ElasticSearch 分布式文档

分布式文档原理
下面我们讲解下文档搜索的原理
索引的路由计算
当索引一个文档的时候,文档会被存储到一个主分片中, Elasticsearch如何知道一个文档应该存放到哪个分片中呢?

首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了,实际上,这个过程是根据下面这个算法决定的:
1 | shard = hash(routing) % number_of_primary_shards |
- routing值是一个任意字符串,它默认是
_id,但也可以自定义。 - 这个routing字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到
number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
注意事项
通过上面的公式,我们理解并且也需要记住一个重要的规律
创建索引的时候就确定好主分片的数量,并且永远不会改变这个数量,数量的改变将导致上述公式的结果变化,最终会导致我们的数据无法被找到。
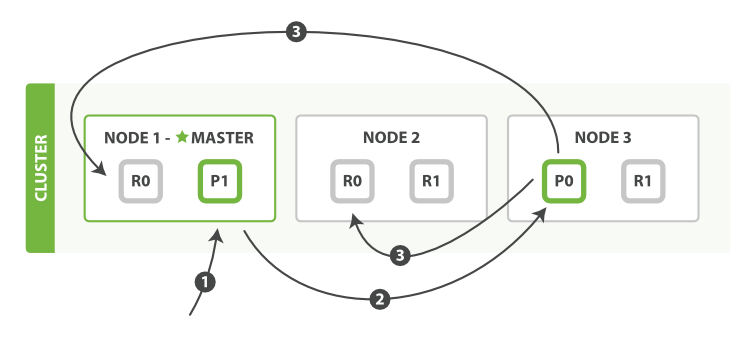
文档的写操作
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上
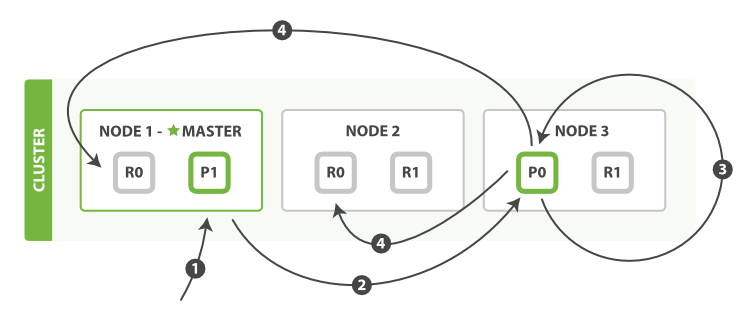
下图是数据写入P0主分片的过程,master在这里起到一个协调节点的作用
详细步骤
下面我们罗列在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
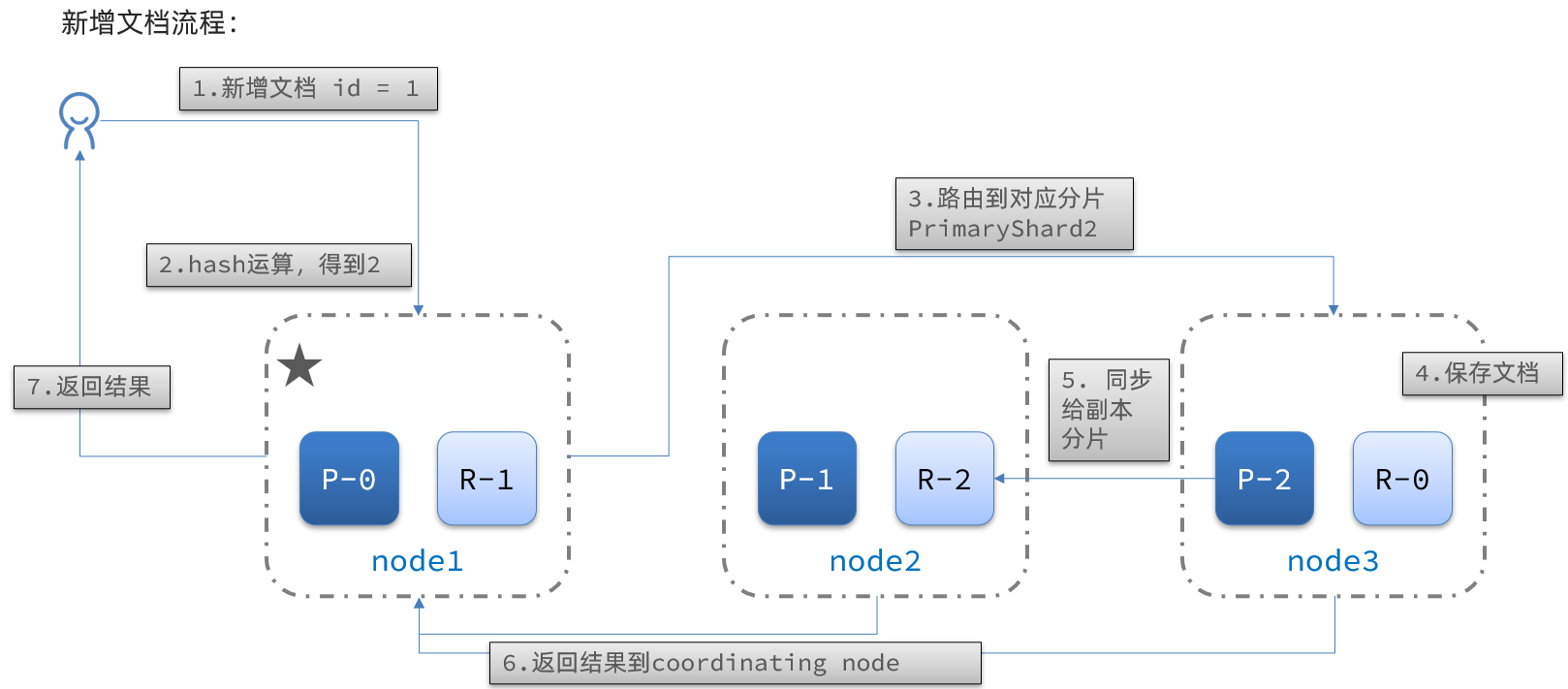
- 客户端给 Node 1 发送新建、索引或删除请求。
- 节点使用文档的
_id确定文档属于分片0,它转发请求到 Node 3 ,分片0位于这个节点上。 - Node 3 在主分片上执行请求
- Node 3保存文档,将数据保存到主分片
- 保存成功后,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上
- 当所有的复制节点报告成功, Node 3 报告成功到请求的节点
- 请求的节点再报告给客户端,客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片
注意事项
把文档存储写入到primary shard,如果设置了index.write.wait_for_active_shards=1,那么写完主节点,直接返回客户端,如果 index.write.wait_for_active_shards=all,那么必须要把所有的副本写入完成才返回客户端
实验验证
创建一个customer的索引
1 | PUT /customer |
写入一条数据
1 | POST customer/_doc |
暂时node2节点
1 | docker pause node-2 |
再尝试写入,发现写入阻塞,一直等到我们恢复node2节点
搜索文档(单个)
我们根据文档ID查询的时候ES是如何搜索到我们的文档的呢?
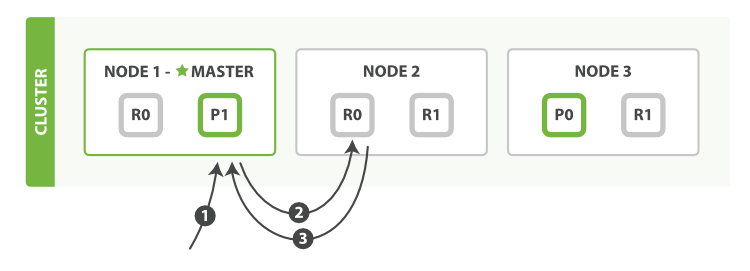
详细步骤
下面我们罗列在主分片或复制分片上检索一个文档必要的顺序步骤:
- 客户端给 Node 1 发送get请求。
- 节点使用文档的
_id确定文档属于分片0,对应的复制分片在三个节点上都有,此时它转发请求到Node2 - Node 2 返回文档(document)给 Node 1 然后返回给客户端
注意事项
对于读请求,为了平衡负载,请求节点会为每个请求选择不同的分片——它会循环所有分片副本
一个被索引的文档已经存在于主分片上却还没来得及同步到副本分片上,这时副本分片会报告文档未找到,如果查询主分片则会成功返回文档,这种情况下会产生读写不一致的情况
由于可能存在primary shard的数据还没同步到 replica shard上的情况,所以客户端可能查询到旧的数据,我们可以做相应的调整,保证读取到最新的数据。
更新文档(单个)
更新文档,必须先定位到主分片,修改文档后,再次同步到其他副本中才算完成
详细步骤
以下是部分更新一个文档的步骤:
- 客户端向
Node 1发送更新请求,发现主分片在Node 3 - 它将请求转发到主分片所在的
Node 3 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档, 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引, 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
文档复制
当主分片把更改转发到副本分片时, 它不会转发更新请求,相反,它转发完整文档的新版本
注意,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达,如果Elasticsearch仅转发更改请求,则可能导致更新顺序错误,导致文档更新结果错误。
全文搜索
对于全文搜索而言,文档可能分散在各个节点上,那么在分布式的情况下,如何搜索文档呢?
搜索,分为2个阶段,搜索(query)+取回(fetch)
搜索(query)
在初始
查询阶段时, 查询会广播到索引中每一个分片拷贝(主分片或者副本分片), 每个分片在本地执行搜索并构建一个匹配文档的 优先队列。
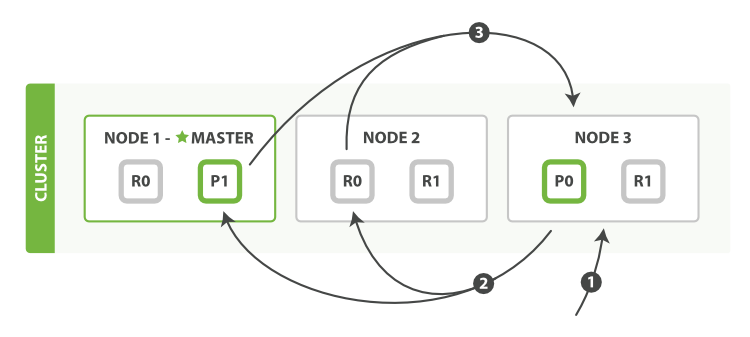
详细步骤
查询阶段包含以下三步:
- 客户端发送一个 search(搜索) 请求发送给
Node 3, 他会创建了一个长度为from+size的空优先级队 Node 3转发这个搜索请求到索引中每个分片的主分片或副本分片,每个分片在本地执行这个该查询并且结果将结果存储到一个大小为from+size的本地有序优先队列里去。- 每个分片返回
document的ID和该节点优先队列里的所有document的排序值给协调节点Node 3,而Node 3会把这些值合并到自己的优先队列里产生全局排序结果。
什么是优先级队列
一个
优先队列仅仅是一个存有top-n匹配文档的有序列表,优先队列的大小取决于分页参数from和size,如下搜索请求将需要足够大的优先队列来放入100条文档
1 | GET /_search |
注意事项
当一个搜索请求被发送到某个节点时,这个节点就变成了协调节点
这个节点的任务是广播查询请求到所有相关分片并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
第一步是广播请求到索引中每一个节点的分片拷贝, 查询请求可以被某个主分片或某个副本分片处理,这就是为什么更多的副本(当结合更多的硬件)能够增加搜索吞吐率, 协调节点将在之后的请求中轮询所有的分片来分摊负载。
每个分片在本地执行查询请求并且创建一个长度为 from + size 的本地优先队列,也就是说,每个分片创建的结果集足够大,均可以满足全局的搜索请求,分片返回一个轻量级的结果列表到协调节点,它仅包含文档 ID 集合以及任何排序需要用到的值,例如 _score
协调节点将这些分片级的结果合并到自己的有序优先队列里,它代表了全局排序结果集合,至此查询过程结束。
取回(fetch)
查询阶段标识哪些文档满足搜索请求,但是我们仍然需要取回这些文档
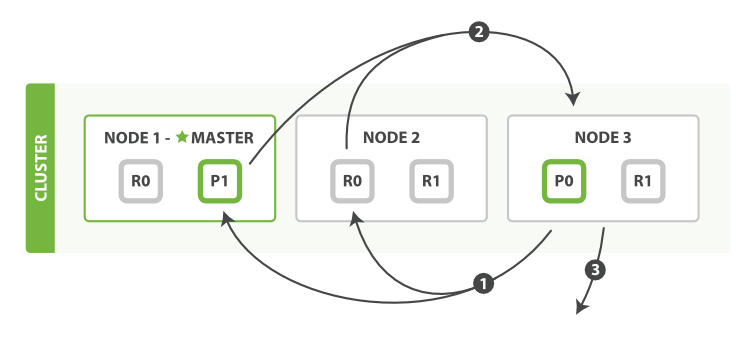
详细步骤
分发阶段由以下步骤构成:
- 协调节点辨别出哪个
document需要取回,并且向相关分片发出GET请求。 - 每个分片加载
document并且根据需要丰富它们,然后再将document返回协调节点。 - 一旦所有的
document都被取回,协调节点会将结果返回给客户端。
注意事项
协调节点首先决定哪些文档
确实需要被取回。
例如,如果我们的查询指定了 { "from": 90, "size": 10 } ,最初的90个结果会被丢弃,只有从第91个开始的10个结果需要被取回,这些文档可能来自和最初搜索请求有关的一个或者多个甚至全部分片。
协调节点给持有相关文档的每个分片创建一个 multi-get request ,并发送请求给同样处理查询阶段的分片副本
路由机制
假设你有一个100个分片的索引,当一个请求在集群上执行时会发生什么呢?
