/_search |
注意: 空字符串也是有值,null 才是空值。
prefix
prefix用于前缀查询,效率略低,除非必要,一般不推荐使用。
基本查询
查找书籍中以大学开头的文档
1 | GET books/_search |

wildcard
wildcard即通配符查询,支持单字符?和多字符*
基本查询
查询所有姓张的作者的书
1 | 查询所有姓张的作者的书 |
regexp
正则表达式查询
基本查询
查询所有姓张并且名字只有两个字的作者的书
1 | GET books/_search |
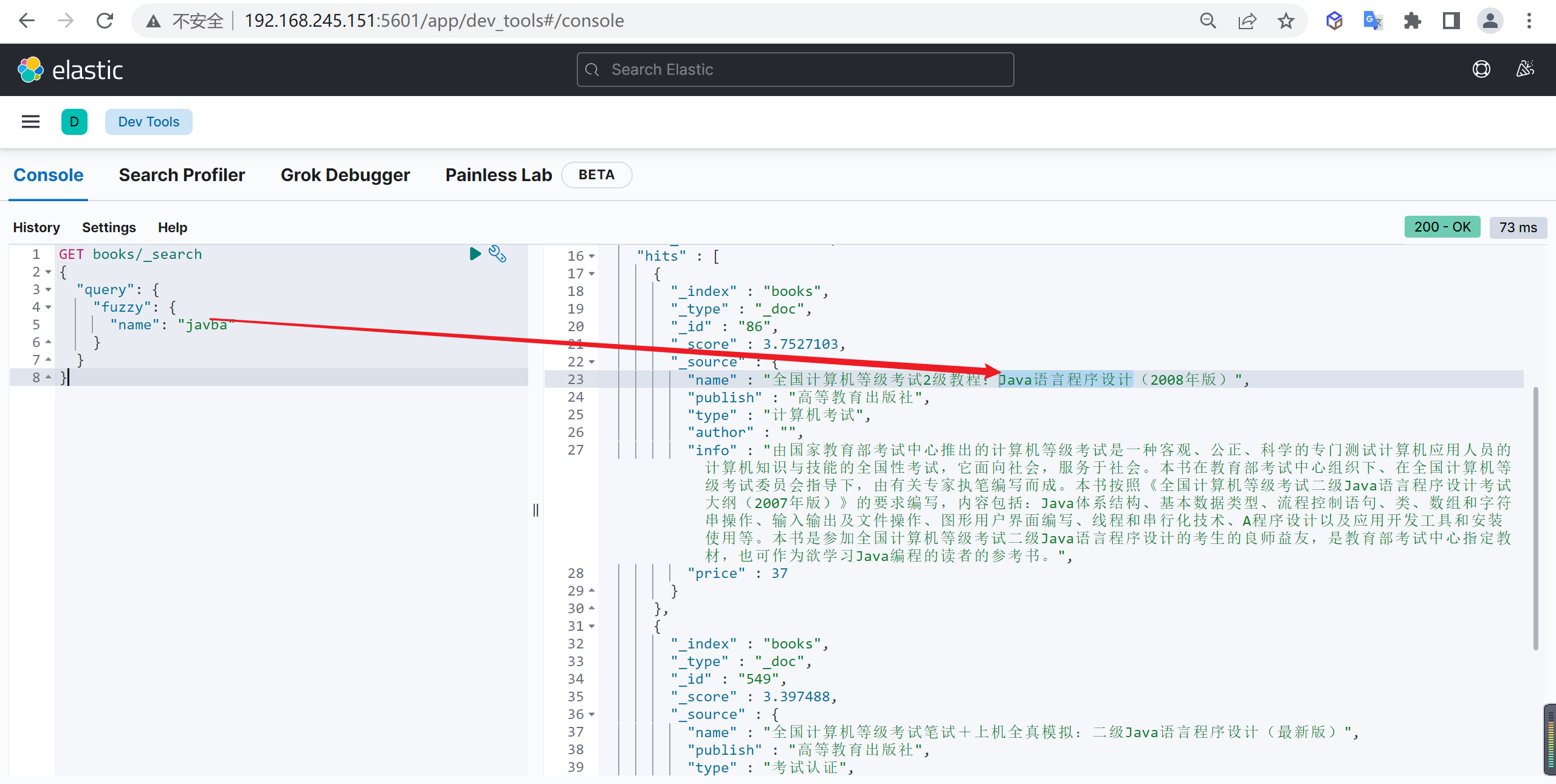
fuzzy
在实际搜索中,有时我们可能会打错字,从而导致搜索不到,在
match全文查询中,可以通过fuzziness属性实现模糊查询,而在词项查询中,就可以使用fuzzy查询与搜索关键字相似的文档。
什么是相似度
怎么样就算相似?以 LevenShtein 编辑距离为准,编辑距离是指将一个字符变为另一个字符所需要更改字符的次数,更改主要包括四种:
- 更改字符 ( javb >> java )
- 删除字符 ( javva >> java )
- 插入字符 ( jaa >> java )
- 转置字符 ( jaav >> java )
为了找到相似的词,模糊查询会在指定的编辑距离中创建搜索关键词的所有可能变化或者扩展的集合,然后进行搜索匹配。
基本查询
1 | GET books/_search |
我们发现输入错误的字符可以搜索出来正确的文档
ids
根据ID进行查询
基本查询
查询ID是1、2、3的文档
1 | GET books/_search |
复合查询
constant_score
