Docker安装Hdfs

Hdfs概述
Hdfs是什么
hdfs(Hadoop Distribute File System)是分布式文件系统
Hadoop之(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行。 它与现有的分布式文件系统有许多相似之处。 但是,与其他分布式文件系统的差异很大。
分布式文件系统
分布式文件系统 distributed file system 是指文件系统管理的物理存储资源不一定直接链接在本地节点上,而是通过计算机网络与节点相连,可让多机器上的多用户分享文件和存储空间。分布式文件系统的设计基于客户机/服务器模式
特点
- 分布式文件系统可以有效解决数据的存储和管理难题
- 将固定于某个地点的某个文件系统,扩展到任意多个地点/多个文件系统
- 众多的节点组成一个文件系统网络
- 每个节点可以分布在不同的地点,通过网络进行节点间的通信和数据传输
- 在使用分布式文件系统时,无需关心数据是存储在哪个节点上、或者是从哪个节点获取的,只需要像使用本地文件系统一样管理和存储文件系统中的数据
HDFS的特点
优点
- 高容错性:数据自动保存多个副本,副本丢失后,自动恢复
- 适合批处理:移动计算而飞数据。数据位置暴露给计算框架
- 适合大数据处理:GB,TB,设置PB级数据。百万规模以上文件数量。10K+节点规模。
- 流式文件访问:一次性写入,多次读取。保证数据一致性。
- 可构建在廉价机器上:通过多副本提高可靠性。提供容错和恢复机制。
缺点
- 不适合低延迟数据访问场景:比如毫秒级,低延迟与高吞吐率
- 不适合小文件存取场景:占用NameNode大量内存。寻道时间超过读取时间。
- 不适合并发写入,文件随机修改场景:一个文件只能有一个写者。仅支持append
HDFS读写过程
HDFS读过程
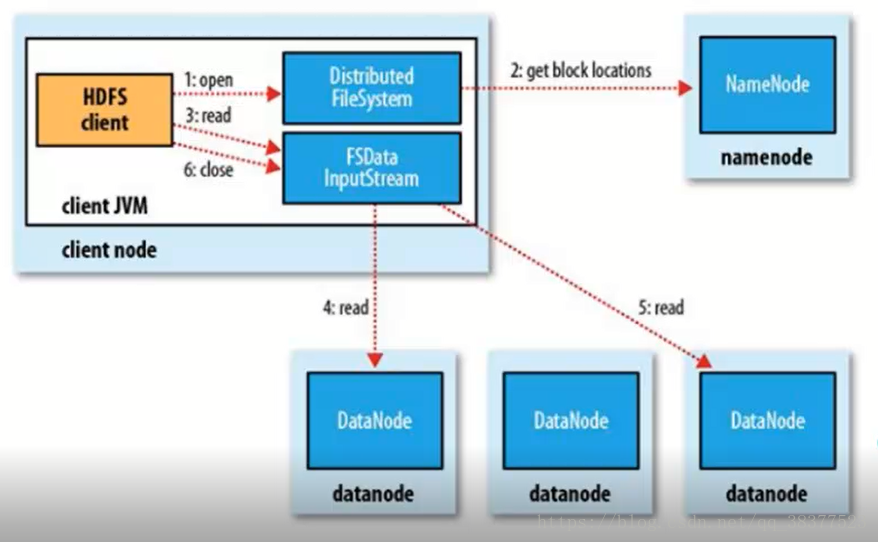
客户端发送请求,调用DistributedFileSystem API的open方法发送请求到Namenode,获得block的位置信息,因为真正的block是存在Datanode节点上的,而namenode里存放了block位置信息的元数据。
Namenode返回所有block的位置信息,并将这些信息返回给客户端。
客户端拿到block的位置信息后调用FSDataInputStream API的read方法并行的读取block信息,图中4和5流程是并发的,block默认有3个副本,所以每一个block只需要从一个副本读取就可以。
datanode返回给客户端。
HDFS写过程
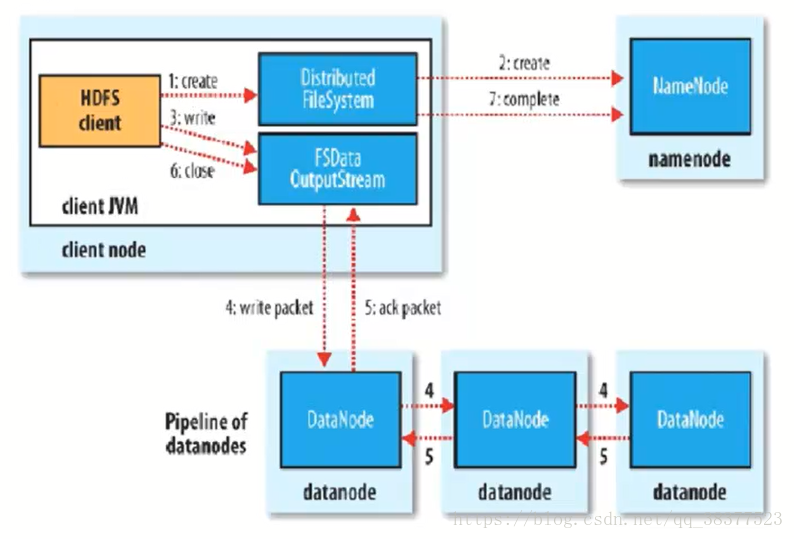
客户端发送请求,调用DistributedFileSystem API的create方法去请求namenode,并告诉namenode上传文件的文件名、文件大小、文件拥有者。
namenode根据以上信息算出文件需要切成多少块block,以及block要存放在哪个datanode上,并将这些信息返回给客户端。
客户端调用FSDataInputStream API的write方法首先将其中一个block写在datanode上,每一个block默认都有3个副本,并不是由客户端分别往3个datanode上写3份,而是由 已经上传了block的datanode产生新的线程,由这个namenode按照放置副本规则往其它datanode写副本,这样的优势就是快。
写完后返回给客户端一个信息,然后客户端在将信息反馈给namenode。
需要注意的是上传文件的拥有者就是客户端上传文件的用户名
HDFS的常用指令
1 | hadoop fs -mkdir /tmp/input 在HDFS上新建文件夹 |
安装Hdfs
Docker安装
拉取镜像
1 | docker pull singularities/hadoop |

创建docker-compose
1 | version: "2" |
启动应用
1 | docker-compose up -d |

开启多个数据节点
1 | docker-compose scale datanode=3 |
访问页面
查看hadoop控制面板。由于服务刚初始化,可能需要等一会,访问地址:
1 | http://192.168.64.172:50070/dfshealth.html#tab-datanode |