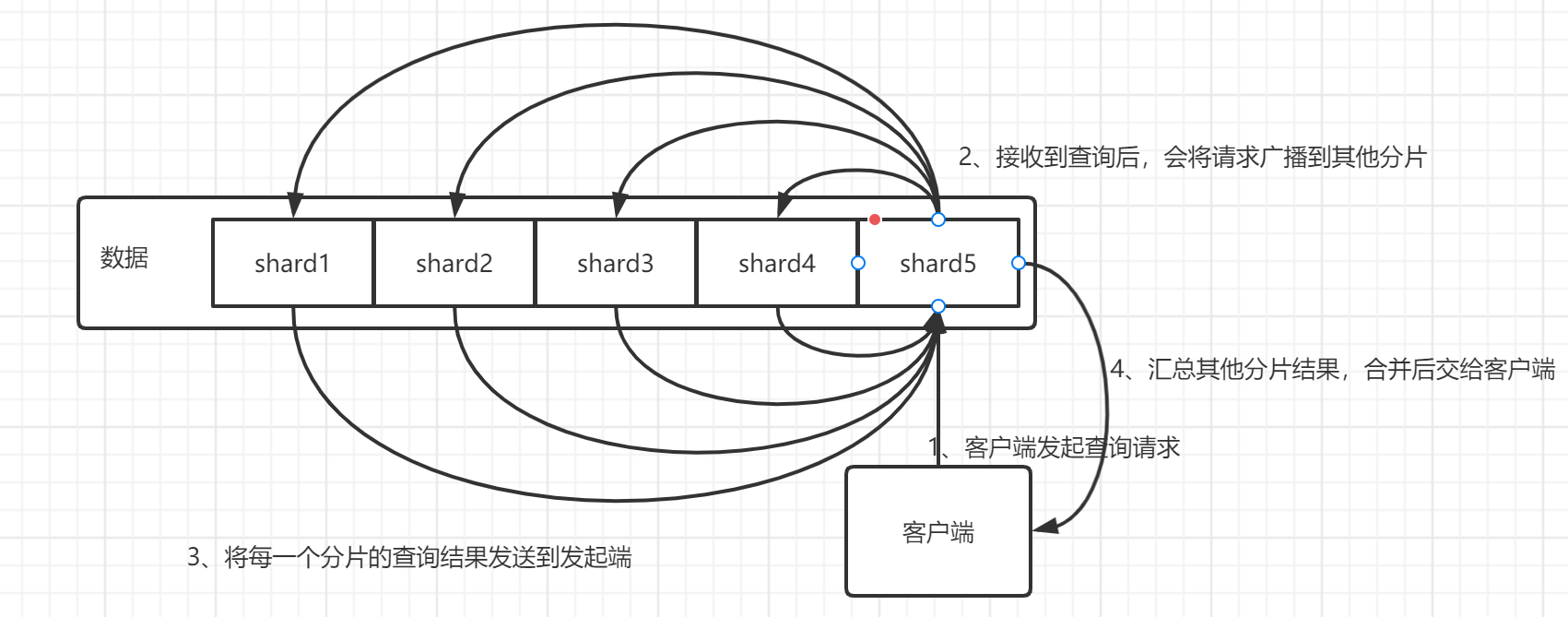
- 这个搜索的请求会被发送到一个节点
- 接收到这个请求的节点,将这个查询广播到这个索引的每个分片上(可能是主分片,也可能是复本分片)
- 每个分片执行这个搜索查询并返回结果
- 结果在通道节点上合并、排序并返回给用户
为什么使用路由
因为默认情况下,Elasticsearch使用文档的ID(类似于关系数据库中的自增ID),如果插入数据量比较大,文档会平均的分布于所有的分片上,如果不按照分片键进行搜索会导致了Elasticsearch不能确定文档的位置,所以它必须将这个请求广播到所有的N个分片上去执行 这种操作会给集群带来负担,增大了网络的开销。
如果你根本就不使用路由,Elasticsearch将确保你的文档以均衡的方式分布在所有不同的分片中,那么为什么还需要使用路由?定制路由允许你将同一个路由值得多篇文档归集到某一个分片中,而一旦这些文档放入到同一索引中,就可以路由某些查询,让它们可以在索引分片得子集中执行(简而言之:根据指定的散列值决定相关文档放在哪些分片上),类似于分库分表的路由键的概念。
路由查询
下面我们演示以下路由的使用
普通查询
下面我们介绍下不加路由的查询方式
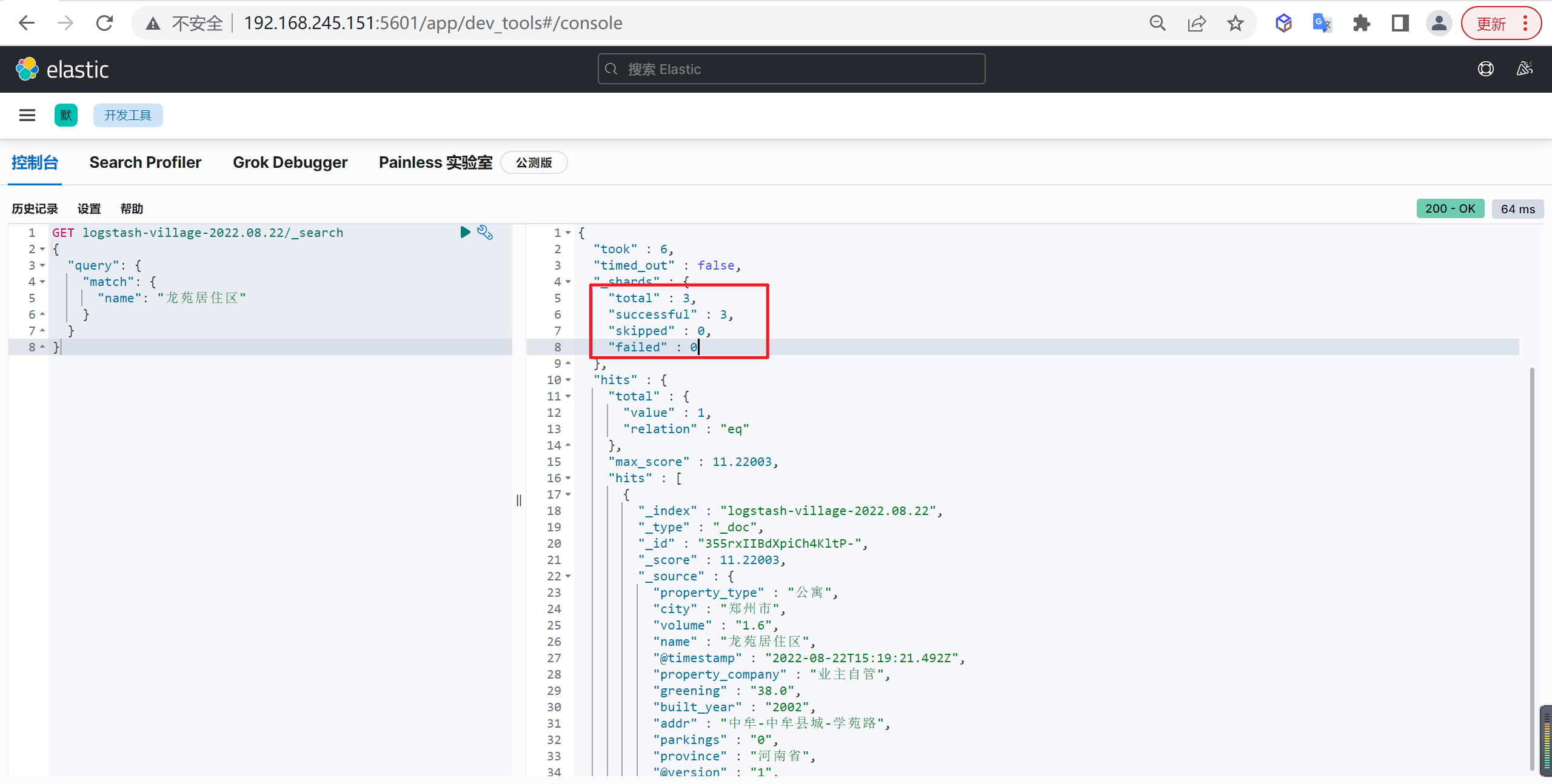
1 | GET logstash-village-2022.08.22/_search |
我们发现查询的时候扫描了三个分片
路由查询
下面我们通过路由的方式进行查询试试,路由查询只需要在请求后面加上路由key即可
1 | GET logstash-village-2022.08.22/_search?routing=routingKey |
这个路由key可以随意写,默认查询的路由key是
_id,现在我们就换成了routingKey
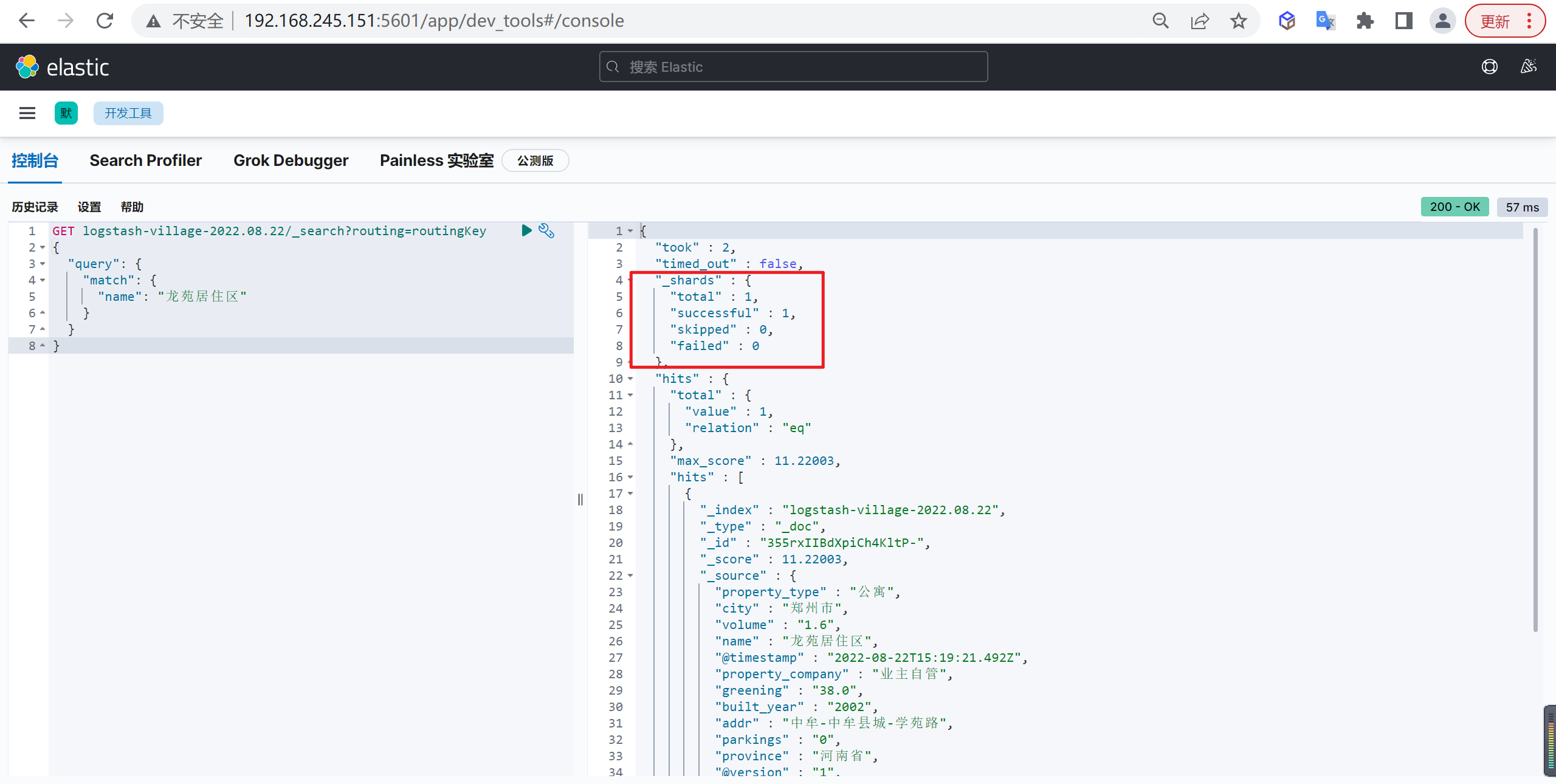
这样我们发现,查询只查询了一个分片,这样查询效率会更高,但是我们写入的时候是通过
_id写入的,查询的时候通过指定路由键,有些数据会查询不出来的,比如
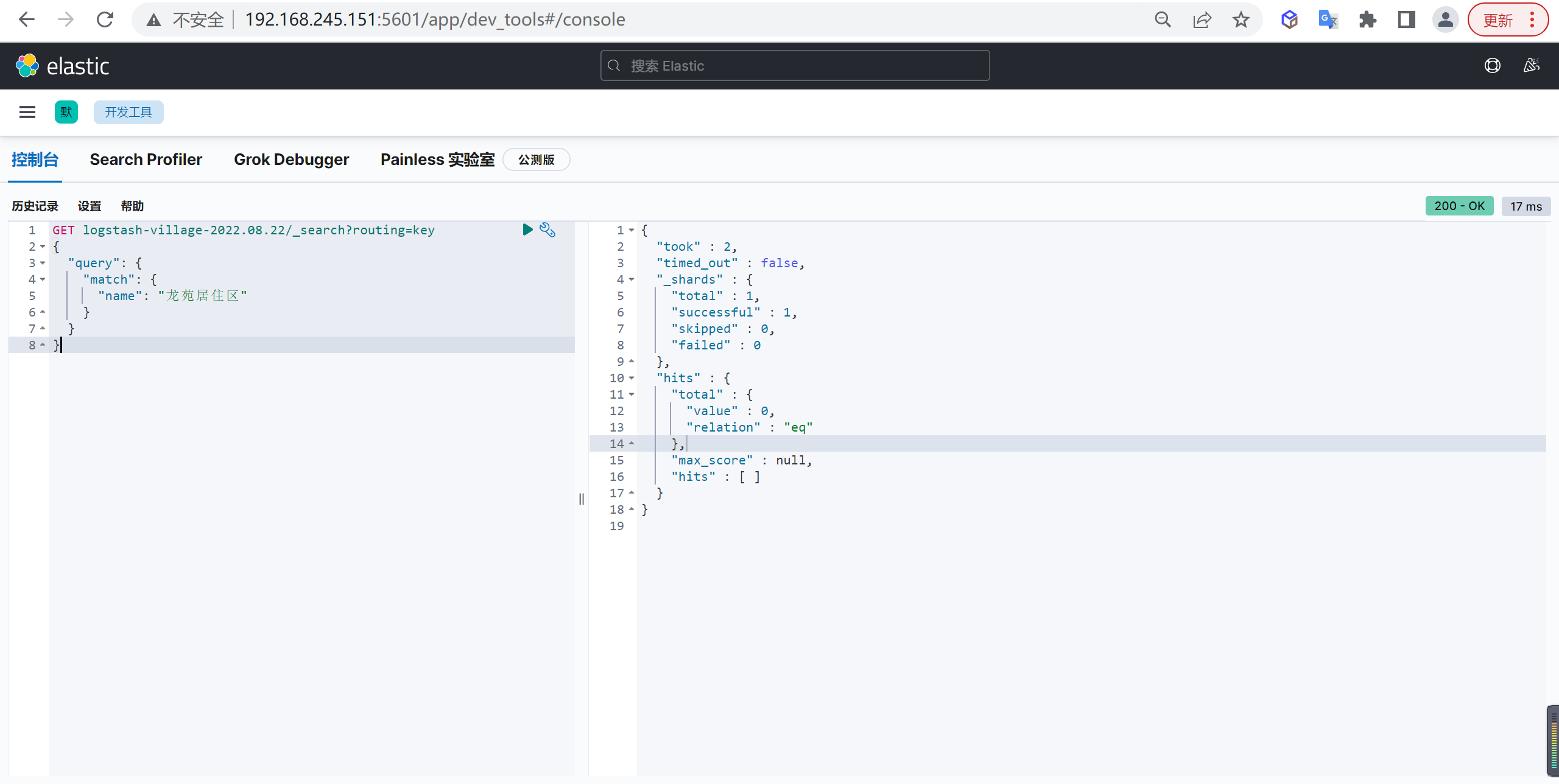
1 | GET logstash-village-2022.08.22/_search?routing=key |