当我们使用全文查询或词项查询时,ElasticSearch 默认会根据词频(TF)对查询结果进行评分,再根据评分排序后返回查询结果。
如果我们不关心检索词频(TF)对搜索结果排序的影响时,可以使用 constant_score 将查询语句或者过滤语句包裹起来。
基本查询
查询关键字是java的文档
1 | GET books/_search |
忽略评分
这样查询我们就可以忽略评分,忽略评分后默认显示评分是
1.0分,boost设置显示评分未1.5
1 | GET books/_search |
bool
bool底层使用的是 Lucene 的BooleanQuery,可以将任意多个简单查询组装在一起
关键参数
有四个关键字可供选择,四个关键字所描述的条件可以有一个或者多个
| 字段 | 内容 |
|---|---|
| must | 文档必须匹配 must 选项下的查询条件。 |
| should | 文档可以匹配 should 下的查询条件,也可以不匹配。 |
| must_not | 文档必须不满足 must_not 选项下的查询条件。 |
| filter | 类似于 must,但是 filter 不评分,只是过滤数据。 |
基本查询
查询 name 字段中必须包含 “计算”,同时书价不在 [0,30] 区间内,info 字段可以包含 “程序设计” 也可以不包含
1 | GET books/_search |
minmum_should_match
bool查询还涉及到一个关键字minmum_should_match参数,在 ElasticSearch 官网上称作 “最小匹配度”
在之前学习的 match 或者这里的 should 查询中,都可以设置 minmum_should_match 参数
查询分析
查询 name 中包含 “程序设计” 关键字的文档
