容器化概览

概述
在开发过测试过程中会遇到很多的问题,比如环境不一致问题,服务部署问题,服务重启等问题,影响我们开发测试以及上线的效率
容器化和面向服务的设计试图解决很多这些问题,应用程序可以分解为可管理的功能组件,单独打包其所有依赖项,并轻松部署在不规则架构上, 缩放和更新组件也被简化
什么是容器化
容器化是将应用程序代码和依赖环境捆绑到一个单一的虚拟包中,容器化应用程序通常与其他应用程序并排放置,并通过计算机、服务器或云上的共享操作系统运行

容器实际上是一种沙盒技术,主要目的是为了将应用运行在沙盒中,与外界隔离,及方便这个沙盒可以被转移到其它宿主机器
容器化本质
本质上,容器是一个特殊的进程,通过名称空间(Namespace)、控制组(Control groups)、切根(chroot)技术把资源、文件、设备、状态和配置划分到一个独立的空间
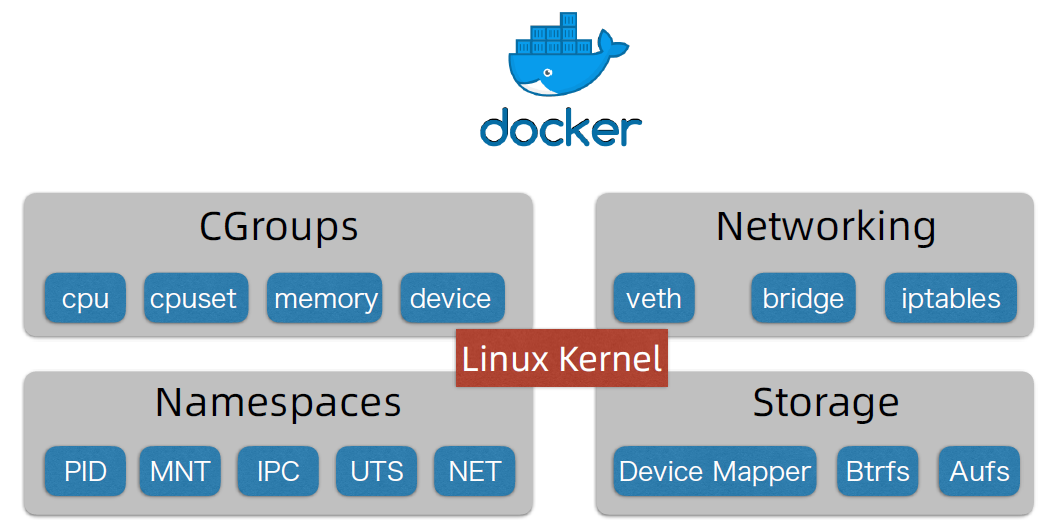
容器是轻量级的操作系统级虚拟化,可以让我们在一个资源隔离的进程中运行应用及其依赖项,运行应用程序所必需的组件都将打包成一个镜像并可以复用,执行镜像时,它运行在一个隔离环境中,并且不会共享宿主机的内存、CPU 以及磁盘,这就保证了容器内进程不能监控容器外的任何进程。