这样直接搜索是查不到数据的,根据
key路由键定位的分片是没有数据的,如何解决呢,就需要写和读都是用相同的路由键,再写入的时候也指定路由键即可
自定义路由(拓展)
自定义路由的方式非常简单,只需要在插入数据的时候指定路由的key即可,虽然使用简单,但有许多的细节需要注意
创建索引
先创建一个名为route_test的索引,该索引有3个shard,0个副本
1 | PUT route_test/ |
查看分片
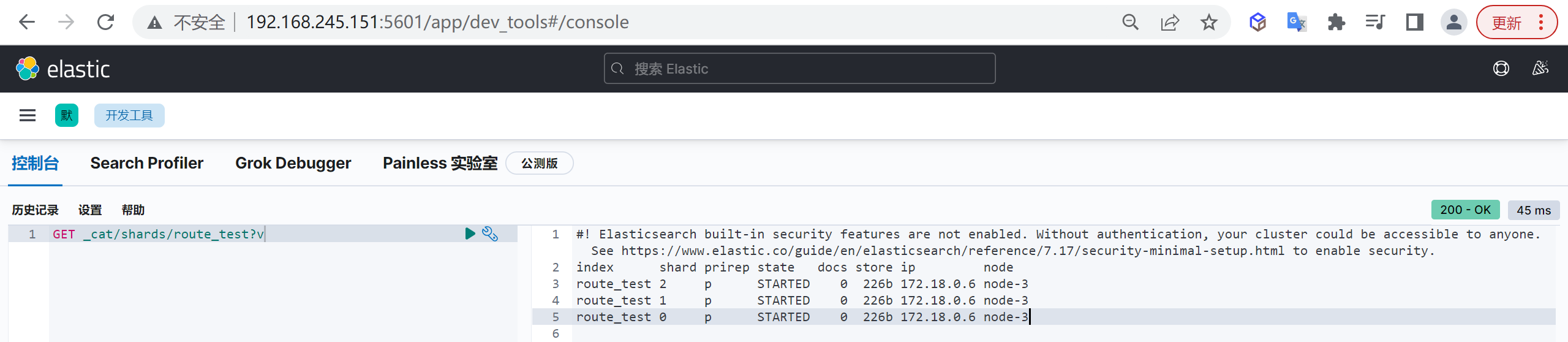
我们接下来查看以下分片信息
1 | GET _cat/shards/route_test?v |
插入数据
接下来我们就需要插入数据
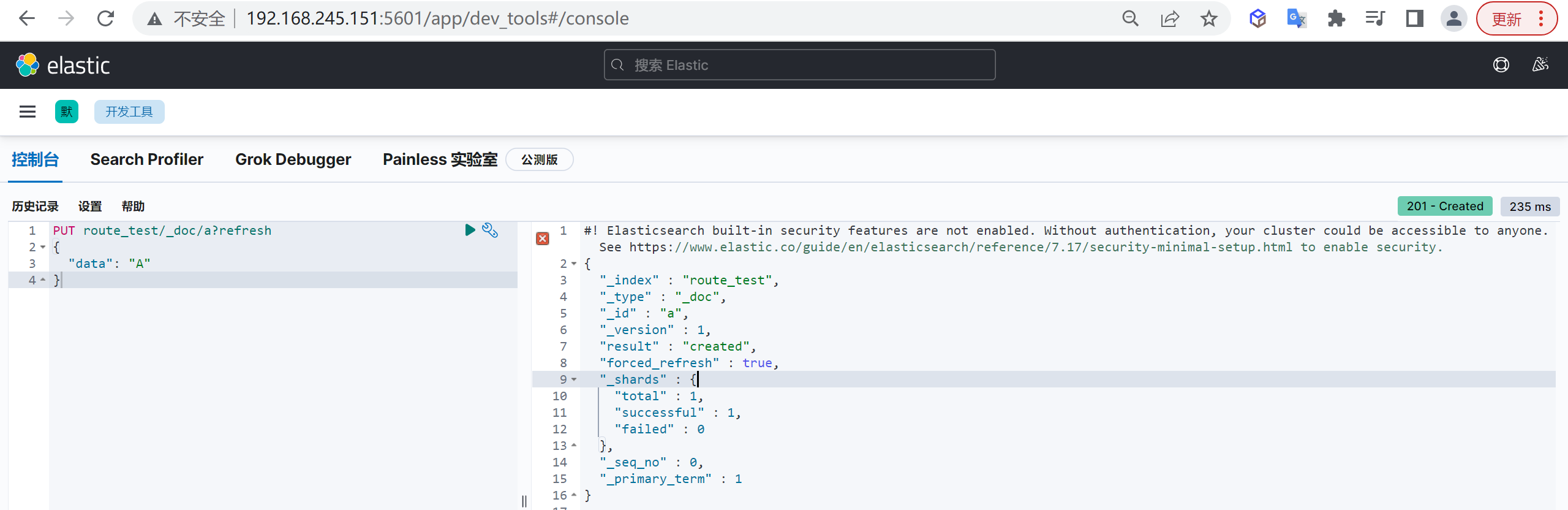
插入第一条数据
1 | PUT route_test/_doc/a?refresh |
查看分片
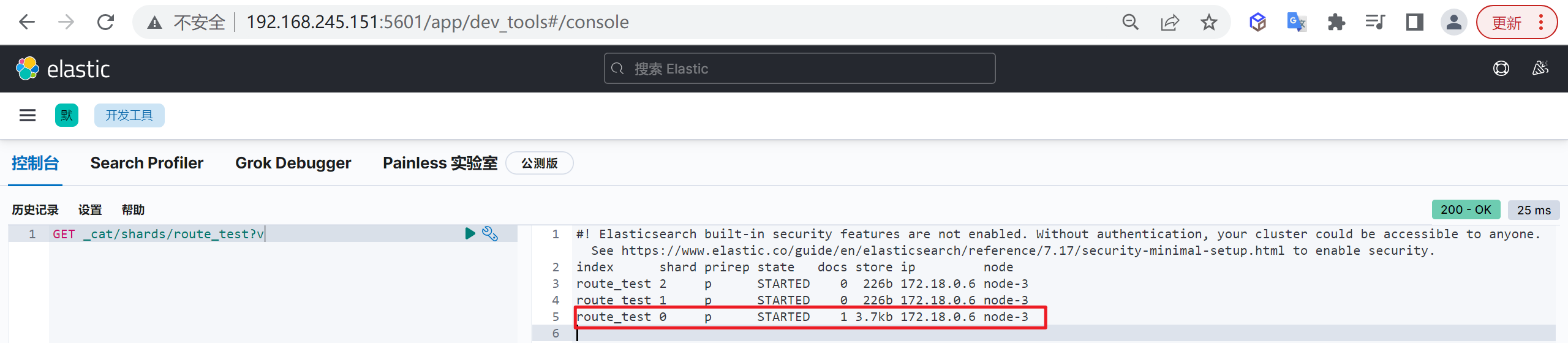
我们插入数据后再次来查看分片信息
1 | GET _cat/shards/route_test?v |
我们发现我们插入的数据加入了0分片
插入第二条数据
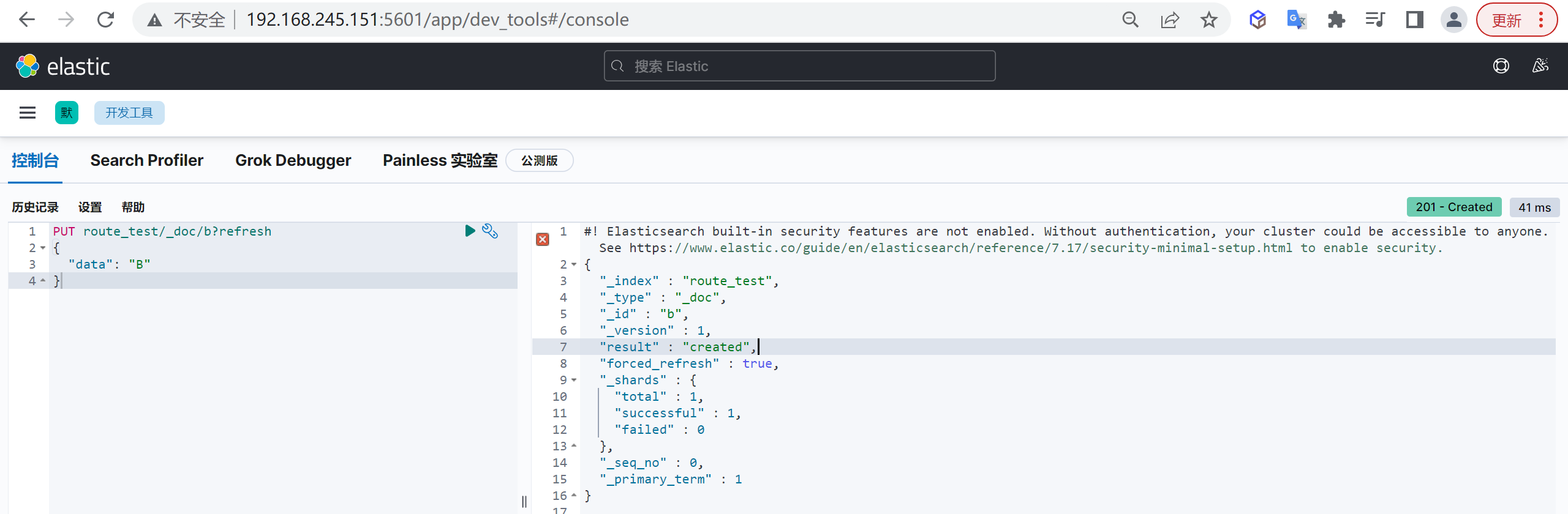
接下来我们插入第二条数据
1 | PUT route_test/_doc/b?refresh |
查看分片
我们插入数据后再次来查看分片信息
1 | GET _cat/shards/route_test?v |
我们发现我们插入的数据加入了2分片
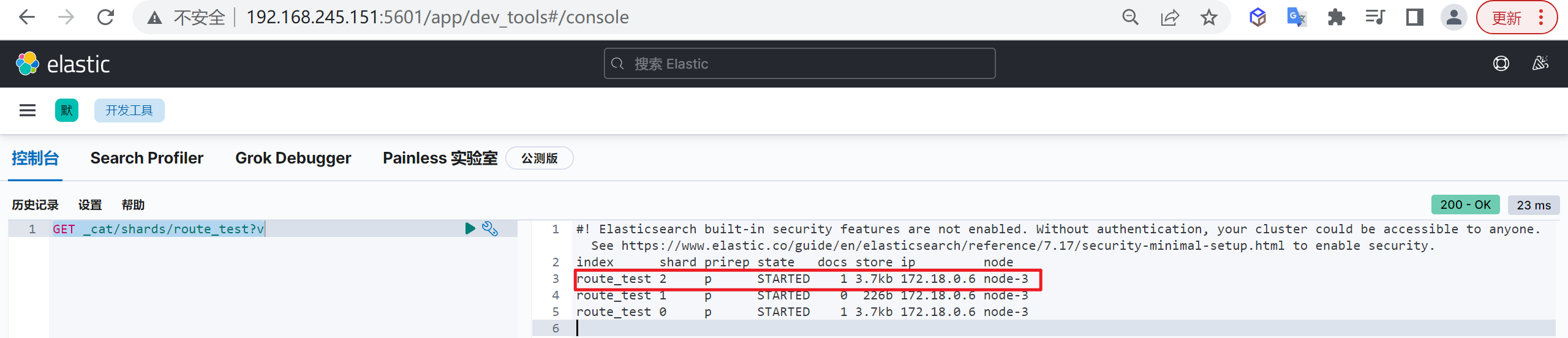
查询数据
接下来我们查询数据
1 | GET route_test/_search |
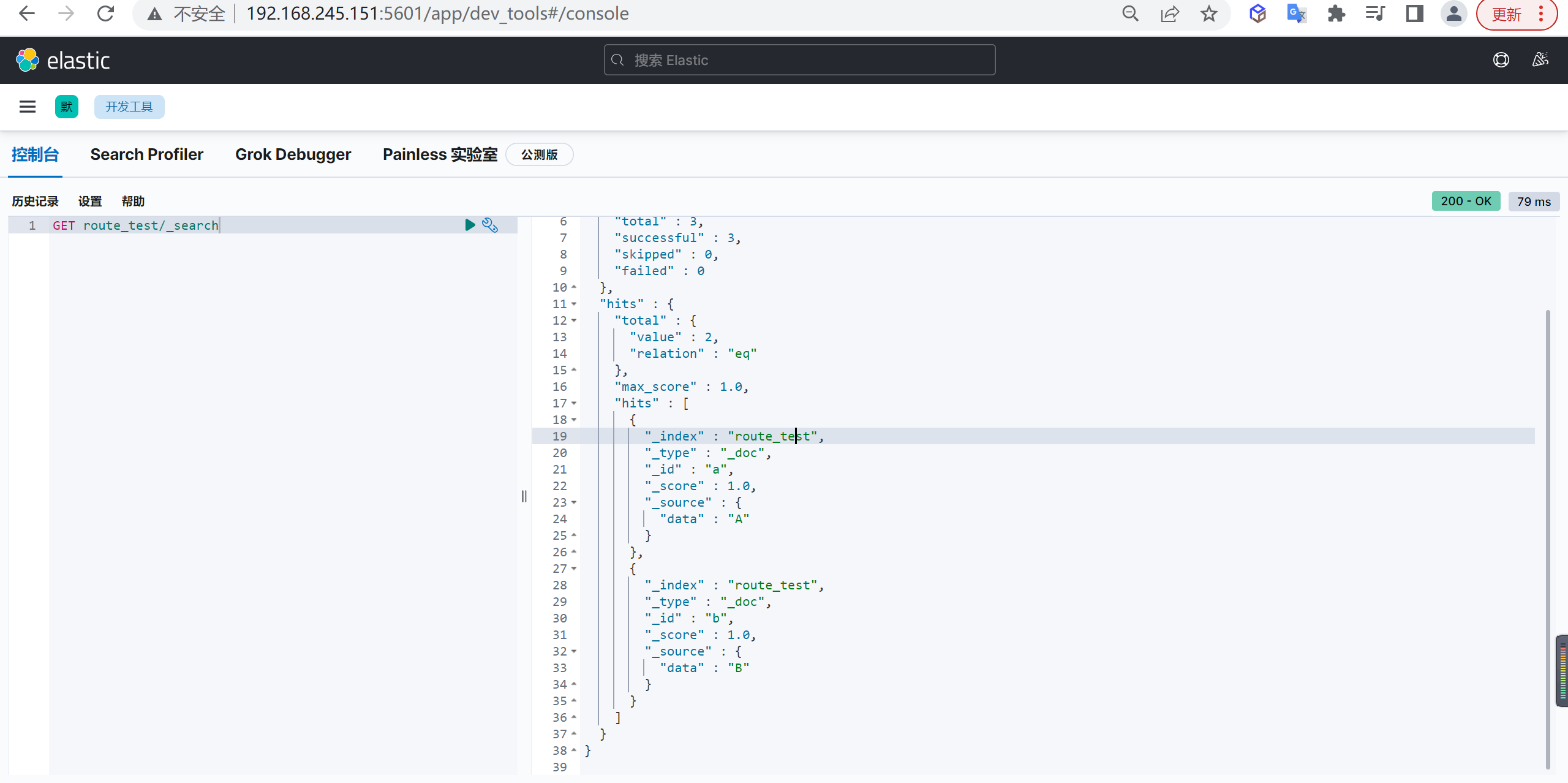
上面这个例子比较简单,先创建了一个拥有3个shard,0个副本(为了方便观察)的索引 route_test ,创建完之后查看两个shard的信息,此时shard为空,里面没有任何文档(docs 列为0)。