1 | GET books/_search |
关键字分词
例如上面的查询,查询的时候首先会对查询的关键字进行分词
1 | GET _analyze |
分词的结果是:[“程序设计”,”程序”,”设计”],然后使用
should将分词后的每一个词项查询term子句组合构成一个bool查询,换句话说,上面的查询和下面的查询等价:
1 | GET books/_search |
在这两个查询语句中,都是文档只需要包含词项中的任意一项即可,文档就回被返回,在 match 查询中,可以通过 operator 参数设置文档必须匹配所有词项。
部分匹配
但如果只想匹配一部分词项,就要使用
minmum_should_match,指定至少匹配的词项,可以指定个数或者百分比,以下三个查询等价:
1 | GET books/_search |
dis_max
返回与一个或多个包装查询(称为查询子句或子句)匹配的文档
如果返回的文档与多个查询子句匹配,则该dis_max查询会为该文档分配来自所有匹配子句的最高相关性得分,再加上所有其他匹配子查询的平局打破增量
准备数据
为了更好的演示dis_max,我们加入一些数据
1 | PUT blog |
基本查询
现在搜索 “Java解决方案” 关键字,但是不确定关键字是在 title 还是在 content,所以两者都搜索
1 | GET blog/_search |
按照我们理解,第二篇文档中的content同时包含了 “Java” 和 “解决方案” ,应该评分更高,但是实际搜索并非这样,第一篇文档的评分反而比较高:
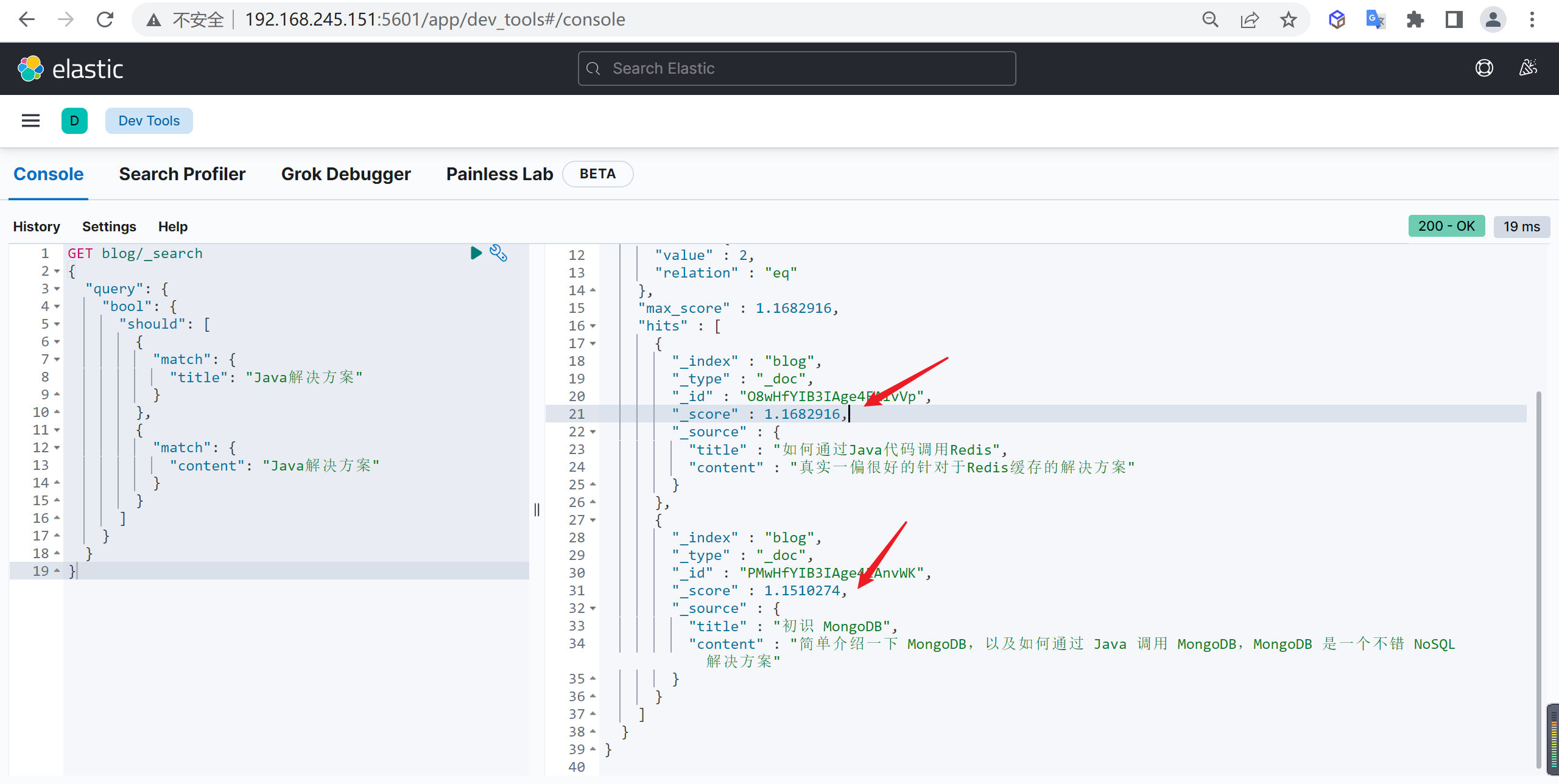
should评分策略
要理解为什么会这样,我们需要看一下
should查询的评分策略:
- 首先执行
should中的所有查询 - 对所有查询结果的评分求和