通俗点的理解就是一个装应用软件的箱子,箱子里面有软件运行所需的依赖库和配置,开发人员可以把这个箱子搬到任何机器上,且不影响里面软件的运行。
解决了什么问题
微服务虽然具备各种各样的优势,但服务的拆分通用给部署带来了很大的麻烦
- 分布式系统中,依赖的组件非常多,不同组件之间部署时往往会产生一些冲突。
- 在数百上千台服务中重复部署,环境不一定一致,会遇到各种问题
应用部署的环境问题
大型项目组件较多,运行环境也较为复杂,部署时会碰到一些问题:
- 依赖关系复杂,容易出现兼容性问题
- 开发、测试、生产环境有差异
例如一个项目中,部署时需要依赖于node.js、Redis、RabbitMQ、MySQL等,这些服务部署时所需要的函数库、依赖项各不相同,甚至会有冲突,给部署带来了极大的困难。
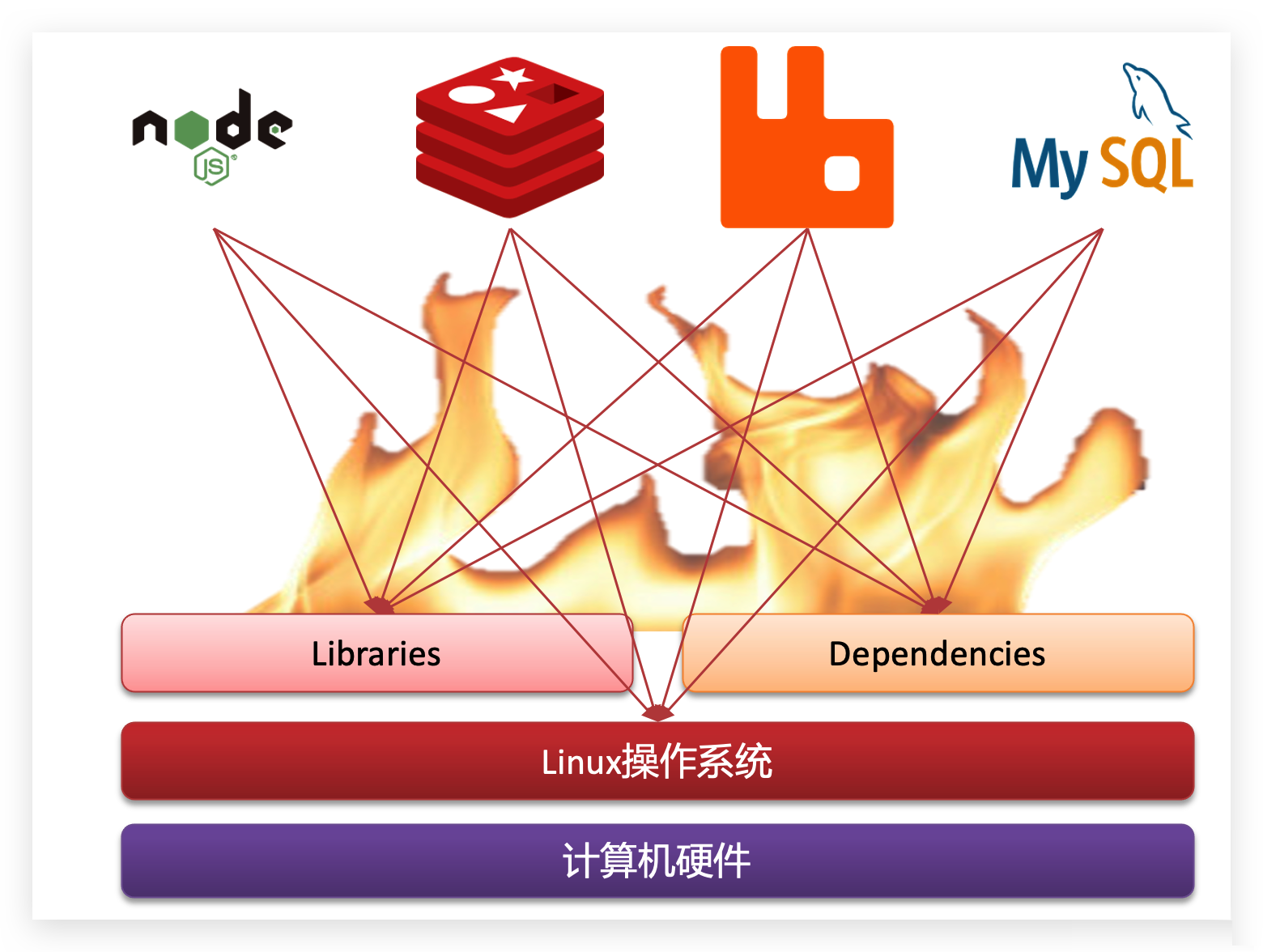
解决依赖兼容问题
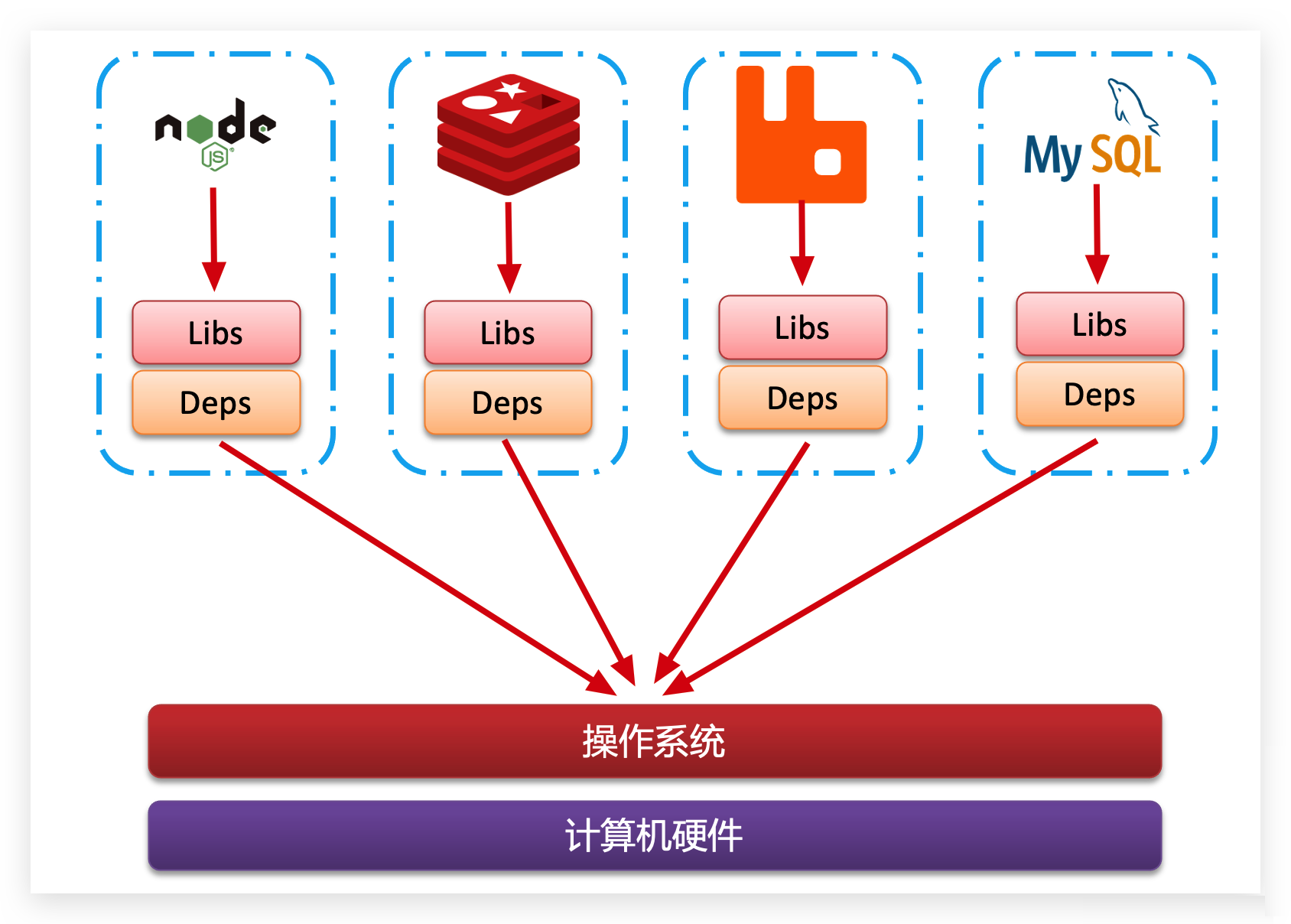
容器化为了解决依赖的兼容问题的,采用了两个手段
- 将应用的Libs(函数库)、Deps(依赖)、配置与应用一起打包
- 将每个应用放到一个隔离容器去运行,避免互相干扰
这样打包好的应用包中,既包含应用本身,也保护应用所需要的Libs、Deps,无需再操作系统上安装这些,自然就不存在不同应用之间的兼容问题了