接着我们插入了两条数据,每次插完之后,都检查shard的变化,通过对比可以发现 docid=a 的第一条数据写入了0号shard,docid=b 的第二条数据写入了2号 shard。
需要注意的是这里的doc_id我选用的是字母”a”和”b”,而非数字,原因是连续的数字很容易路由到一个shard中去,以上的过程就是不指定routing时候的默认行为。
指定路由
接着,我们指定routing,看看会发生什么
插入第三条数据
接下来我们插入第三条数据,但是这条数据我们加上一个路由键
1 | PUT route_test/_doc/c?routing=key1&refresh |
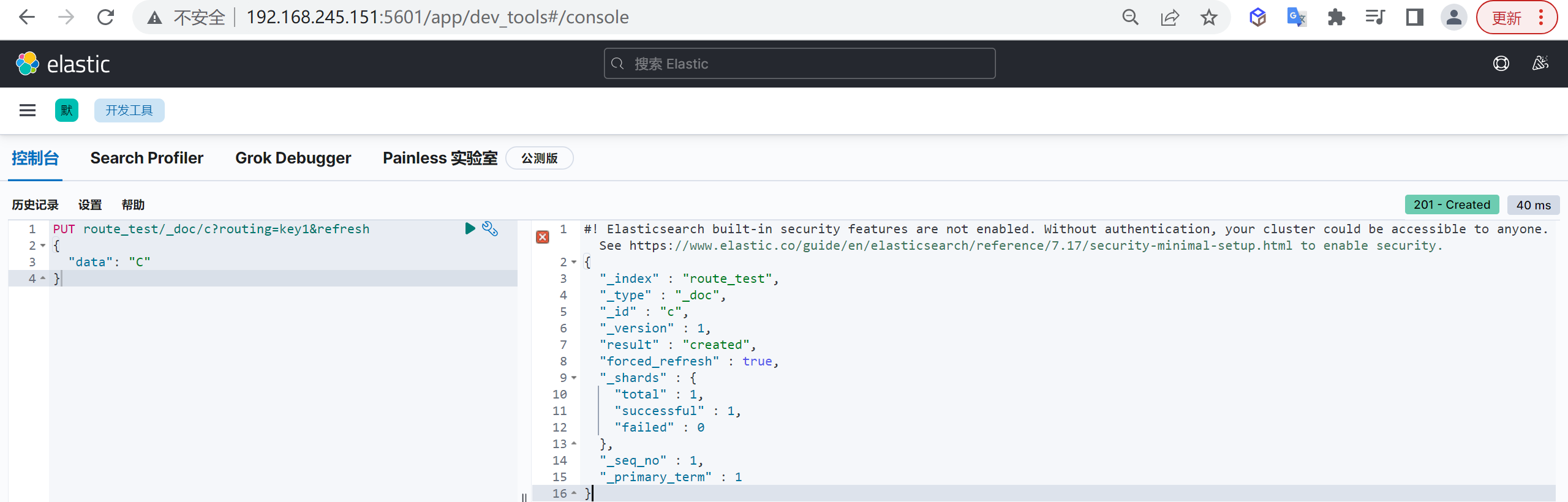
查看分片
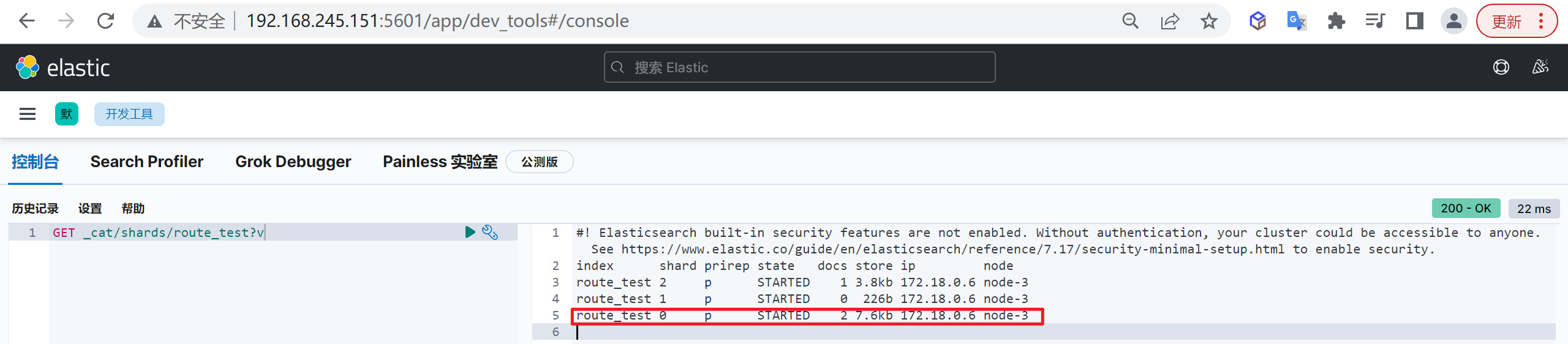
我们插入数据后再次来查看分片信息
1 | GET _cat/shards/route_test?v |
我们发现我们插入的数据加入了0分片
查询索引数据
1 | GET route_test/_search |
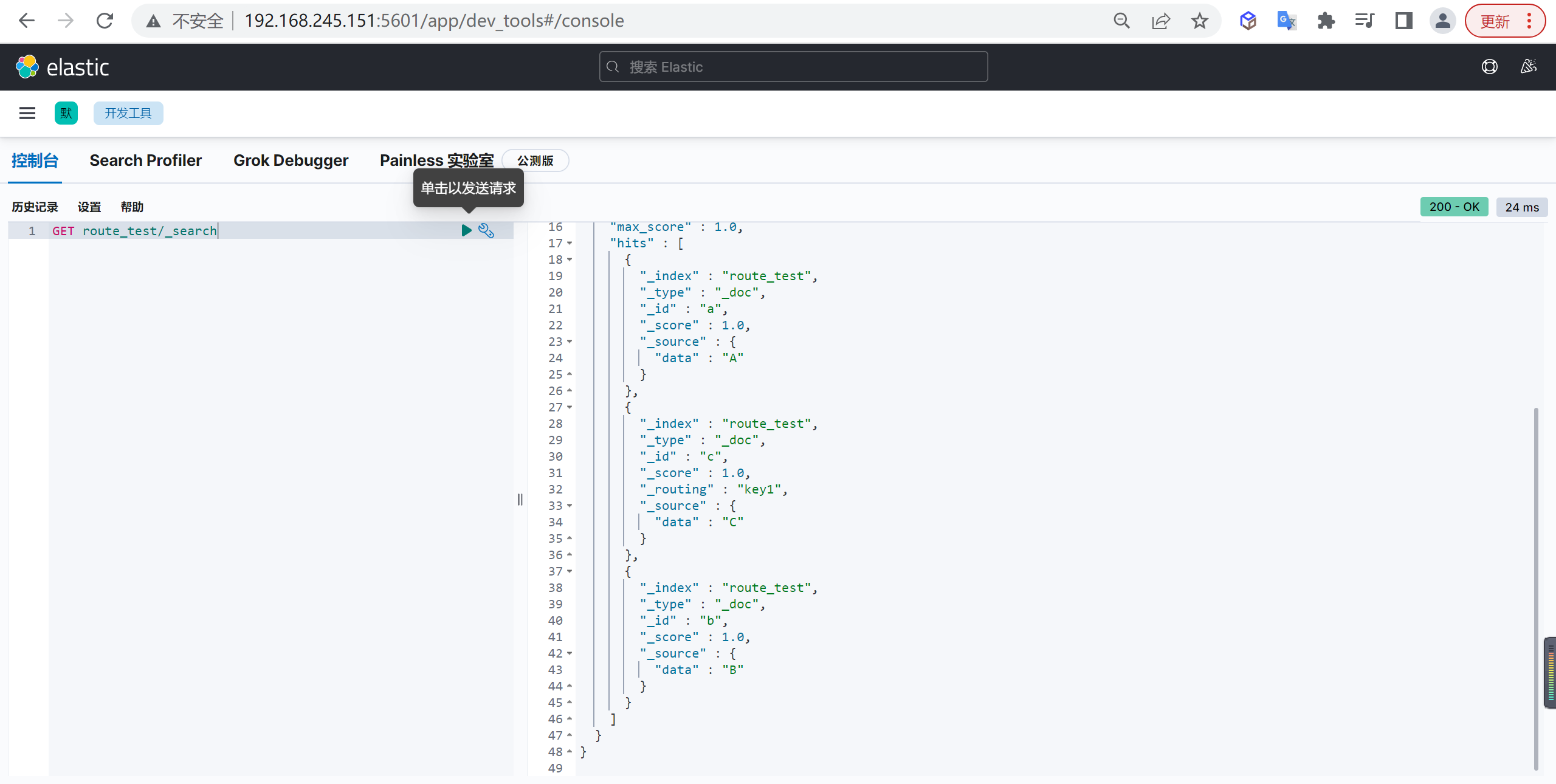
我们又插入了1条 docid=c 的新数据,但这次我们指定了路由,路由的值是一个字符串”key1”,通过查看shard信息,能看出这条数据路由到了0号shard,也就是说用”key1”做路由时,文档会写入到0号shard。
指定路由插入
接着我们使用该路由再插入两条数据,但这两条数据的 docid 分别为之前使用过的 “a”和”b”
再次插入数据
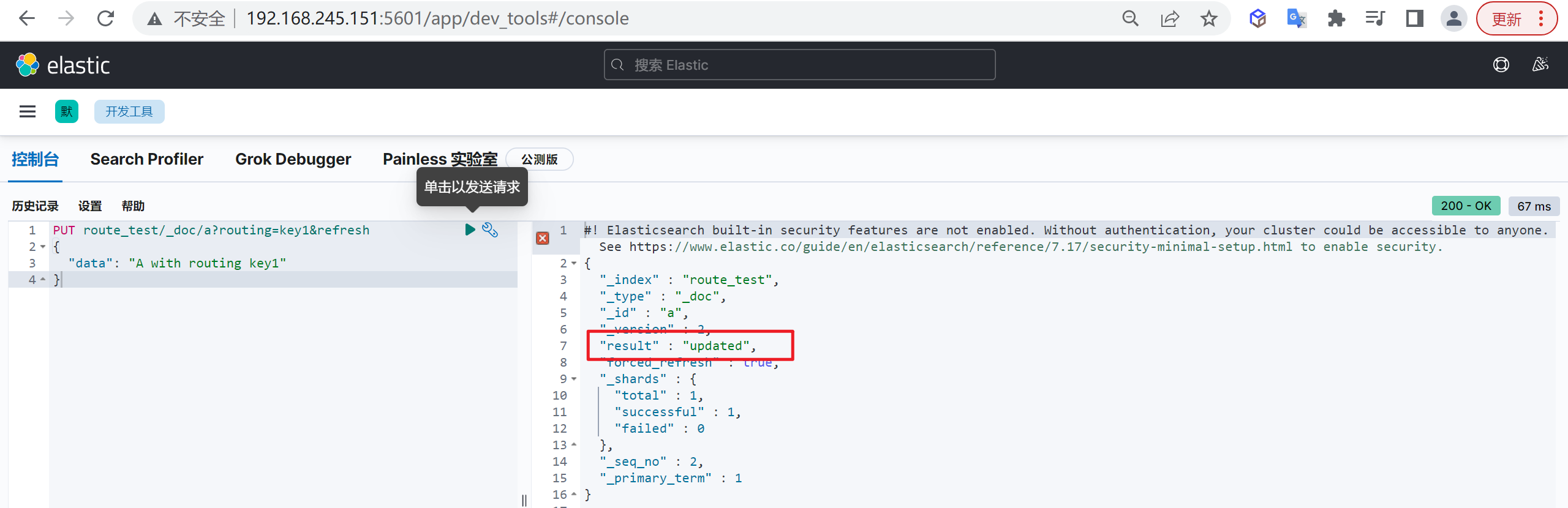
插入 docid=a 的数据,并指定 routing=key1
1 | PUT route_test/_doc/a?routing=key1&refresh |
注意返回的状态为updated,之前的三次插入返回都为created
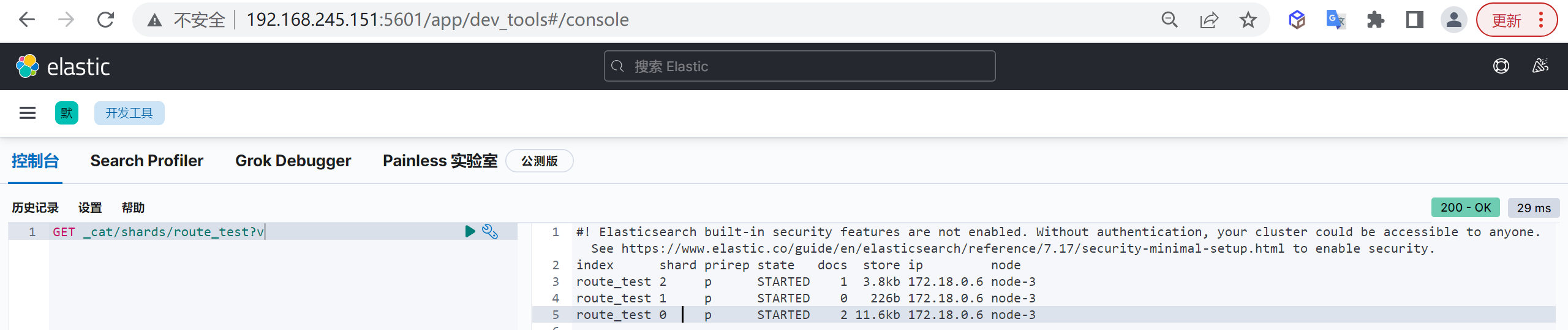
查看分片
我们插入数据后再次来查看分片信息
1 | GET _cat/shards/route_test?v |
我们发现分片的数据没有变化
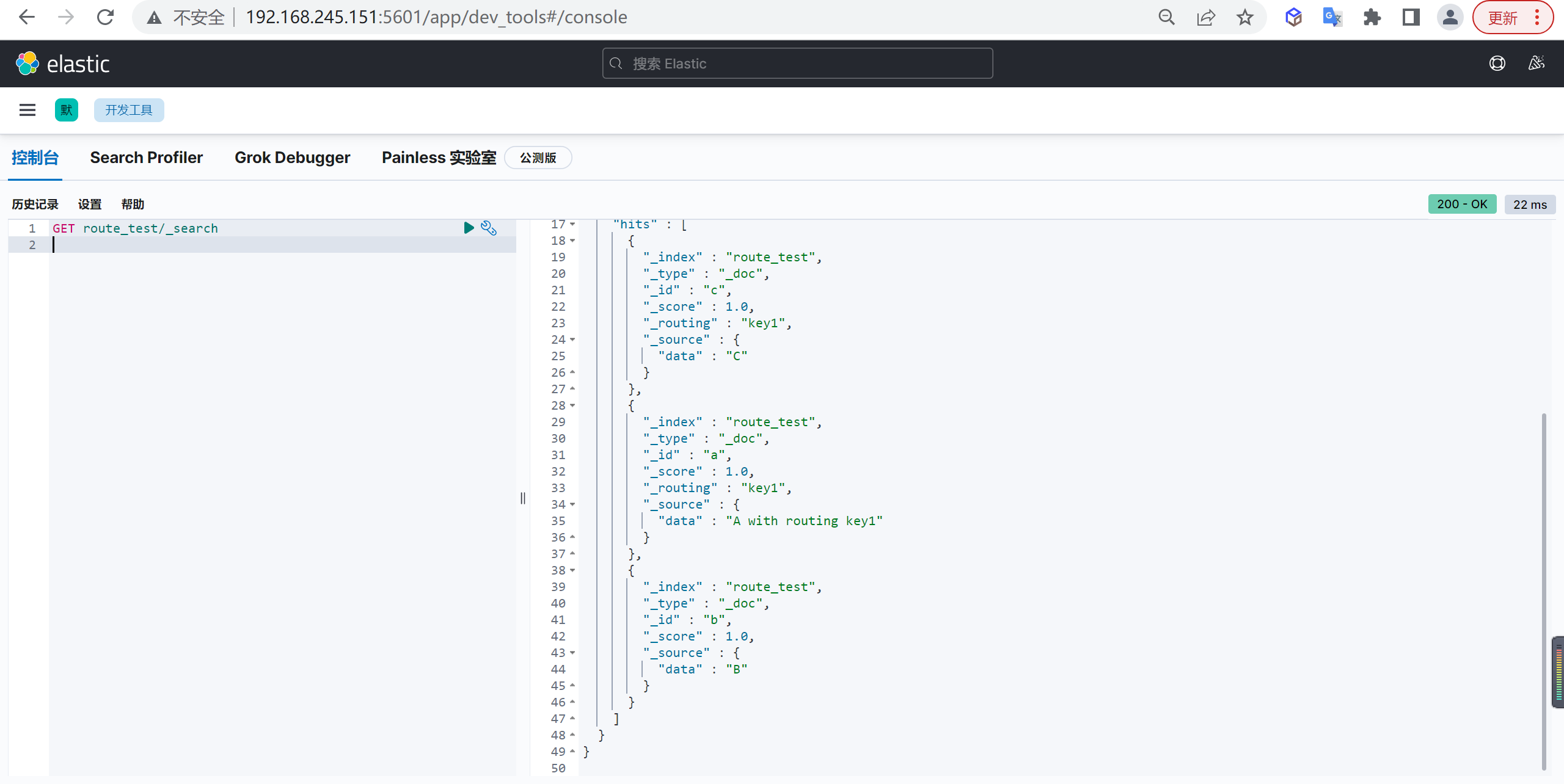
查询数据
1 | GET route_test/_search |