- 对求和结果
*有查询结果的子句数量 - 再将上一步结果
/所有查询子句数量
第一篇
- title 中 包含 Java,假设评分是 1.1
- content 中包含 解决方案,假设评分是 1.2
- 有查询结果的子句数量为 2
- 所有查询子句数量也是 2
- 最终结果:
(1.1 + 1.2)* 2 / 2 = 2.3
第二篇
- title 中 不包含查询关键字,没有得分
- content 中包含 Java 和 解决方案,假设评分时 2
- 有查询结果的子句数量为 1
- 所有查询子句数量也是 2
- 最终结果:
2 * 1 / 2 = 1
如何解决
在
should查询中,title 和 content 相当于是相互竞争的关系。
为了解决这一问题,就需要用到 dis_max (disjunction max query,分离最大化查询):匹配的文档依然返回,但是只将最佳匹配的子句评分作为查询的评分。
1 | GET blog/_search |
查询过程
第一篇
- title 中 包含 Java,假设评分是 1.1
- content 中包含 解决方案,假设评分是 1.2
- 最后取两个子句中的最高分作为文档的最后得分,即 1.2
第二篇
- title 中 不包含查询关键字,没有得分
- content 中包含 Java 和 解决方案,假设评分时 2
- 最后取两个子句中的最高分作为文档的最后得分,即 2
- 所以最后第二篇的得分高于第一篇,符合我们的需求。
其他参数
tie_breaker
在 dis_max 查询中,只考虑最佳匹配子句的评分,完全不考虑其他子句的评分。但是,有的时候,我们又不得不考虑一下其他 query 的分数,此时,可以通过 tie_breaker 参数来优化。