虽然解决了不同应用的兼容问题,但是开发、测试等环境会存在差异,操作系统版本也会有差异,怎么解决这些问题呢?
解决操作系统环境差异
操作系统结构
要解决不同操作系统环境差异问题,必须先了解操作系统结构,以一个Ubuntu操作系统为例,结构如下:

- 计算机硬件:例如CPU、内存、磁盘等
- 系统内核:所有Linux发行版的内核都是Linux,例如CentOS、Ubuntu、Fedora等,内核可以与计算机硬件交互,对外提供内核指令,用于操作计算机硬件。
- 系统应用:操作系统本身提供的应用、函数库。这些函数库是对内核指令的封装,使用更加方便。
操作系统调用
应用于计算机交互的流程如下:
- 应用调用操作系统应用(函数库),实现各种功能
- 系统函数库是对内核指令集的封装,会调用内核指令
- 内核指令操作计算机硬件
环境导致的问题
Ubuntu和CentOS环境都是基于Linux内核,无非是系统应用不同,提供的函数库有差异:

此时,如果将一个Ubuntu版本的MySQL应用安装到CentOS系统,MySQL在调用Ubuntu函数库时,会发现找不到或者不匹配,就会报错了:

如何解决环境问题
Docker如何解决不同系统环境的问题?