之前 docid=a 的数据就在0号shard中,这次依旧写入到0号shard中了,因为docid重复,所以文档被更新了
再次插入数据
这次插入 docid=b的数据,使用key1作为路由字段的值
1 | PUT route_test/_doc/b?routing=key1&refresh |
我们发现这次变成创建了
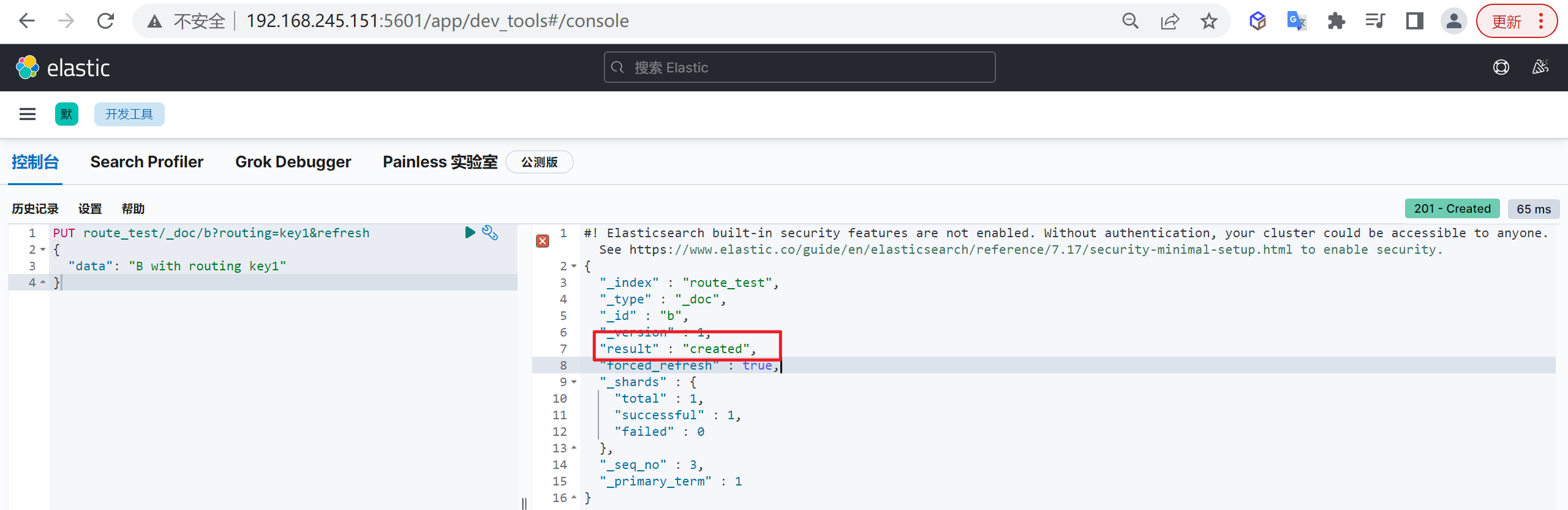
查看分片信息
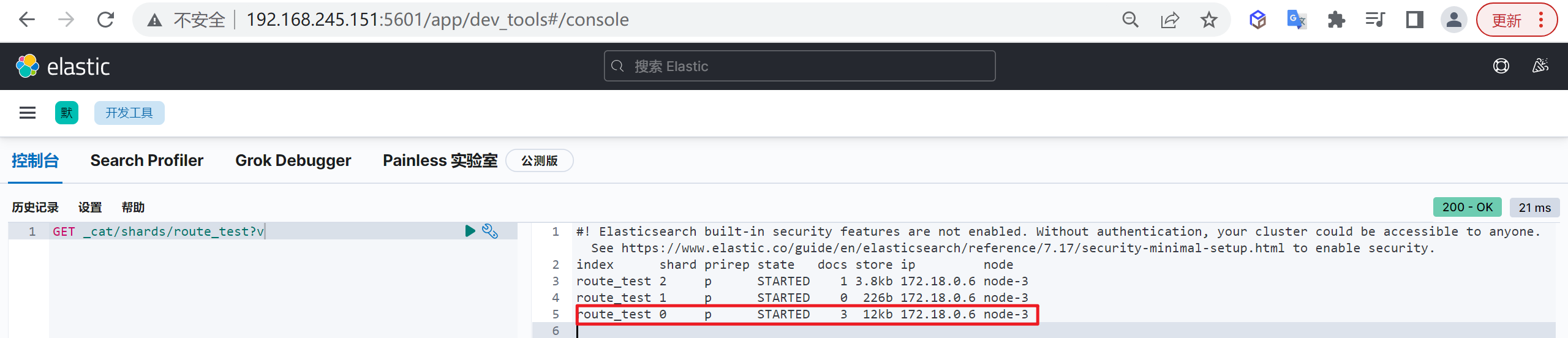
我们再次查看分片信息
1 | GET _cat/shards/route_test?v |
我们发现数据存储到了0分片中
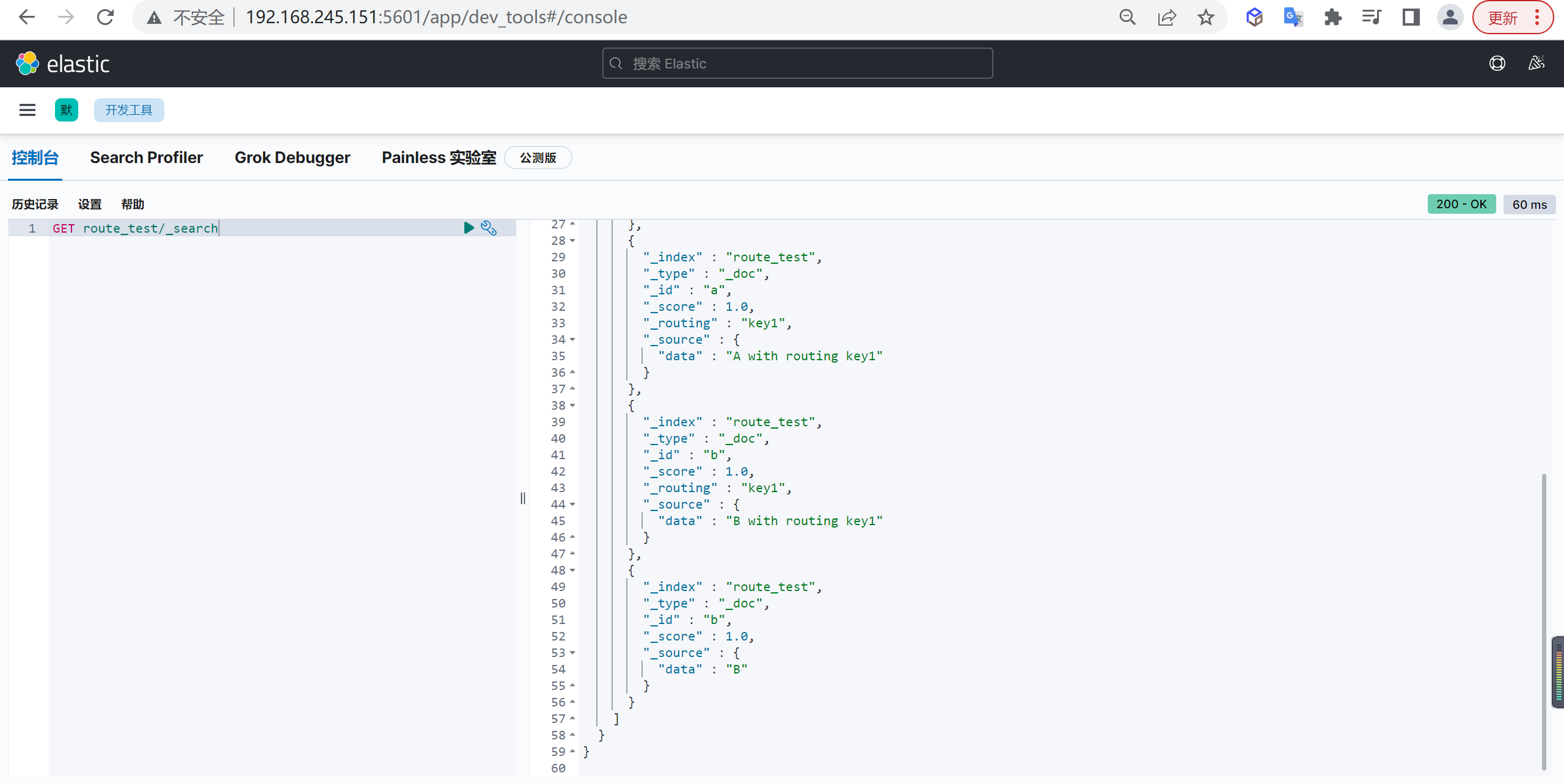
查询数据
我们再次来查询数据
1 | GET route_test/_search |
和上面插入
docid=a的那条数据相比,这次这个有些不同,我们来分析一下
路由带来的问题
这个就是我们自定义routing后会导致的一个问题:docid不再全局唯一
ES shard的实质是Lucene的索引,所以其实每个shard都是一个功能完善的倒排索引,ES能保证docid全局唯一是采用docid作为了路由,所以同样的docid肯定会路由到同一个shard上面,如果出现docid重复,就会update或者抛异常,从而保证了集群内docid唯一标识一个doc。
但如果我们换用其它值做routing,那这个就保证不了了,如果用户还需要docid的全局唯一性,那只能自己保证了,因为docid不再全局唯一,所以doc的增删改查API就可能产生问题
索引别名
别名,有点类似数据库的视图,别名一般都会和一些过滤条件相结合,可以做到即使是同一个索引上,让不同人看到不同的数据
别名的作用
在开发中,一般随着业务需求的迭代,较老的业务逻辑就要面临更新甚至是重构,对于es来说为了适应新的业务逻辑,就要对原有的索引做一些修改,比如对某些字段做调整
而做这些操作的时候,可能会对业务造成影响,甚至是停机调整等问题,因为es提供了索引的别名来解决这个问题,索引的别名就像一个快捷方式或者是软连接,可以指向一个或者多个索引,也可以给任意一个需要索引名的API来使用
别名操作