tie_breaker
参数取值范围:0 ~ 1,默认取值为 0,会将其他查询子句的评分,乘以 tie_breaker 参数,然后再和最佳匹配的子句进行综合计算
function_score
例如想要搜索附近的肯德基,搜索的关键字是肯德基,我希望能够将评分较高的肯德基餐厅优先展示出来。
但是默认的评分策略是没有办法考虑到餐厅评分的,他只是考虑相关性,这个时候可以通过 function_score query 来实现。
准备数据
1 | PUT blog |
基本查询
查询标题中包含 java 关键字的文档:
1 | GET blog/_search |
因为第二篇文档的 title 中有两个 java,所有得分会比较高
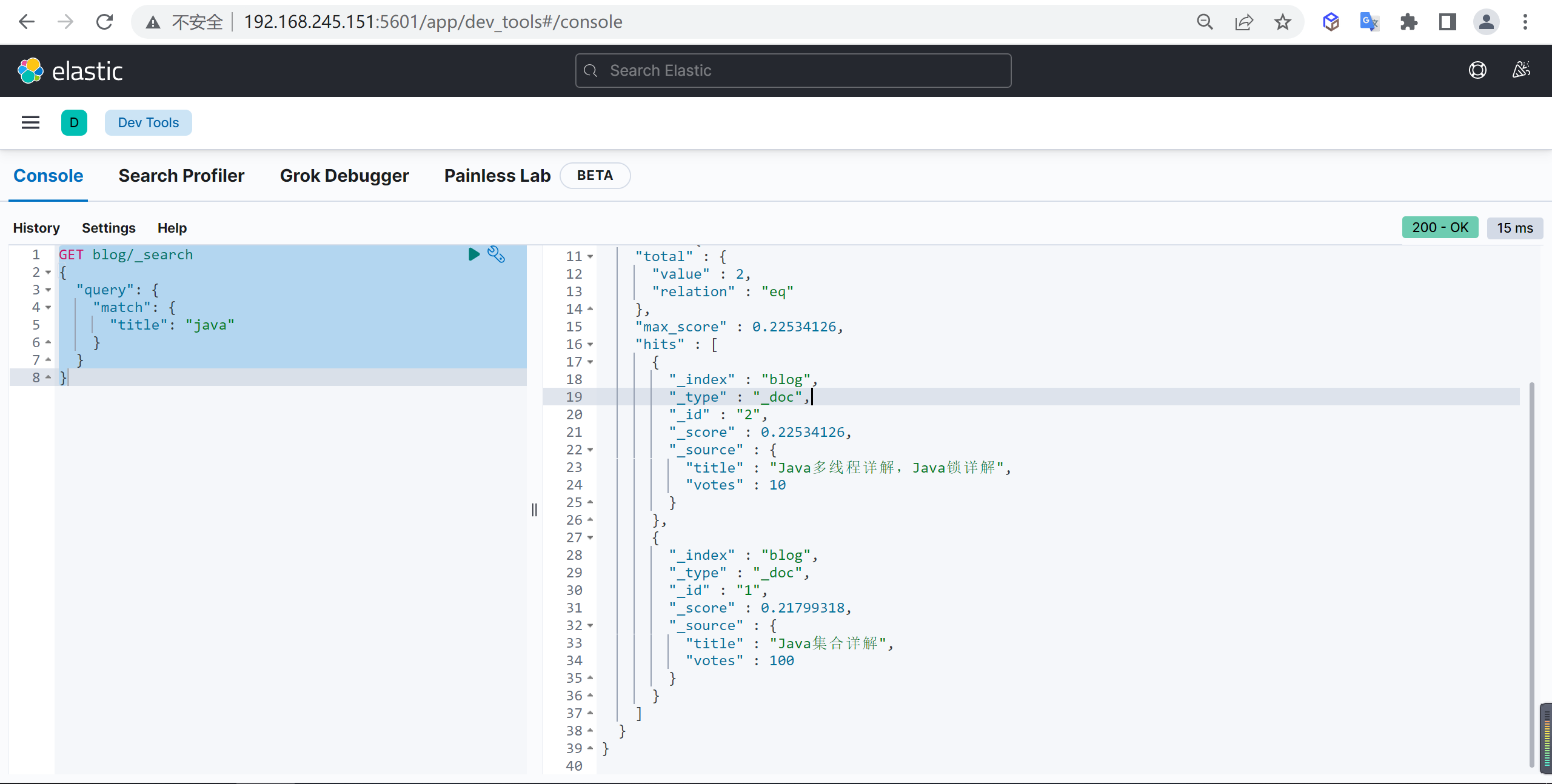
考虑votes评分
如果希望能够考虑 votes 字段,将 votes 高的文档优先展示,就可以通过
function_score来实现。
具体的思路,就是在旧的得分基础上,根据 votes 的数值进行综合运算,重新得出一个新的评分,具体的计算方式有以下几种:
weightrandom_scorescript_scorefield_value_factor
weight
weight可以对评分设置权重,在旧的评分基础上乘以weight,他其实无法解决我们上面所说的问题
基本查询
1 | GET blog/_search |
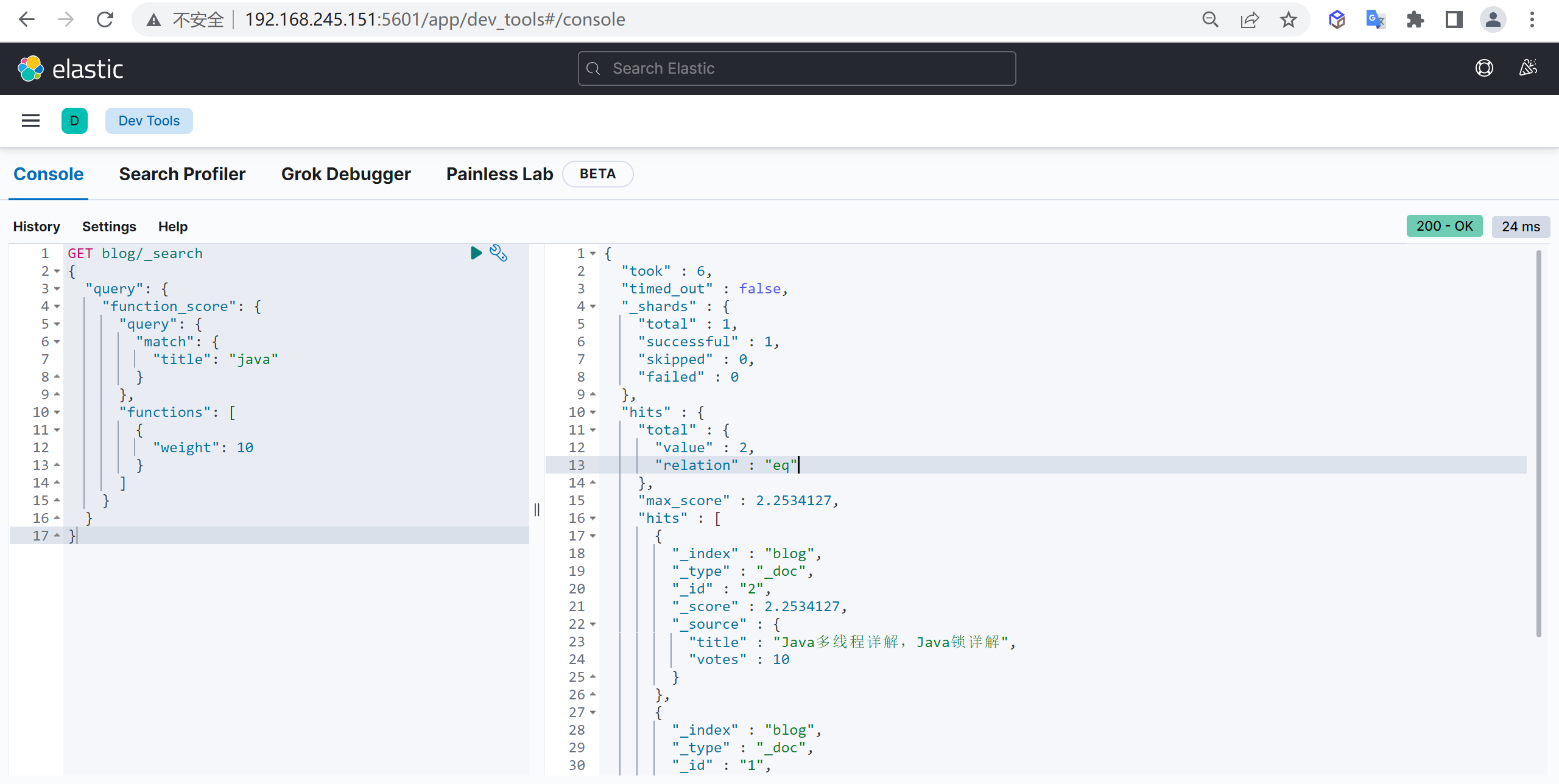
random_score
random_score会根据 uid 字段进行 hash 运算,生成随机分数,使用random_score时可以配置一个种子,如果不配置,默认使用当前时间
1 | GET blog/_search |