- Docker将用户程序与所需要调用的系统(比如Ubuntu)函数库一起打包
- Docker运行到不同操作系统时,直接基于打包的函数库,借助于操作系统的Linux内核来运行

容器的使用
应用程序开发的记录也是将这些应用程序打包为不同平台和操作系统的记录
让我们以一个用流行的编程语言Java编写的简单web应用程序为例,要在服务器或本地机器上运行应用程序,系统通常需要满足以下特定要求:
- 安装和配置基本操作系统
- 安装JDK来运行程序
- 安装程序使用三方Jar的扩展
- 为您的系统配置网络
- 连接到第三方系统,如数据库、缓存或存储。
虽然开发人员最了解自己的应用程序及其依赖关系,但通常是由系统管理员提供基础设施、安装所有依赖关系并配置应用程序运行的系统,这个过程非常容易出错,而且很难维护,因此服务器只用于单一目的配置,比如运行数据库或应用服务器,然后通过网络连接。
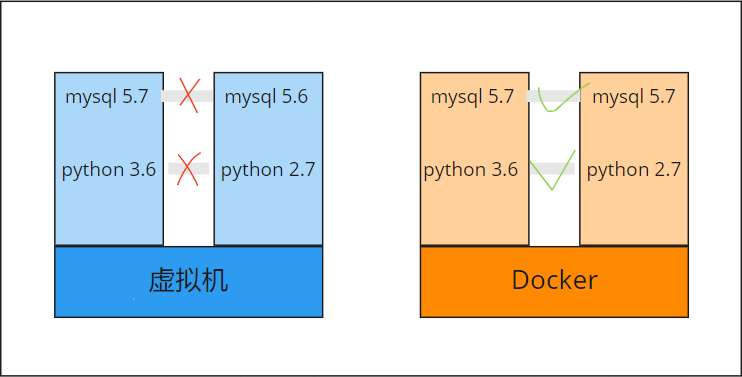
为了更有效地利用服务器硬件,可以使用虚拟机来模拟一个具有cpu、内存、存储、网络、操作系统和软件的完整服务器,这允许在同一硬件上运行多个隔离的服务器。
在广泛采用容器之前,服务器虚拟化是运行独立且易于处理的应用程序的最有效方式,但由于必须运行包括内核在内的整个操作系统,如果需要运行大量服务器,那么它总是会带来一些开销。
容器可以用来解决这两个问题,管理应用程序的依赖关系,并比大量虚拟机更有效地运行。
容器技术应用
容器变得越来越重要,尤其是在云环境中,许多企业甚至在考虑将容器替代 VM 作为其应用程序和工作负载的通用计算平台
- 微服务:容器小巧轻便,非常适合微服务体系结构,在微体系结构中,应用程序可以由许多松散耦合且可独立部署的较小服务构成。
- DevOps:微服务作为架构和容器作为平台的结合,是许多团队将 DevOps 视为构建,交付和运行软件的方式的共同基础。
- 混合,多云:由于容器可以在笔记本电脑,本地和云环境中的任何地方连续运行,因此它们是混合云和多云方案的理想基础架构,在这种情况下,组织发现自己跨多个公共云运行与自己的数据中心结合, 应用程序现代化和迁移:使应用程序现代化的最常见方法之一是将它们容器化,以便可以将它们迁移到云中。
容器化初体验
Docker安装
Docker 支持以下的 64 位 CentOS 版本
设置仓库
安装所需的软件包。yum-utils 提供了 yum-config-manager ,并且 device mapper 存储驱动程序需要 device-mapper-persistent-data 和 lvm2。
1 | sudo yum install -y yum-utils \ |
使用以下命令来设置稳定的仓库(阿里云)
1 | sudo yum-config-manager \ |
安装 Docker Engine
安装最新版本的 Docker Engine-Community 和 containerd,或者转到下一步安装特定版本:
1 | sudo yum install -y docker-ce docker-ce-cli containerd.io |
开启Docker自动补全
使用docker时无法自动补全镜像名和其他参数,这样使用效率大大降低,下面是解决方法
bash-complete
1 | yum install -y bash-completion |
刷新文件
1 | source /usr/share/bash-completion/completions/docker |
web应用操作
运行一个 web 应用
接下来让我们尝试使用 docker 构建一个 web 应用程序,我们将在docker容器中运行一个 Python Flask 应用来运行一个web应用
1 | docker pull training/webapp # 载入镜像 |
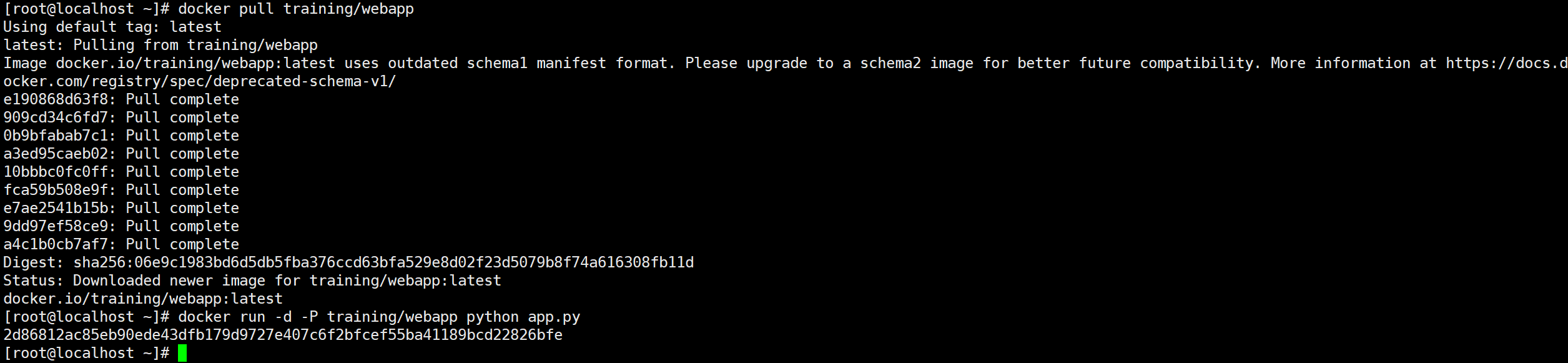
查看 WEB 应用容器
使用 docker ps 来查看我们正在运行的容器
1 | docker ps |

这里多了端口信息
1 | 0.0.0.0:32768->5000/tcp |
访问WEB容器
Docker 开放了 5000 端口(默认 Python Flask 端口)映射到主机端口 32768 上,这时我们可以通过浏览器访问WEB应用

查看 WEB 应用日志
docker logs [ID或者名字] 可以查看容器内部的标准输出
1 | docker logs -f 5f0eff0ad337 |

检查 WEB 配置信息
使用 docker inspect 来查看 Docker 的底层信息,它会返回一个 JSON 文件记录着 Docker 容器的配置和状态信息
1 | docker inspect 5f0eff0ad337 |
1 | [ |
停止 WEB 容器
1 | docker stop 5f0eff0ad337 |
部署模式发展
物理单机时代
早期在物理服务器上运行应用程序也叫做传统的部署。
- 在商用服务计算领域几乎都是以单机为基础计算单元对计算资源 进行管理和协调控制的
- 部署新应用往往需要购买一台物理机器或者一组机器,并在机器上进行构建,部署和运行,而且一台机器往往只能运行单个应用,成本高,利用率低
部署方式
早期在物理服务器上运行应用程序也叫做传统的部署
在物理服务器上运行应用程序,无法为物理服务器中的应用程序定义资源边界,这会导致资源分配的问题。
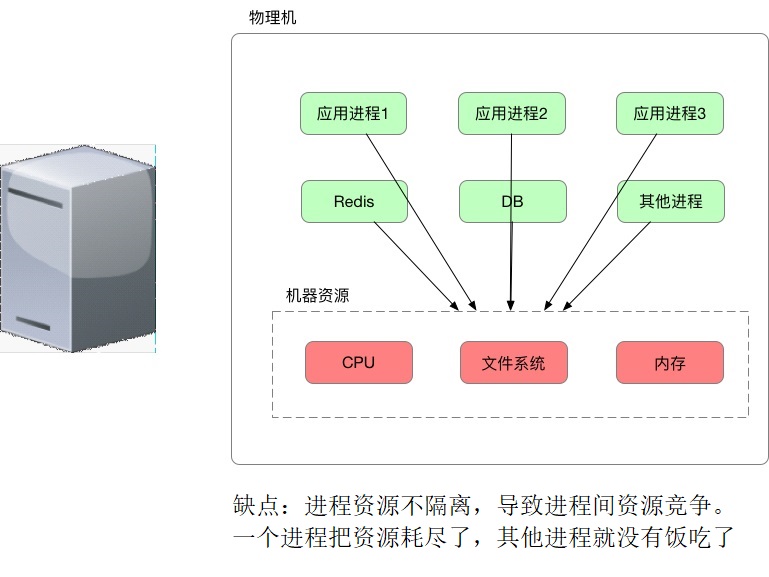
用纯粹的物理机部署应用,这是所有早期物联网公司必然经历的一个阶段,一台服务器,至少32核CPU、64G内存,如果只部署一个应用,那就太浪费了,于是,多个应用进程,DB,缓存进程等等都部署在同一个机器上。
这样部署固然能高效的利用好昂贵的物理机,但是这种简单粗暴的方式有一个最大的痛点:进程间资源抢占,如果某个进程耗用了100%的CPU资源,其他的进程无法提供服务,或者如果一个进程因为突发异常很多,日志把磁盘打满了,所有的进程都要挂掉。进程间抢占资源导致其他进程无法提供服务所导致的血案数不胜数,这样的问题相信很多同学的遇到过。