下面我们看下别名的基本操作
查询别名
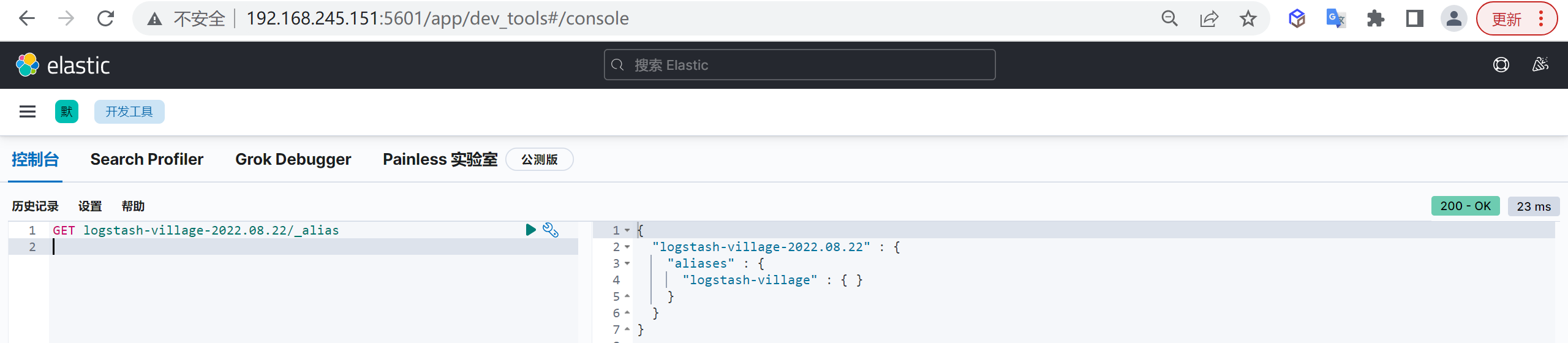
直接调用
_aliasAPI的GET方法可以看到索引的别名
1 | GET logstash-village-2022.08.22/_alias |
我们看到现在可以看到当前的索引有一个别名
logstash-village
别名查询
我们查询的时候可以指定别名进行查询
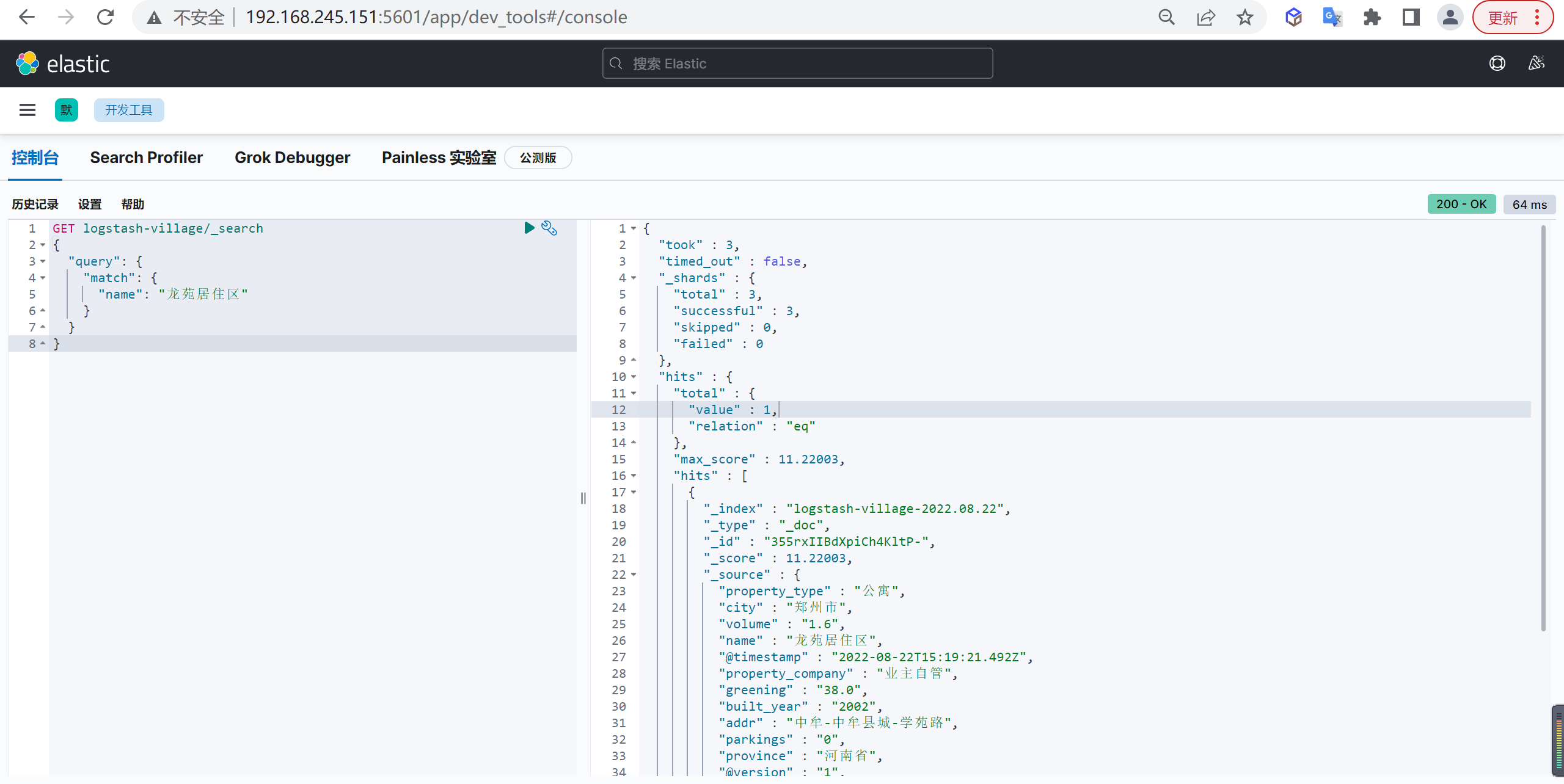
1 | GET logstash-village/_search |
这样我们可以通过别名查询出来数据的
创建别名
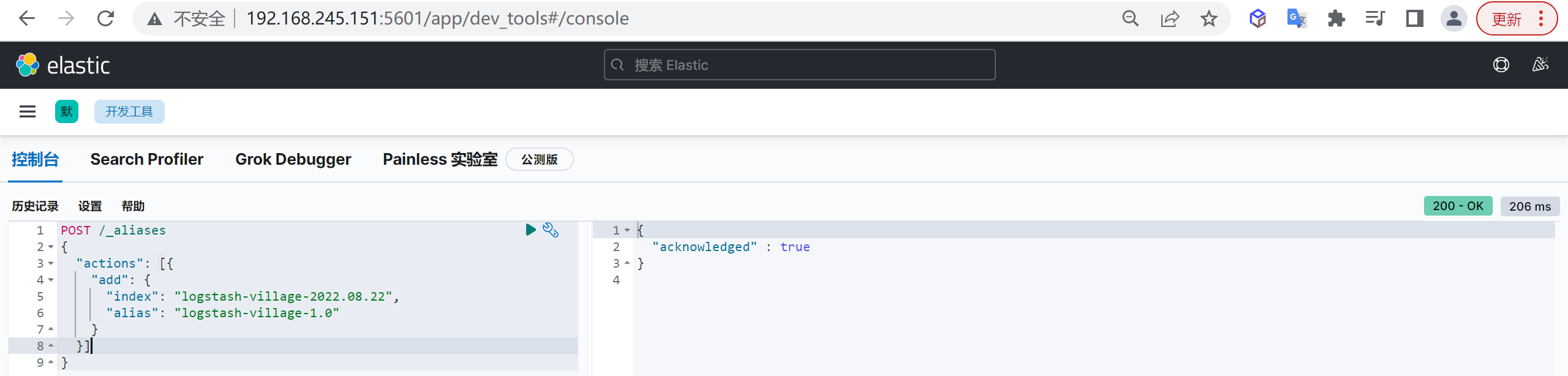
我们还可以在建立一个别名,别名和索引的关系是多对多的关系,一个索引可以有多个别名,同样一个别名也可以有多个索引
1 | POST /_aliases |
这样我们就创建了一个别名
logstash-village-1.0
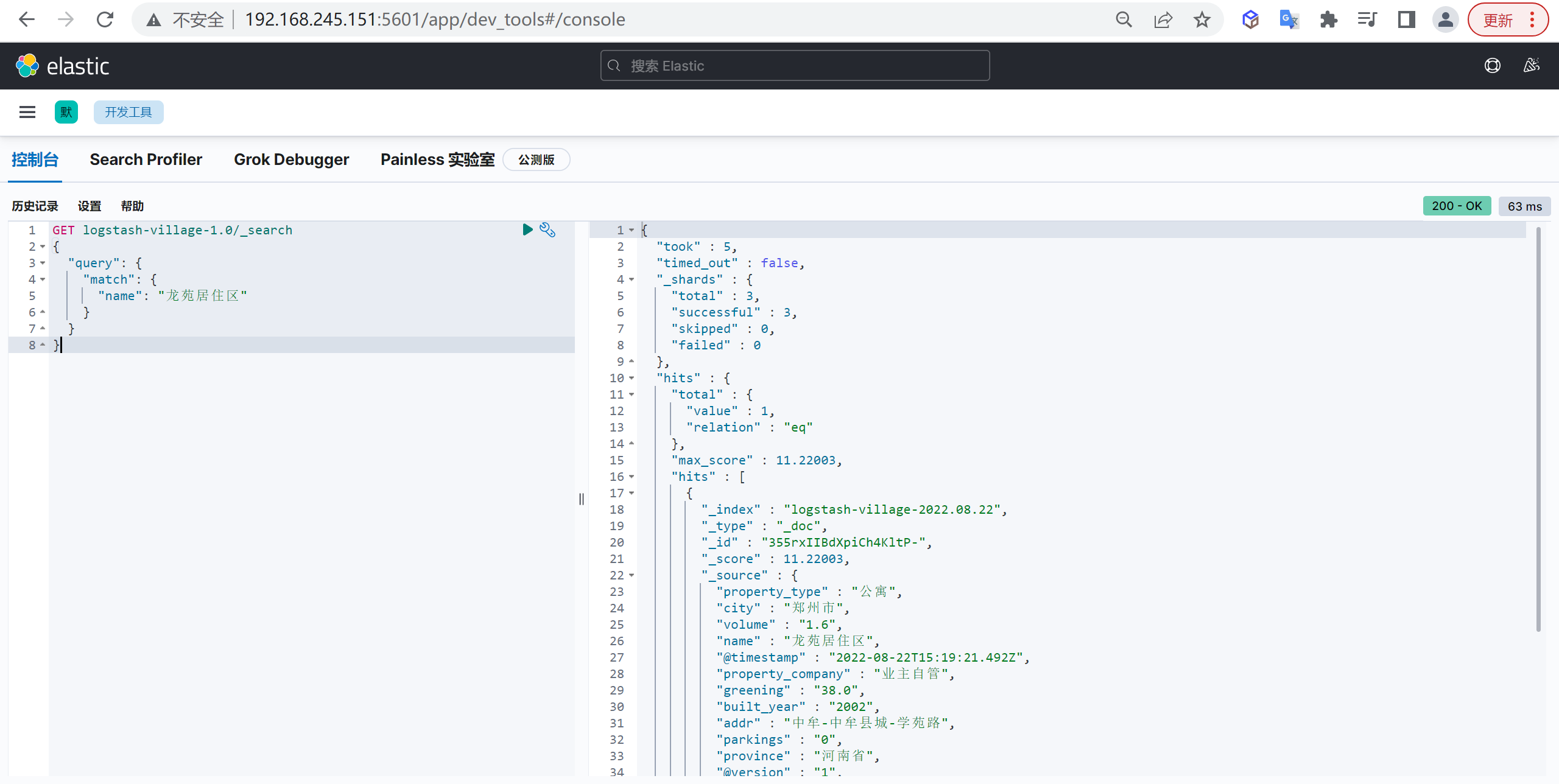
接下来我们直接进行别名查询就好
1 | GET logstash-village-1.0/_search |
这样就检索出来数据了
别名修改
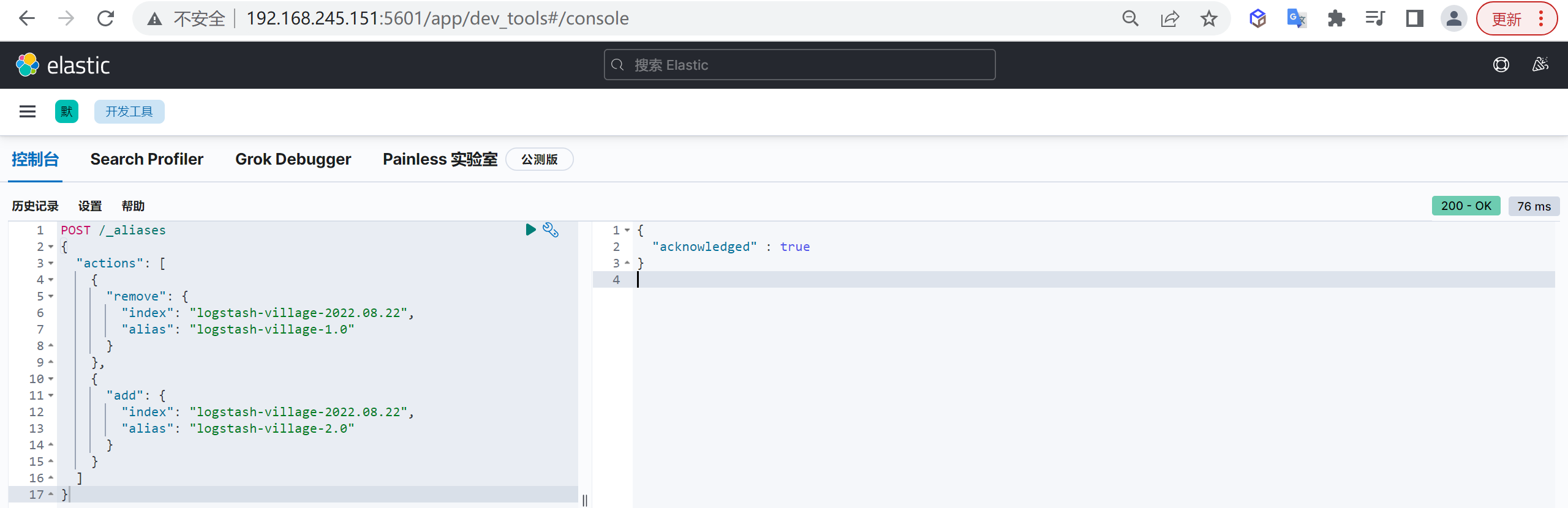
有时候还需要修改别名,特别是涉及到索引迁移的时候,修改操作我们可以实现运行中的es集群无缝切换索引,我们可以将索引指向一个新准备的别名中,也可以为别名关联新的索引
1 | POST /_aliases |
这样我们就可以做到无缝的索引别名修改了
我们再来查询试试
1 | GET logstash-village-2.0/_search |
过滤器别名
我们可以创建一个带过滤器的别名,这样别人通过这个别名查询的时候,数据都是筛选过后的数据,起到一个数据权限的作用
创建别名
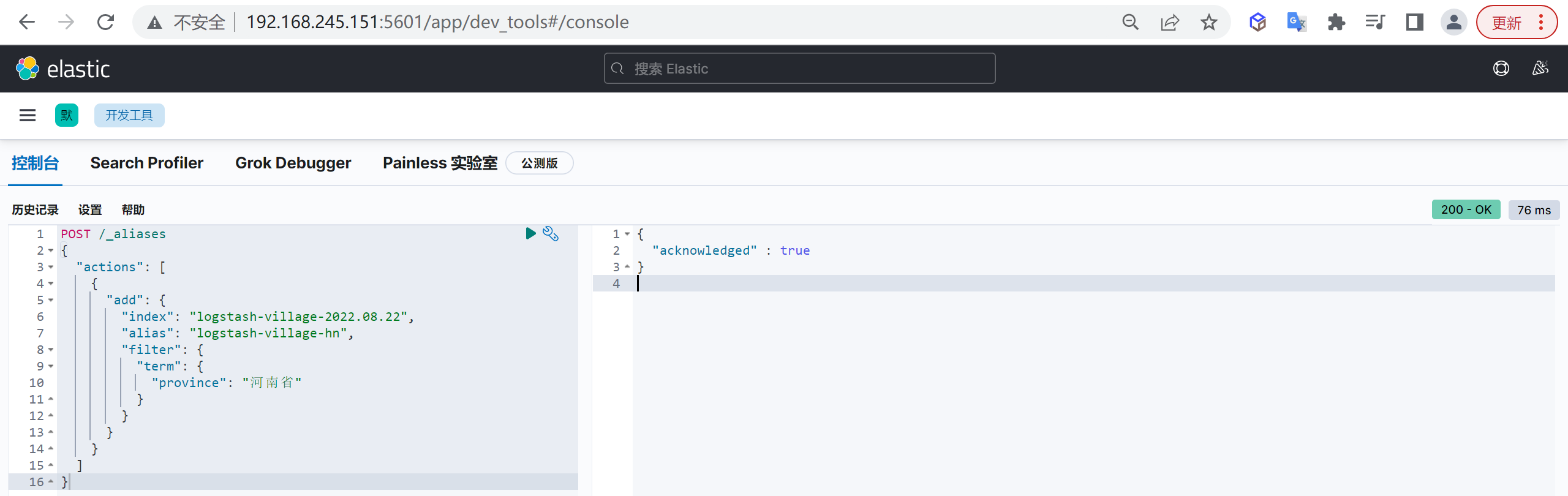
下面我们创建一个只能查询河南省房产信息的别名
1 | POST /_aliases |
这样我们就创建了一个只能查询到河南省房产信息的别名
logstash-village-hn
数据查询