其他也无法解决问题,只是分值随机了
script_score
script_score是自定义评分脚本
基本查询
假设每个文档的最终得分是旧的分数加上 votes,查询方式如下
1 | GET blog/_search |
这种方式符合我们的预期
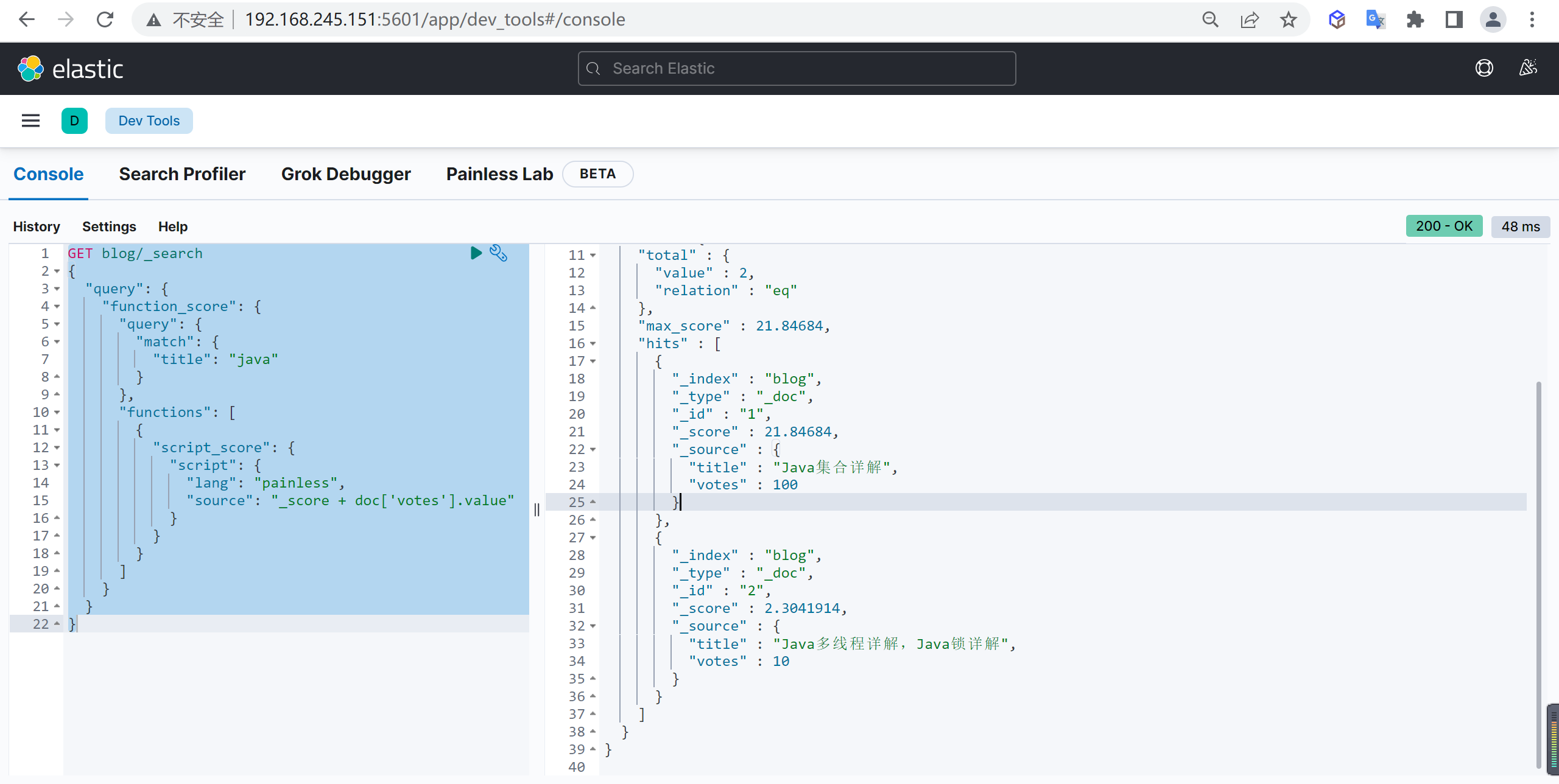
field_value_factor
field_value_factor类似于script_score,但是不用自己写脚本,而是使用影响因子和内置函数进行计算
参数说明
| 字段 | 内容 |
|---|---|
| field | 需要进行计算的文档字段。 |
| factor | 计算时与字段值相乘的影响因子,默认为 1。 |
| modifier | 可选择 ElasticSearch 内置函数,默认不使用 |
基本使用
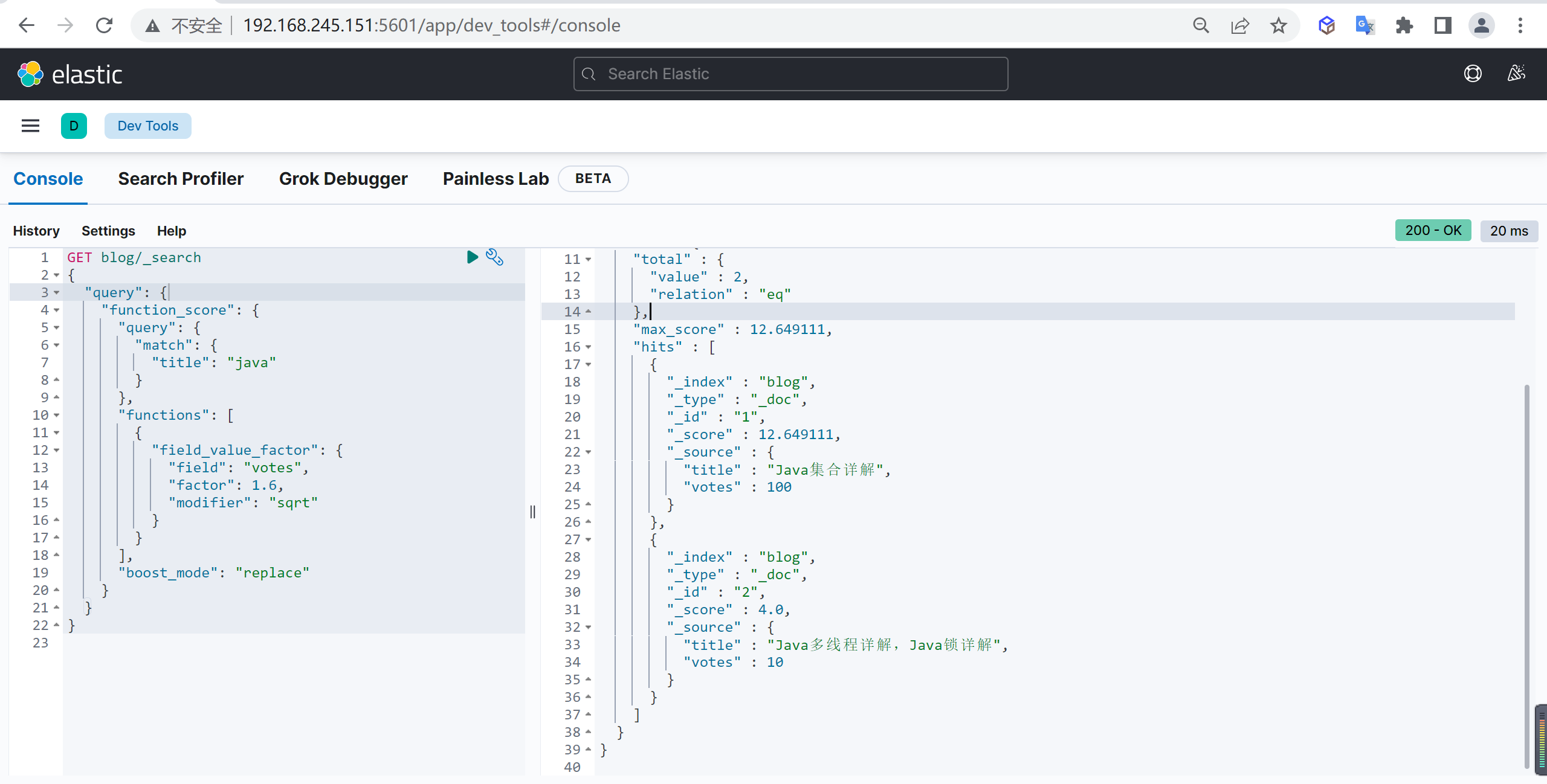
下面演示一个稍复杂查询,将 votes 字段值乘以影响因子 1.6,结果再取平方根,最后忽略
query查询的分数sqrt(1.6 * doc['votes'].value):
1 | GET blog/_search |
modifier参数
modifier其他的内置函数还有:
| 字段 | 内容 |
|---|---|
| none | 不进行任何计算 (默认) |
| log | 字段值取常用对数。如果字段值为0到1之间,将导致错误,可以考虑使用下面的 log1p 函数 |
| log1p | 字段值加1后,取常用对数 |
| log2p | 字段值加2后,取常用对数 |
| ln | 字段值取自然对数。如果字段值为0到1之间,将导致错误,可以考虑使用下面的 ln1p 函数 |
| ln1p | 字段值加1后,取自然对数 |