例如,如果在物理服务器上运行多个应用程序,则可能存在一个应用程序占用大部分资源的情况,因此导致其他应用程序获取不到资源。所以往往解决方案是在不同的物理服务器上运行每个应用程序。但是由于资源未得到充分利用,没有扩展,组织和维护这么多物理服务器的成本很高。
既然因为资源共享导致的问题,那么解决方式就是:进程间硬件资源隔离,虚拟机技术的出现解决了这个棘手的问题。
虚拟化时代
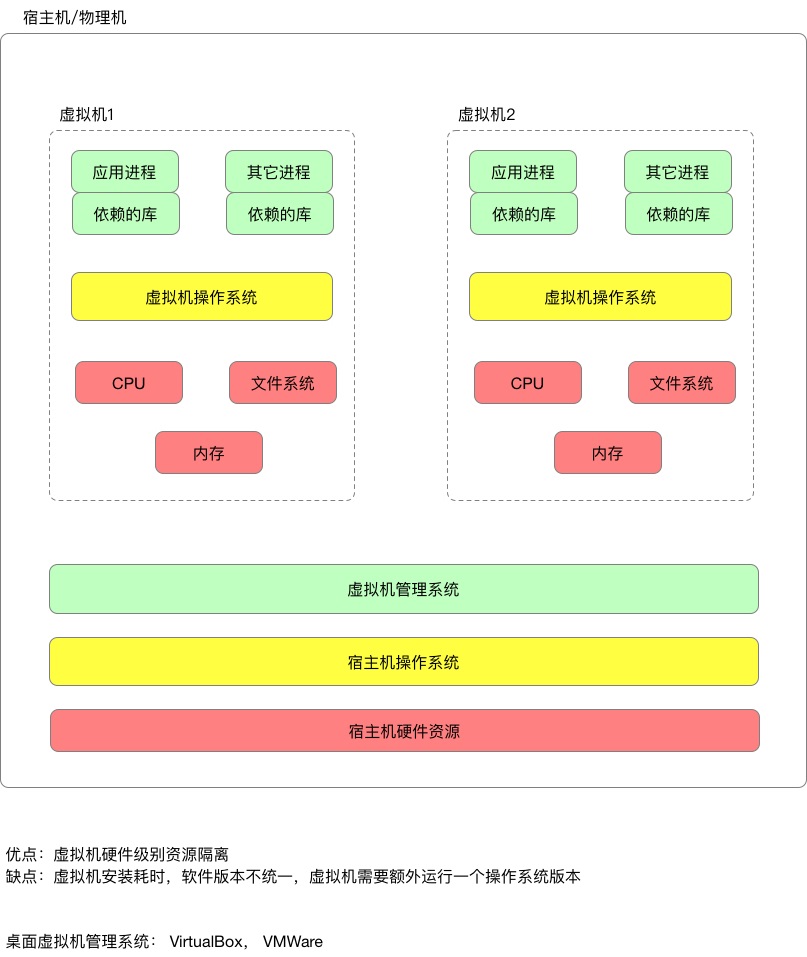
虚拟机通过硬件虚拟化,即每台虚拟机事先从物理机分配好cpu核数,内存, 磁盘,每台虚拟机一般只部署一个应用,从而解决了进程间资源隔离的问题,不同的进程在不同的虚拟机上跑,大家相安无事,老死不相往来,自然没有资源冲突,一台物理机会部署多台虚拟机,物理机里的所有虚拟机则依靠虚拟机管理系统进行管理。
虚拟机技术解决了物理机部署的痛点,但是虚拟机并不是完美的,他也有自己的缺点,大集群部署情况下,软件的版本容易混乱
大应用集群的虚拟机第一次安装时,由于操作系统镜像是一样的,所以刚开始,软件的版本和库依赖是统一的,随着时间的推移,开源的软件(tomcat, jdk, nginx)需要逐步升级,于是运维同学开始批量升级集群的软件版本,批量升级可能有遗漏或升级失败。
同时有些开发同学会自己登陆机器修改软件的版本或者配置,以满足自己的需求,长此以往,一个应用的集群的虚拟机的软件版本和配置逐渐碎片化,当线上出现问题,需要排查到基础软件层面时,由于软件版本碎片化的问题,导致排查变得很棘手。
虚拟化的缺点
虚拟化方法面临一些挑战,导致这些环境变得效率低下,其中包括:
- 环境不一致性:应用程序和软件包部署到虚拟环境
- 操作系统依赖性:部署的应用程序只能在兼容的操作系统上运行
- 隔离级别:无法提供高于操作系统级别的即时沙盒
- 计算消耗粒度:无法部署多个复制的应用程序,而应用程序层上的负载平衡只能在单台计算机中运行,不能在非操作系统层中运行
- 在生产级别环境中修补映像:金丝雀部署和蓝绿部署在群集级别上不灵活,而且难以跨多个区域进行管理
容器部署时代
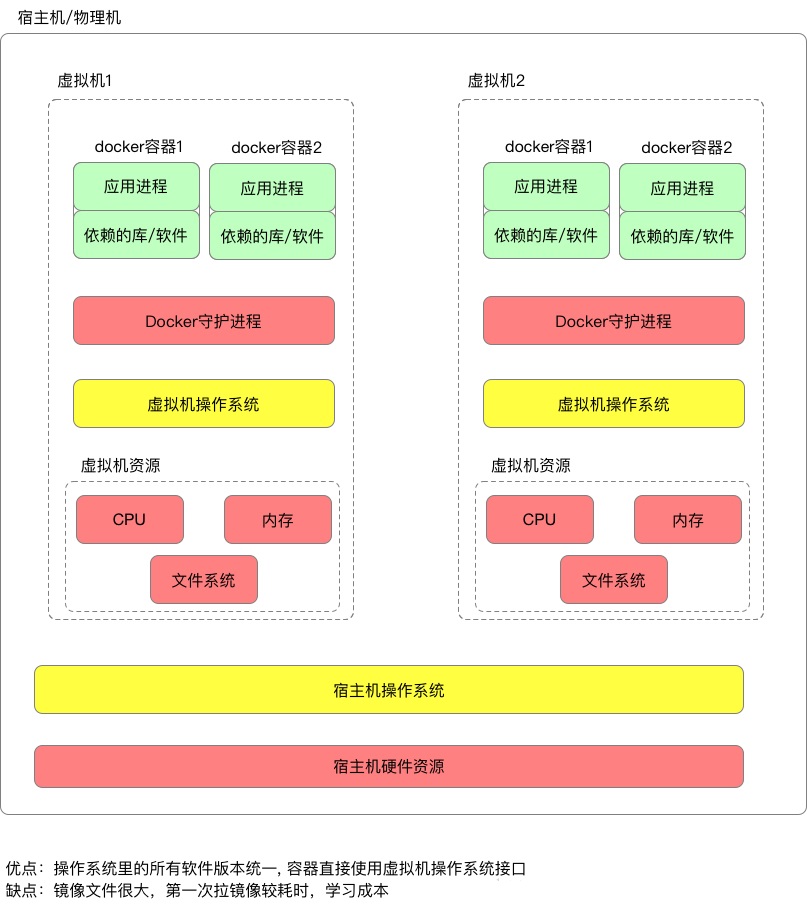
容器技术不仅限于docker,但是docker目前最为流行,我以docker为例讲容器,docker容器技术的核心之一在于镜像文件。
镜像文件,通俗的理解就是一个进程运行时依赖的软件文件的集装箱。
应用集群部署时,每台机器首先会拉取指定版本的镜像文件。安装镜像后产生了docker容器。由于所有机器的镜像文件一样,容器的软件版本故而一样。即使开发或运维中途修改了容器的软件版本,但是容器销毁时,软件的改动会随容器的销毁一起湮灭。
容器如果要升级软件版本,那就修改镜像文件,这样部署时集群内所有的机器重新拉取新的镜像,软件因此跟着一起升级。软件版本混乱的问题,到docker这里,也就得到了完美的解决。