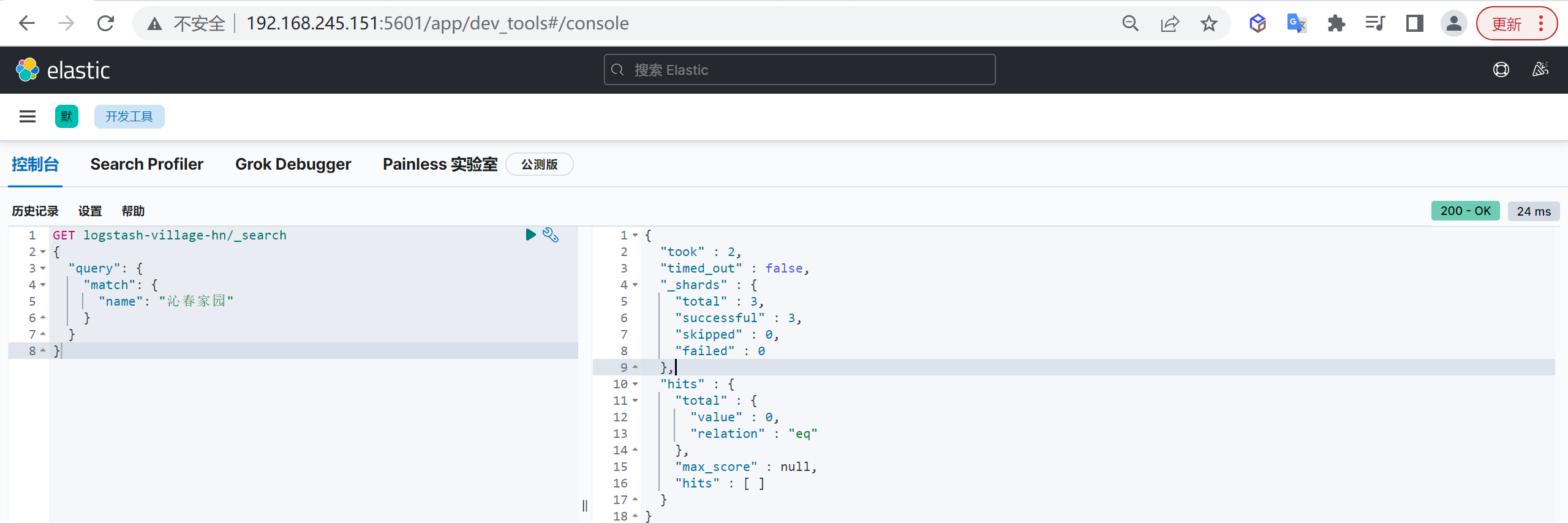
下面我们通过这个别名查询北京
沁春家园的小区信息
1 | GET logstash-village-hn/_search |
我们发现根本就查询不出来
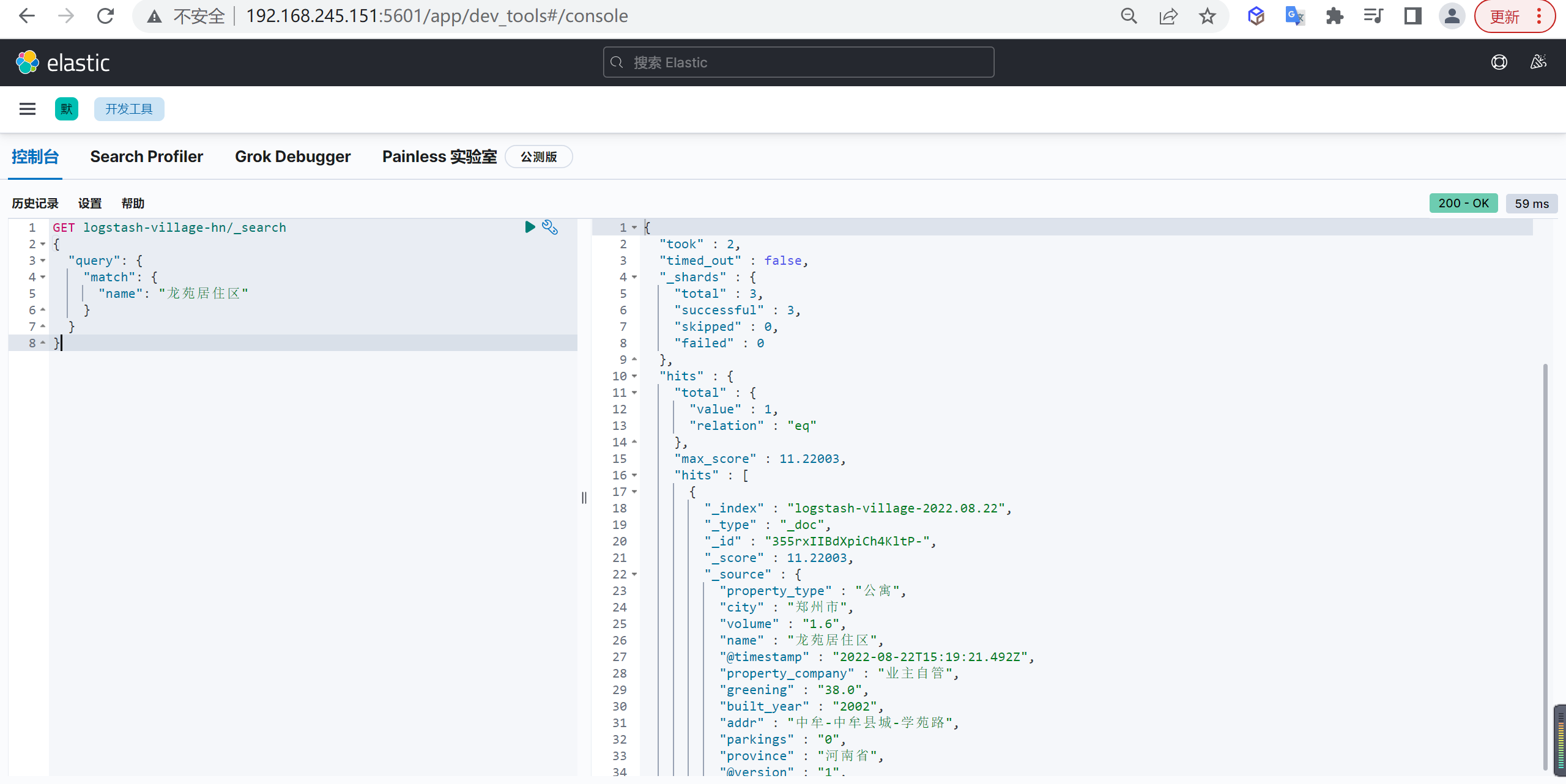
但是我们查询
龙苑居住区却可以查询出来
路由别名
我们上面介绍了路由的使用,但是有一个问题,我们查询的时候都需要携带路由参数,很麻烦,我们可以将我们的路由参数写进别名中,这样查询起来会更加方便
创建别名
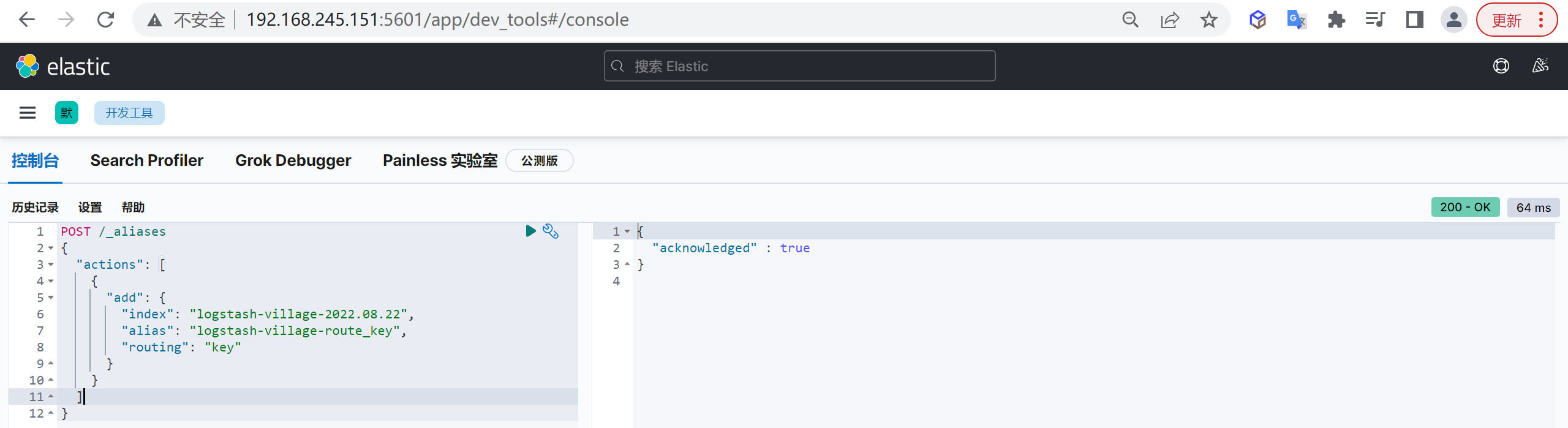
下面我们就创建一个以
key为路由键
1 | POST /_aliases |
这样我们就以
key为路由键创建了一个索引
数据查询
下面我们就对索引进行一些查询
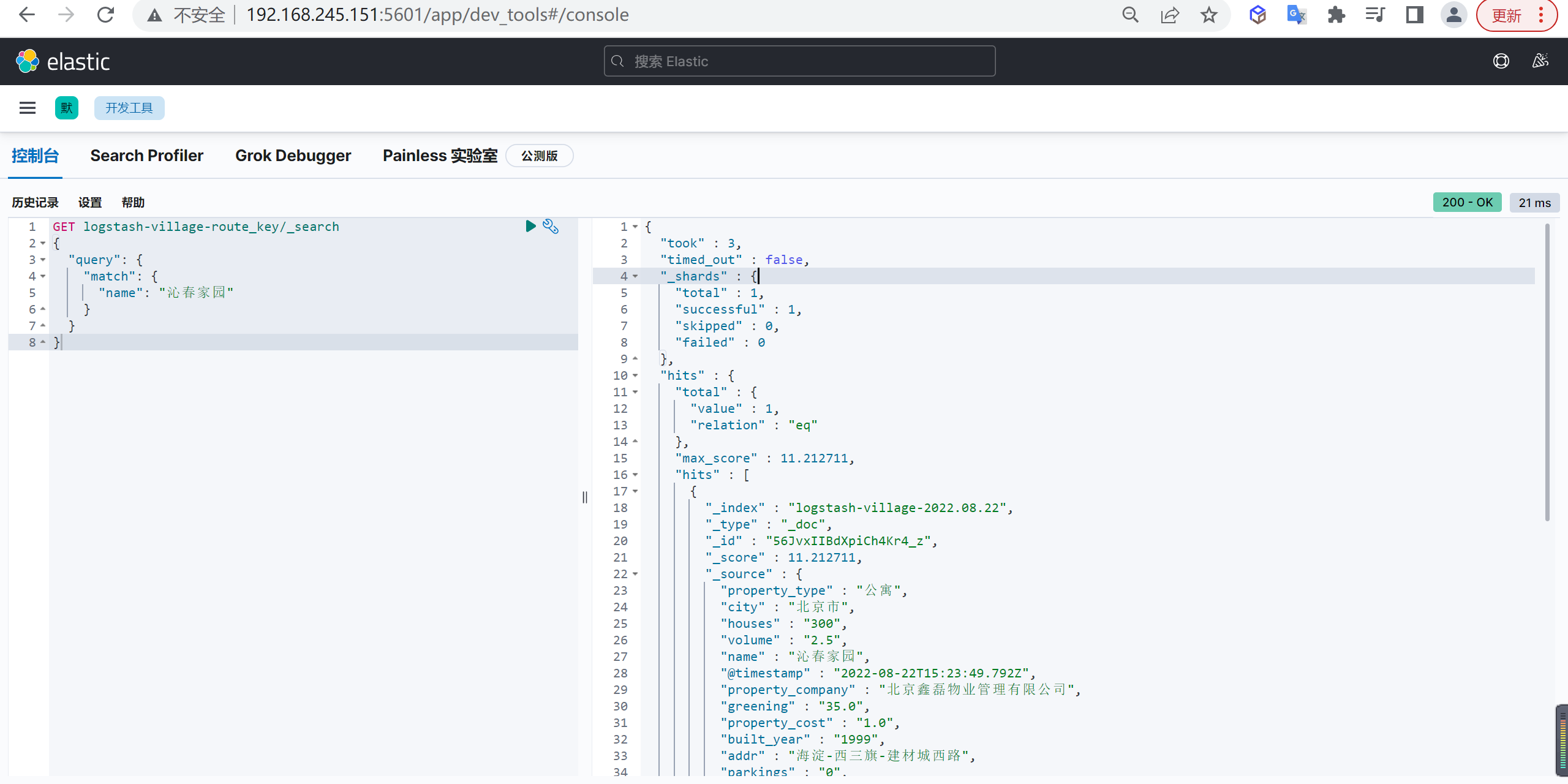
1 | GET logstash-village-route_key/_search |
我们看到查询
沁春家园是可以查询出来数据的,但是查询龙苑居住区是查询不出来数据的
删除别名
创建了很多的别名,有时候别名不用了,需要定期删除以下
查看所有别名
现在我们查询以下当前索引下的别名有哪些
1 | GET logstash-village-2022.08.22/_alias |
当前有这么多的别名,我们准备删除一些

删除别名
删除的时候直接指定别名就可以的
1 | DELETE logstash-village-2022.08.22/_alias/logstash-village-route_key |
这样我们就把当前这个别名删除了

重建索引
Elasticsearch使用时间长了后,到了后期可能有各种原因重建索引
ES是不支持索引字段类型变更的,不可变的原因是一个字段的类型进行修改之后,ES会重新建立对这个字段的索引信息,影响到ES对该字段分词方式,相关度,TF/IDF倒排索引创建等。
索引重建的步骤
- 创建旧索引
- 给索引创建别名
- 向oldindex中插入数据
- 创建新的索引newindex
- 重建索引
- 实现不重启服务索引的切换
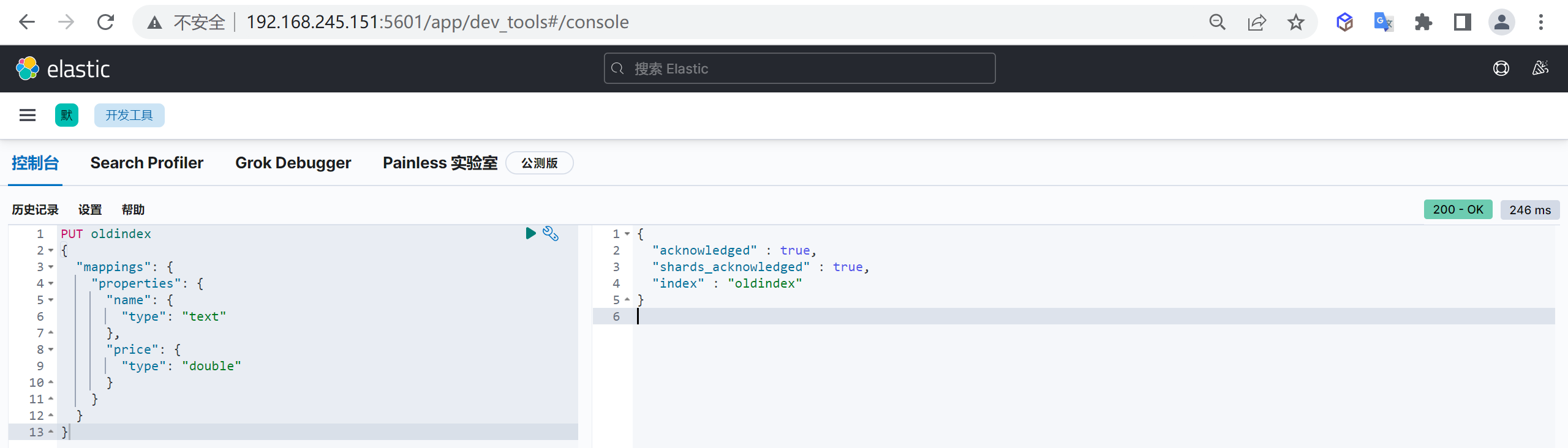
创建旧索引