| ln2p | 字段值加2后,取自然对数 |
| square | 字段值的平方 |
| sqrt | 字段值求平方根 |
| reciprocal | 字段值取倒数 |
score_mode参数
score_mode参数表示functions模块中不同计算方法之间的得分计算方式
| 字段 | 内容 |
|---|---|
| multiply | 得分相乘 (默认) |
| sum | 得分相加 |
| avg | 得分取平均值 |
| first | 取第一个有效的方法得分 |
| max | 最大的得分 |
| min | 最小的得分 |
使用案例如下
1 | GET blog/_search |
max_boost参数表示functions模块中得分上限
1 | GET blog/_search |
boosting
可以对有些评分进行降低
参数
| 字段 | 内容 |
|---|---|
| positive | 得分不变 |
| nagetive | 降低得分 |
| nagetive_boost | 降低得分的权重,取值范围 [0 ~1] |
基本查询
下面进行以下正常的查询
1 | GET books/_search |
降低评分
使用 nagetive 和 nagetive_boost 降低字段值中包含 “2008” 的文档得分
1 | GET books/_search |
地理位置查询
数据准备
地理位置查询需要准备一些位置信息,我们插入一些数据
创建索引
1 | PUT geo |
插入数据
准备一个geo.json 文件,贴上如下文件内容,注意最后一行要留空
1 | {"index":{"_index":"geo","_id":1}} |
批量插入
执行下面的命令批量插入数据