容器化能够解决什么问题?如果我们在一台服务器上只跑很多个服务,比如说有一个服务内存泄漏把整个服务器内存占满了,其他服务也跟着倒霉,所以需要把每个服务隔离起来,让它们只使用自己那部分有限的CPU,内存和磁盘以及依赖的软件包。Docker相比虚拟机来说少了操作系统这一层,所以占用的资源少,启动速度快,能够提供一定程度的隔离,而且运维简单,可以克隆多个个环境相同的容器。
和虚拟化对比
下表是 “虚拟化技术” 与 “容器化技术” 的对比
| 特性 | 虚拟机 | 容器 |
|---|---|---|
| 隔离级别 | 操作系统级 | 进程级别 |
| 隔离策略 | Hypervisor | CGroups |
| 系统资源 | 5%~15% | 0%~5% |
| 启动时间 | 分钟级 | 秒级 |
| 镜像存储 | GB-TB | KB-MB |
| 集群规模 | 上百 | 上万 |
| 高可用策略 | 备份、容灾、迁移 | 弹性、负载、动态 |
容器化历史
容器化的前世
讲到容器,就不得不提LXC(Linux Container),他是Docker的前生,或者说Docker是LXC的使用者
完整的LXC能力在2008年合入Linux主线,所以容器的概念在2008年就基本定型了,并不是后面Docker造出来的,关于LXC的介绍很多,大体都会说“LXC是Linux内核提供的容器技术,能提供轻量级的虚拟化能力,能隔离进程和资源”,但总结起来,无外乎就两大知识点Cgroups(Linux Control Group)和Linux Namespace,搞清楚他俩,容器技术就基本掌握了。
艰难的起步阶段
2009,Cloud Foundry基于LXC实现了对容器的操作,该项目取名为Warden,2010年,dotCloud公司同样基于LXC技术,使用Go语言实现了一款容器引擎,也就是现在的Docker,那时,dotCloud公司还是个小公司,出生卑微的Docker没什么热度,活得相当艰难。
成功的逆袭
2013年,dotCloud公司决定将Docker开源,开源后,项目突然就火了。
从大的说,火的原因就是Docker的这句口号Build once,Run AnyWhere,呵呵,是不是似曾相识?对的,和Java的Write Once,Run AnyWhere一个道理。
对于一个程序员来说,程序写完后打包成镜像就可以随处部署和运行,开发、测试和生产环境完全一致,这是多么大一个诱惑,程序员再也不用去定位因环境差异导致的各种坑爹问题。
Docker开源项目的异常火爆,直接驱动dotCloud公司在2013年更名为Docker公司,Docker也快速成长,干掉了CoreOS公司的rkt容器和Google的lmctfy容器,直接变成了容器的事实标准,也就有了后来人一提到容器就认为是Docker
总结起来,Docker为什么火,靠的就是Docker镜像,他打包了应用程序的所有依赖,彻底解决了环境的一致性问题,重新定义了软件的交付方式,提高了生产效率。
曾经的辉煌
Docker在容器领域快速成长,野心自然也变大了