1 | PUT oldindex |
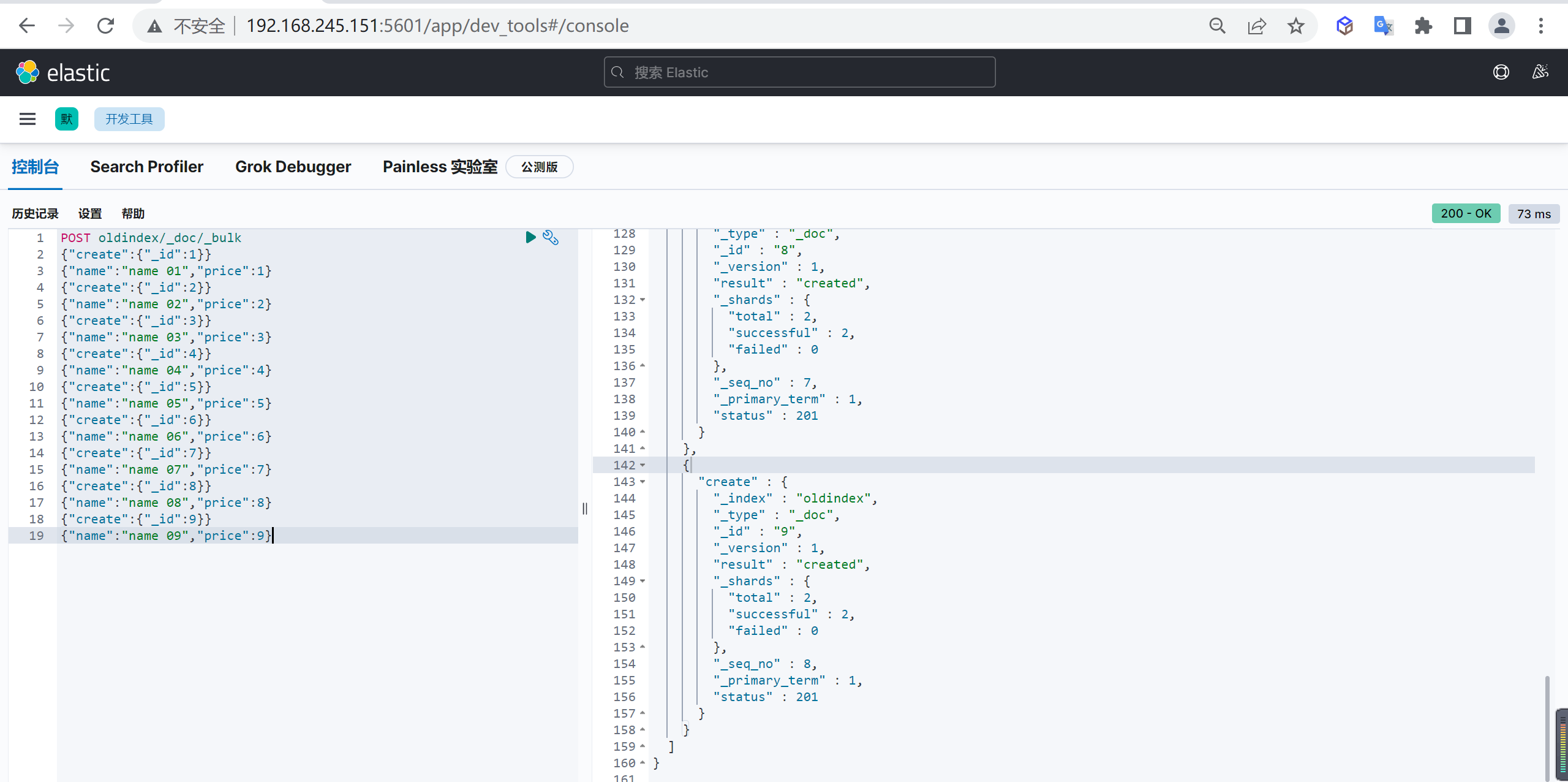
添加数据
1 | POST oldindex/_doc/_bulk |
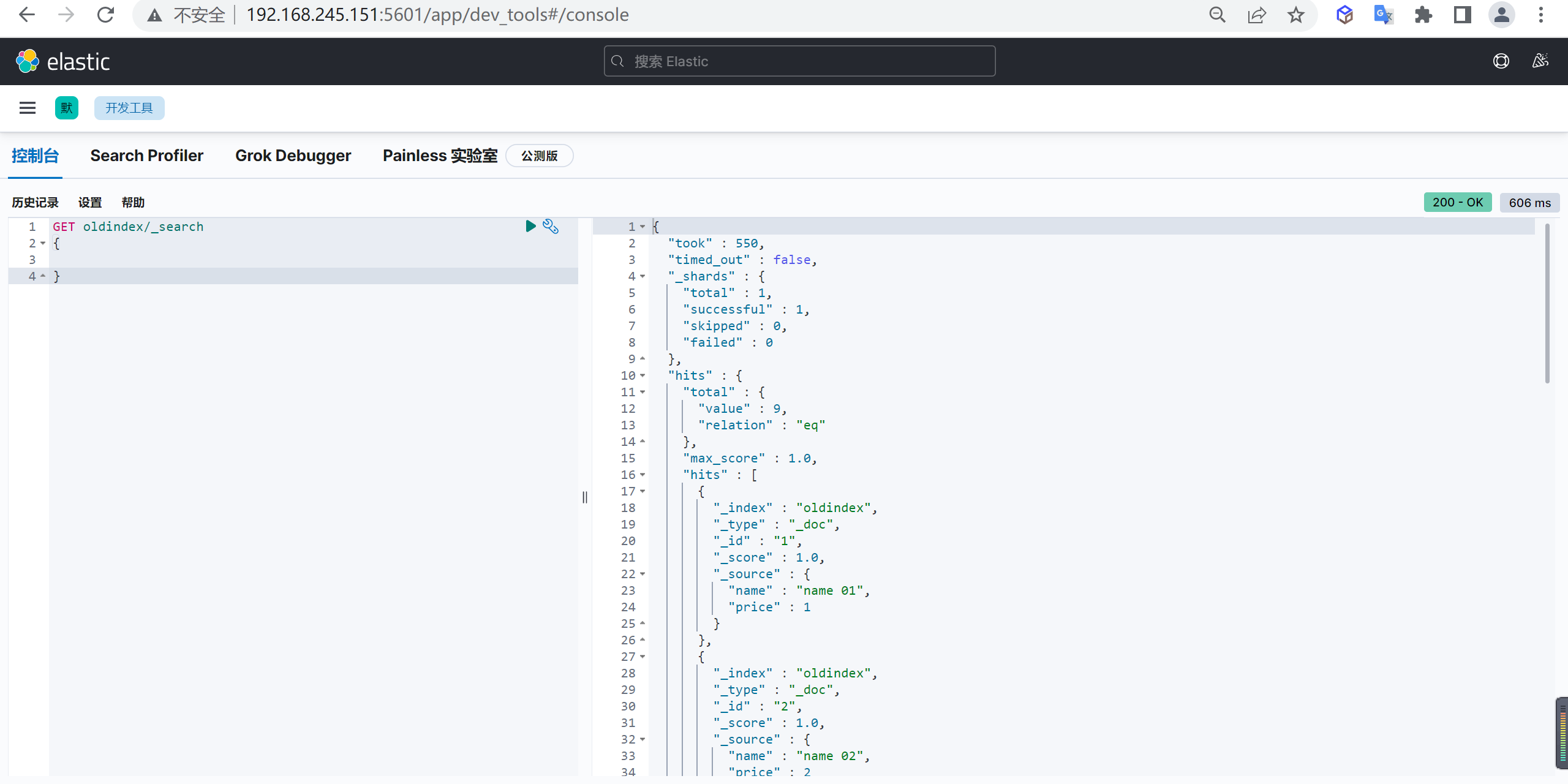
查询数据
1 | GET oldindex/_search |
创建别名
1 | POST /_aliases |
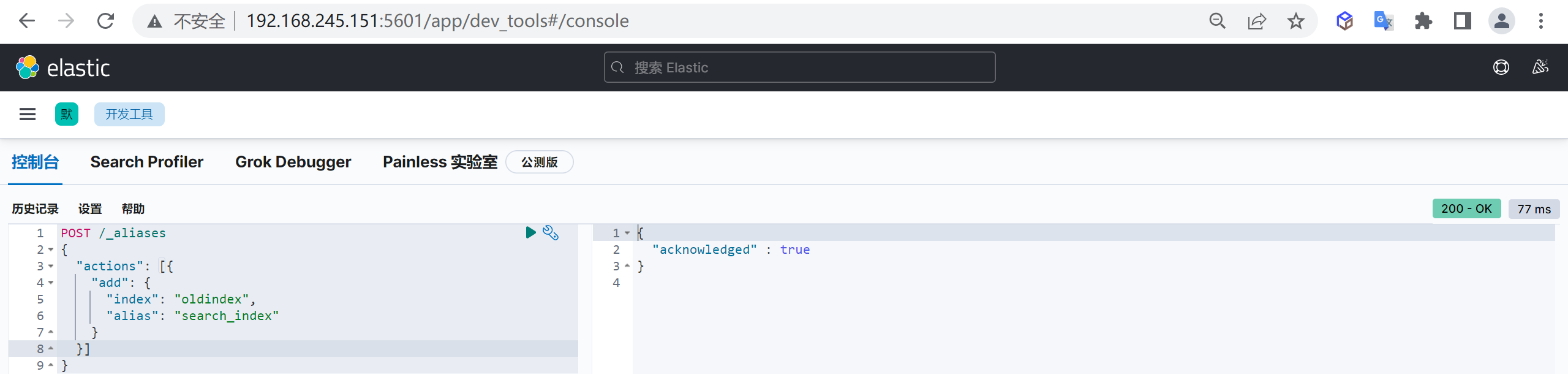
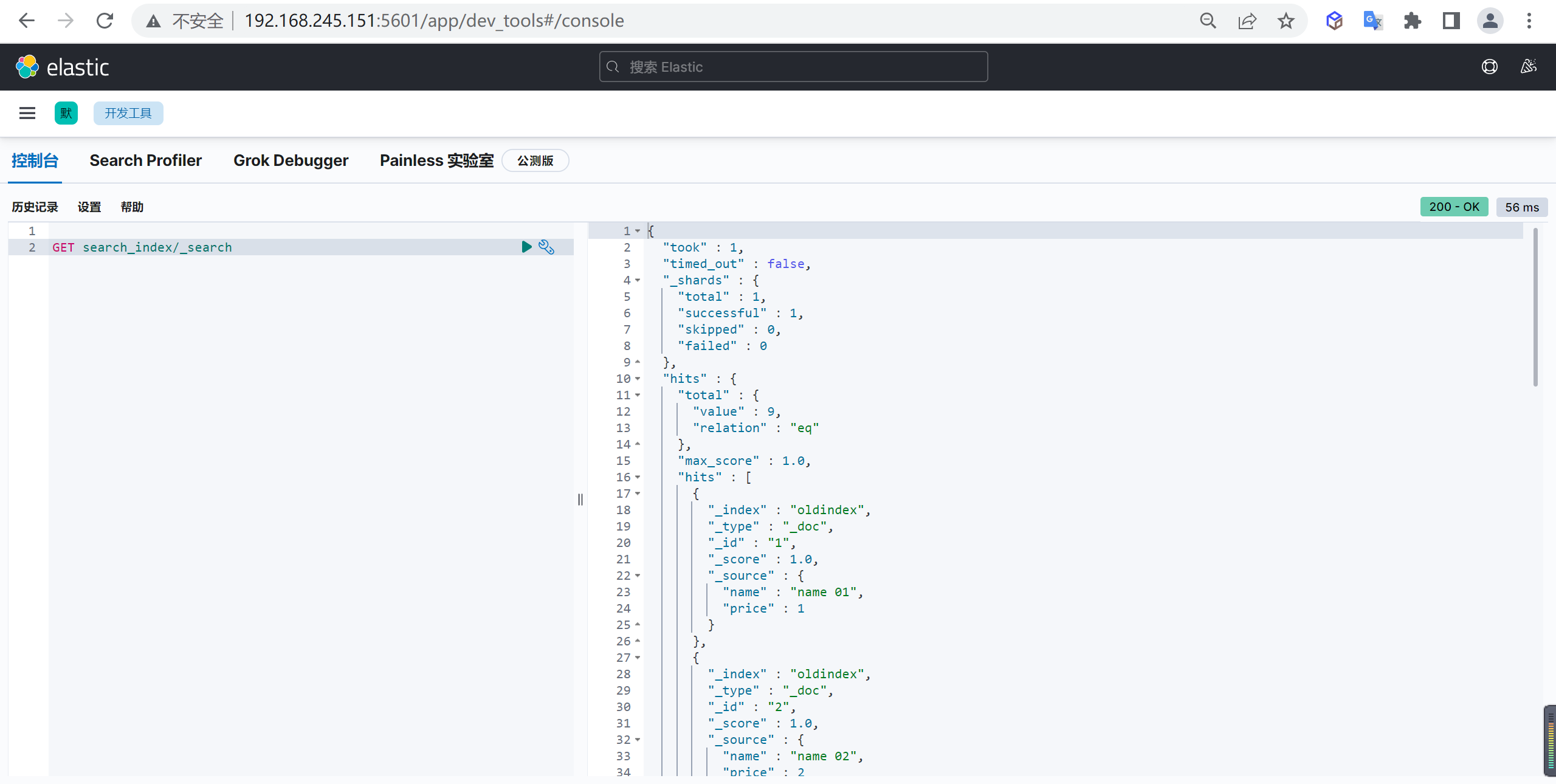
查询数据
我们使用别名查询数据
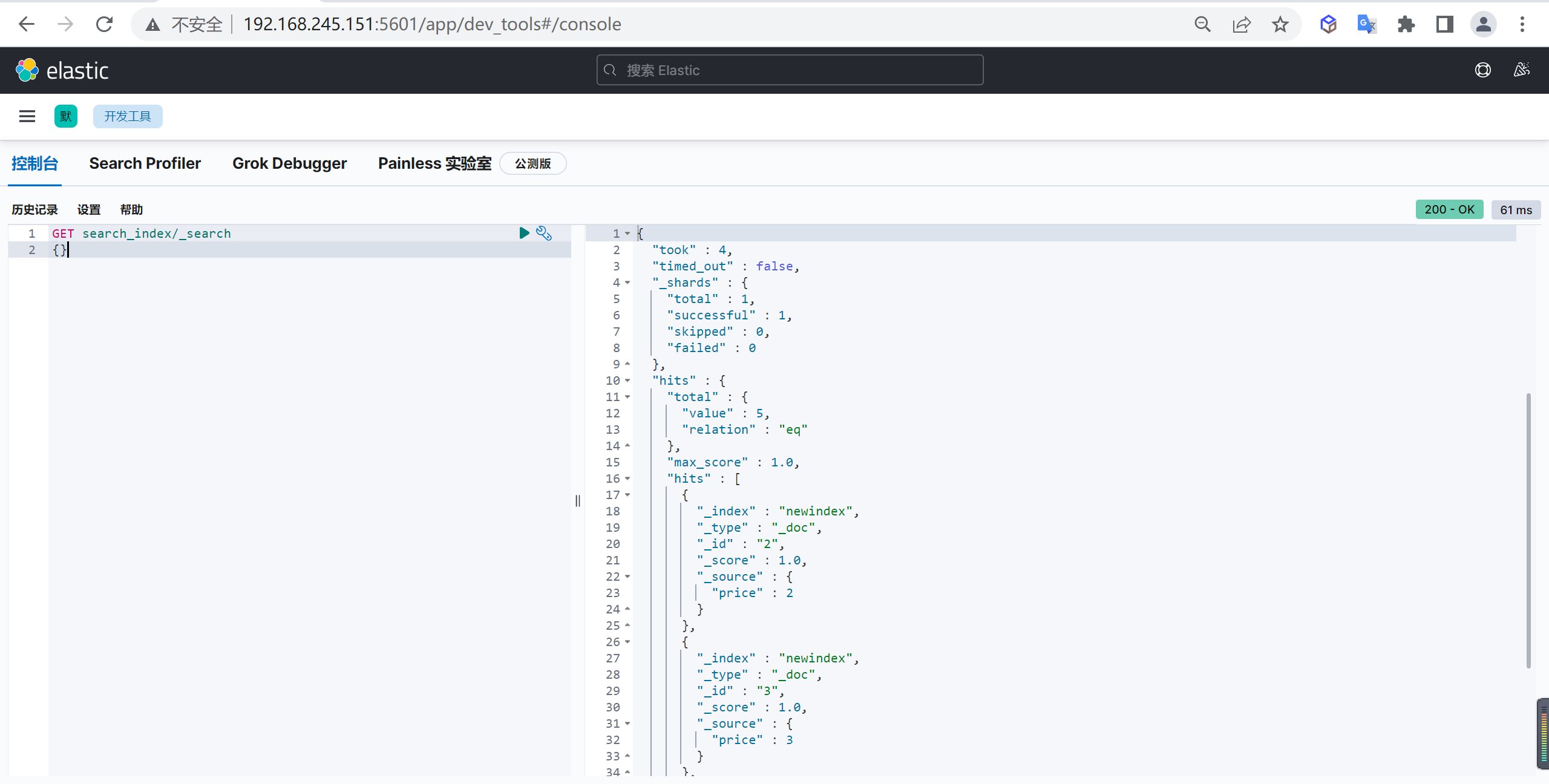
1 | GET search_index/_search |
创建新索引
根据需求我们创建一个新的索引,价格字段改为integer类型
1 | PUT newindex |

重建索引
数据量大的话可以异步执⾏,如果 reindex 时间过长,建议加上
wait_for_completion=false的参数条件,这样reindex将直接返回taskId
1 | POST _reindex?wait_for_completion=false |
更多参数
更高级的用法可以参考下下面的例子
1 | POST _reindex?wait_for_completion=false |
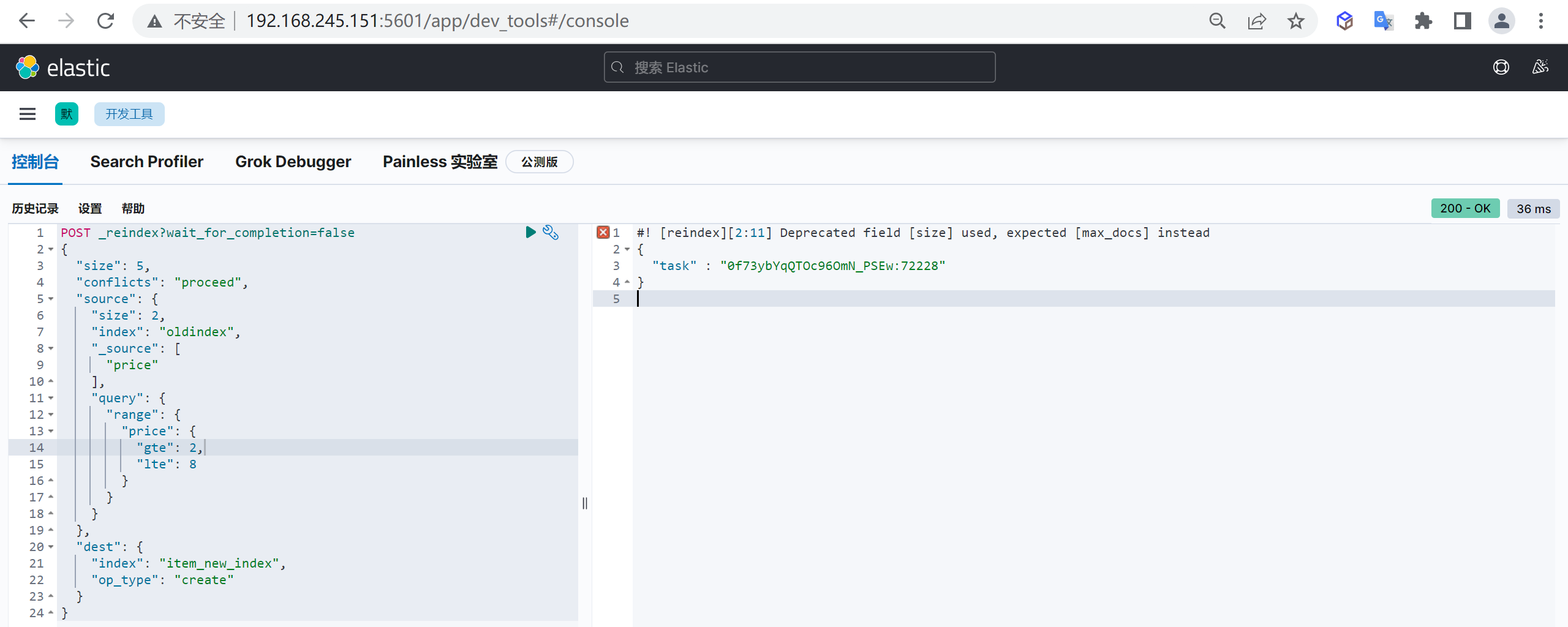
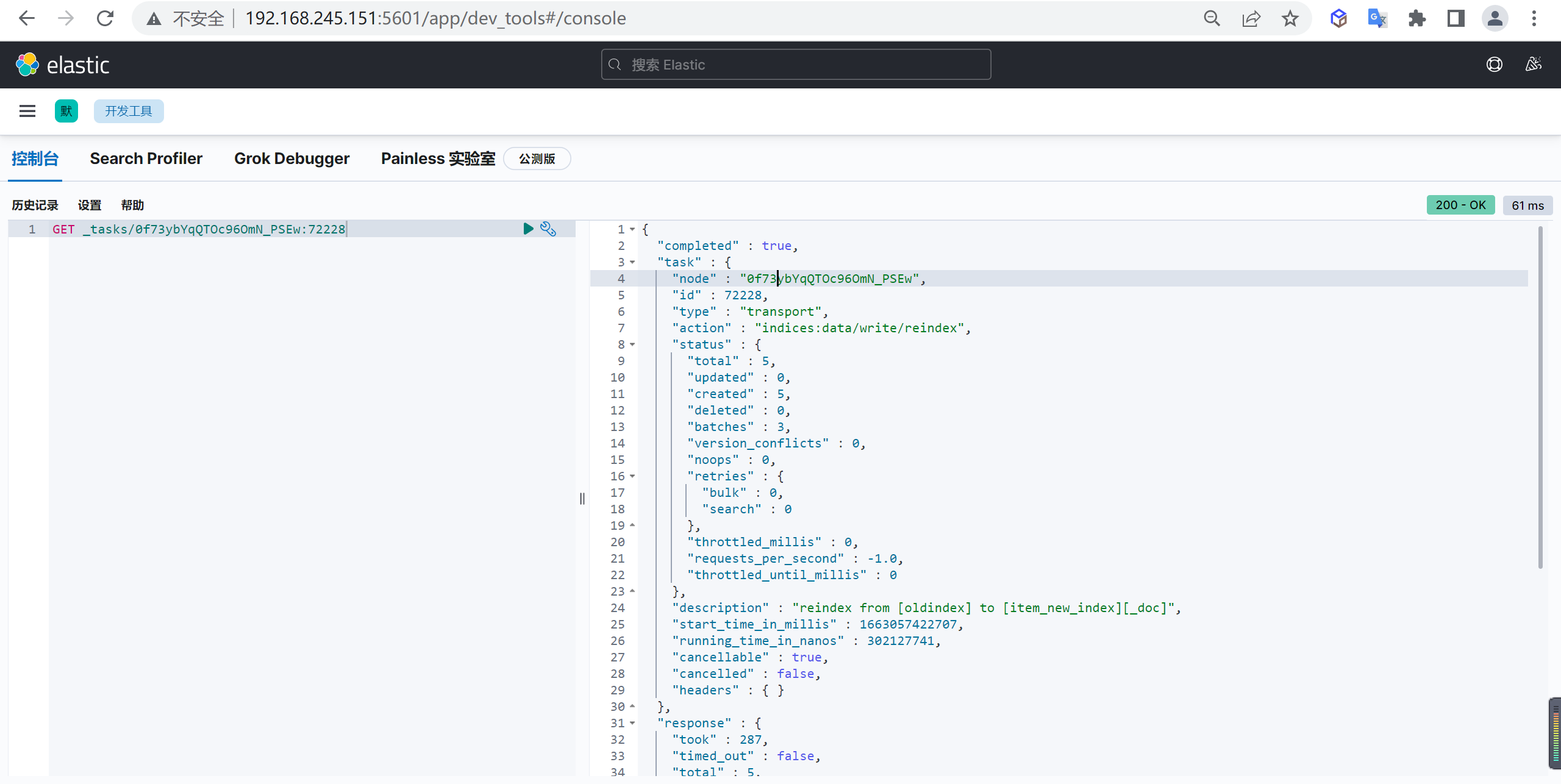
查看任务
1 | GET _tasks/0f73ybYqQTOc96OmN_PSEw:72228 |
取消任务
如果任务还没有完成,需要取消任务可以使用如下的命令
1 | POST _tasks/0f73ybYqQTOc96OmN_PSEw:72228/_cancel |
别名切换
我们需要将别名切换到另刚刚重建的索引上,切换索引可以实现不重启服务索引的切换
1 | POST _aliases |
这样就实现了快速索引切换
删除旧的索引
1 | DELETE oldindex |

查询数据
1 | GET search_index/_search |