1 | curl -XPOST "http://192.168.245.151:9200/geo/_bulk?pretty" -H "content-type:application/json" --data-binary @geo.json |
geo_distance
给出一个中心点和距离,查询以该中心点为圆心,以距离为半径范围内的文档
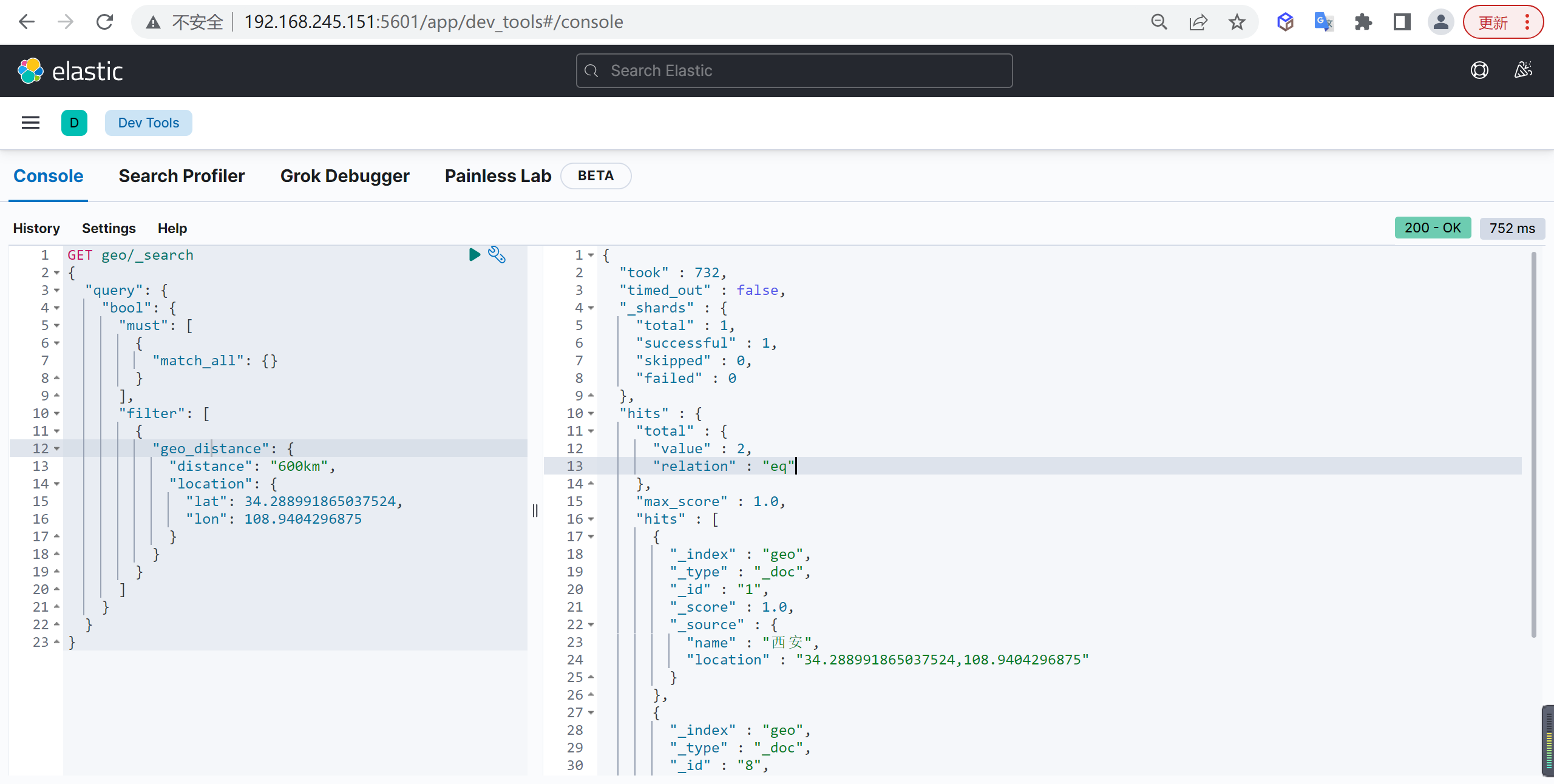
基本查询
查询以圆心为中心,600KM范围内的文档
1 | GET geo/_search |
geo_bounding_box
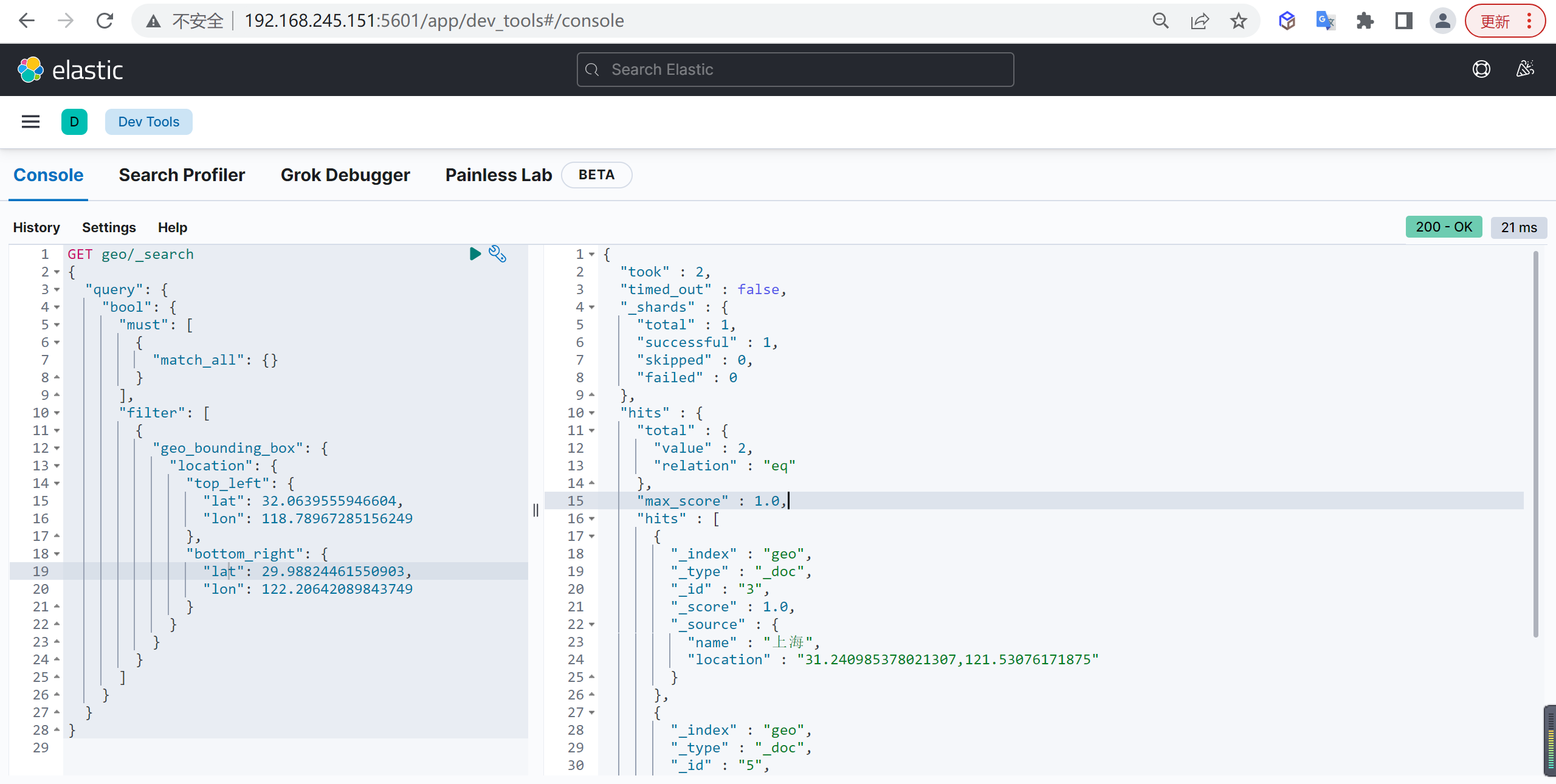
geo_bounding分别制定左上和右下两个点,查询两个点组成的矩形内所有文档
基本查询
1 | GET geo/_search |
geo_polygon
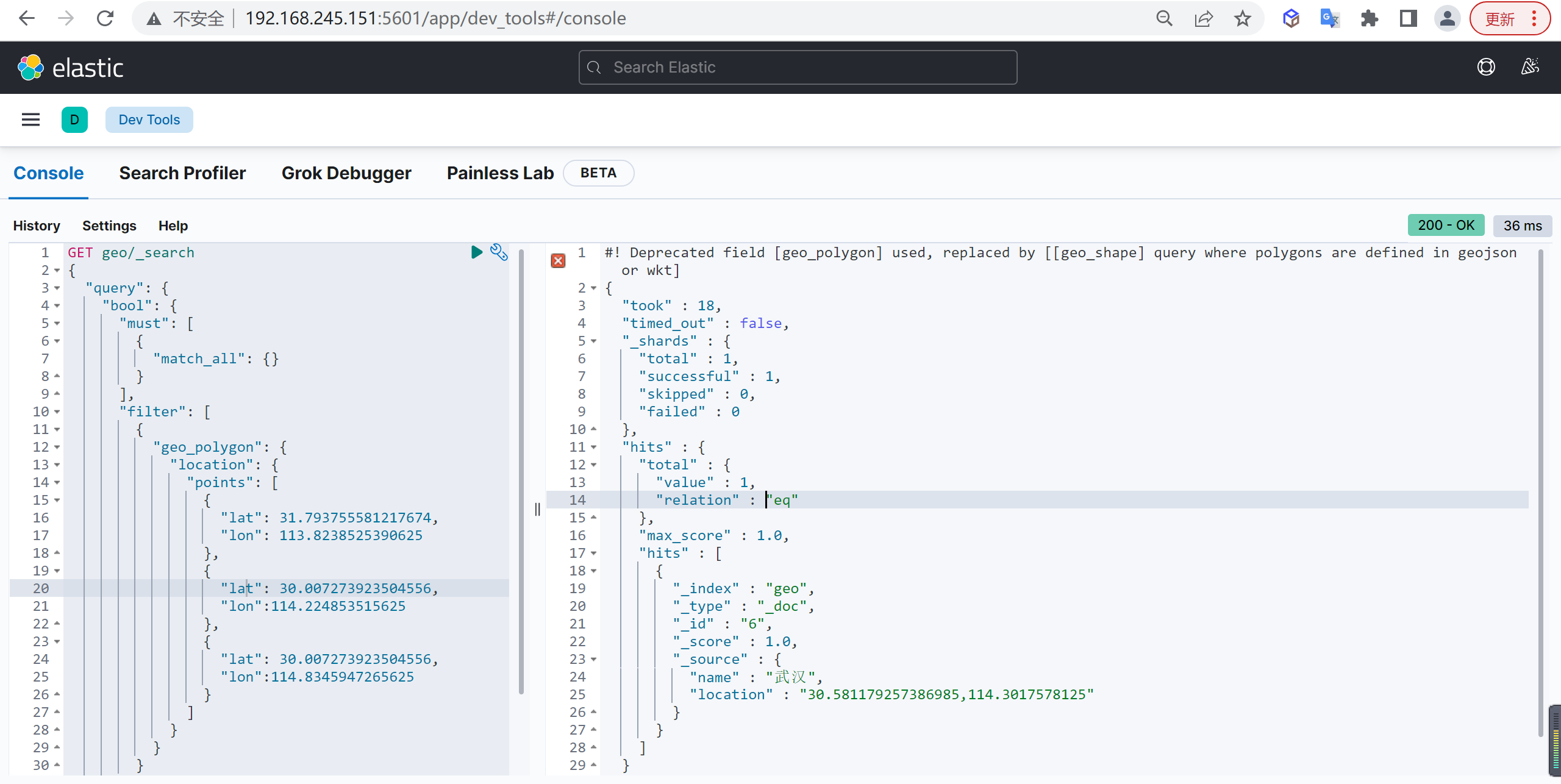
geo_polygon最少制定三个点,查询组成的多边形范围内所有文档
基本查询
1 | GET geo/_search |
geo_shape
geo_shape用来查询图形,针对geo_shape字段类型,两个图形之间的关系有:相交、包含、不相交
准备数据
新建索引
1 | PUT geo_shape |
插入数据
添加一条线
1 | PUT geo_shape/_doc/1 |
基本查询
接下来查询某一个图形中是否包含该线:
1 | GET geo_shape/_search |
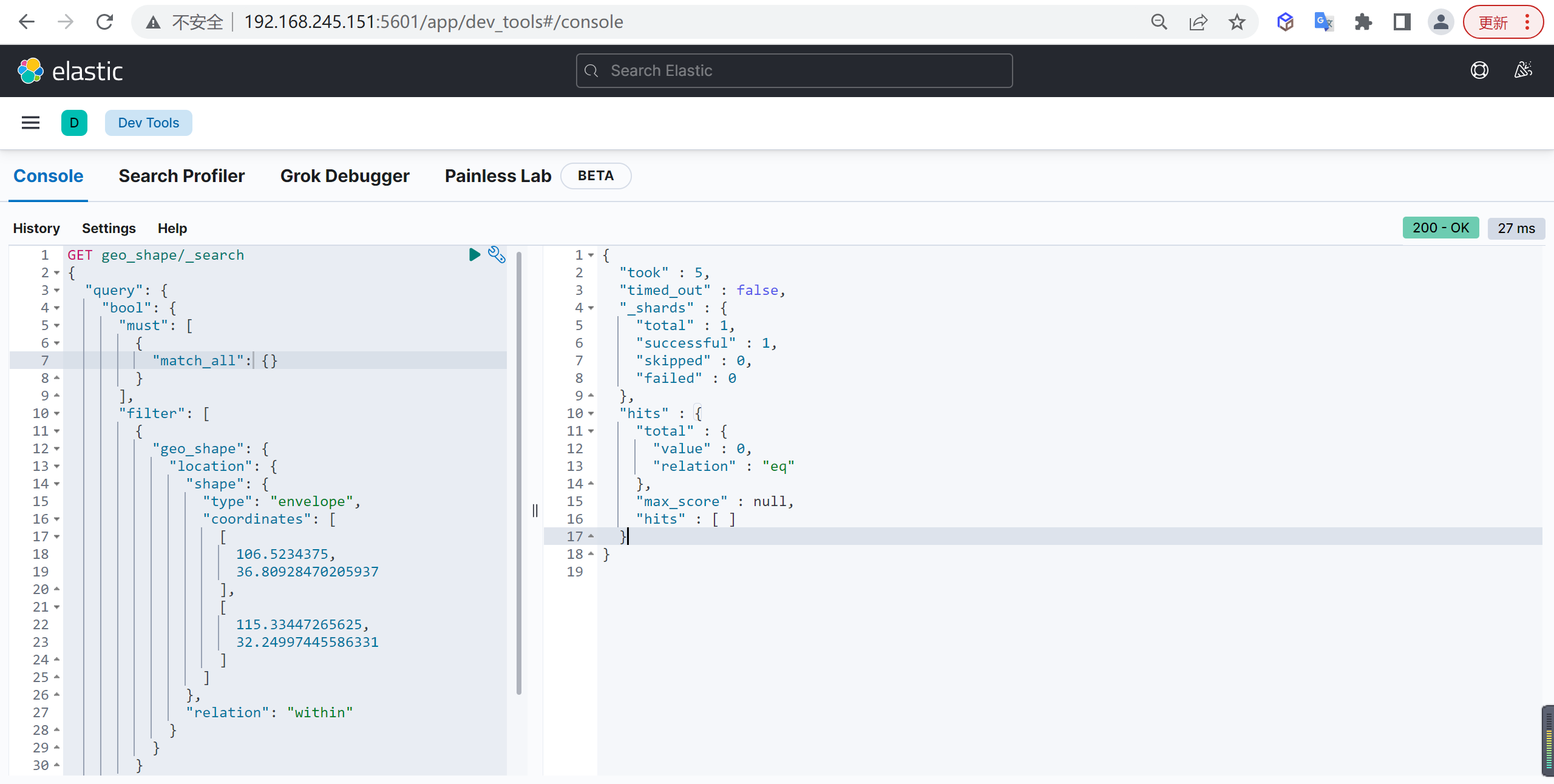
关键参数
relation属性表示两个图形的关系:
within包含intersects相交disjoint不相交