2014年推出了容器云产品Swarm(K8s的同类产品),想扩张事业版图,同时Docker在开源社区拥有绝对话语权,相当强势,这种走自己的路,让别人无路可走的行为,以“镜像”这个大招席卷全球,对其他容器技术进行致命的降维打击,使其毫无招架之力。
就连 Google 也不例外,Google 为了不被拍死在沙滩上,被迫拉下脸面(当然,跪舔是不可能的),希望 Docker 公司和自己联合推进一个开源的容器运行时作为 Docker 的核心依赖,不然就走着瞧,Docker 公司觉得自己的智商被侮辱了,走着瞧就走着瞧,谁怕谁啊!
Docker的这种操作让容器领域的其他大厂玩家很是不爽,为了不让Docker一家独大,决定要干他,很明显,Docker 公司的这个决策断送了自己的大好前程,造成了今天的悲剧。
暗度陈仓
2015年6月,在Google、Redhat等大厂的“运作”下,Linux基金会成立了OCI(Open Container Initiative)组织,旨在围绕容器格式和运行时制定一个开放的工业化标准,也就是我们常说的OCI标准,同时几位巨佬连哄带骗忽悠 Docker 公司将 libcontainer 捐给中立的社区(OCI,Open Container Intiative)作为OCI标准的实现,这就是现在的RunC项目,说白了,就是现在这块儿有个标准了,大家一起玩儿,不被某个特定项目的绑定,并改名为 runc,不留一点 Docker 公司的痕迹~~
这还不够,为了彻底扭转 Docker 一家独大的局面,几位大佬又合伙成立了一个基金会叫 CNCF(Cloud Native Computing Fundation),这个名字想必大家都很熟了,我就不详细介绍了,CNCF 的目标很明确,既然在当前的维度上干不过 Docker,干脆往上爬,升级到大规模容器编排的维度,以此来击败 Docker。
没落的开始
Docker 公司当然不甘示弱,搬出了 Swarm 和 Kubernetes 进行 PK,最后的结局大家都知道了,Swarm 战败,然后 Docker 公司耍了个小聪明,将自己的核心依赖 Containerd 捐给了 CNCF,以此来标榜 Docker 是一个 PaaS 平台。
很明显,这个小聪明又大大加速了自己的灭亡。
巨佬们心想,想当初想和你合作搞个中立的核心运行时,你死要面子活受罪,就是不同意,好家伙,现在自己搞了一个,还捐出来了,这是什么操作?也罢,这倒省事了,我就直接拿 Containerd 来做文章吧。
首先呢,为了表示 Kubernetes 的中立性,当然要搞个标准化的容器运行时接口,只要适配了这个接口的容器运行时,都可以和我一起玩耍哦,第一个支持这个接口的当然就是 Containerd 啦,至于这个接口的名字,大家应该都知道了,它叫 CRI(Container Runntime Interface)。
这样还不行,为了蛊惑 Docker 公司,Kubernetes 暂时先委屈自己,专门在自己的组件中集成了一个 shim(你可以理解为垫片),用来将 CRI 的调用翻译成 Docker 的 API,让 Docker 也能和自己愉快地玩耍,温水煮青蛙,养肥了再杀。。。

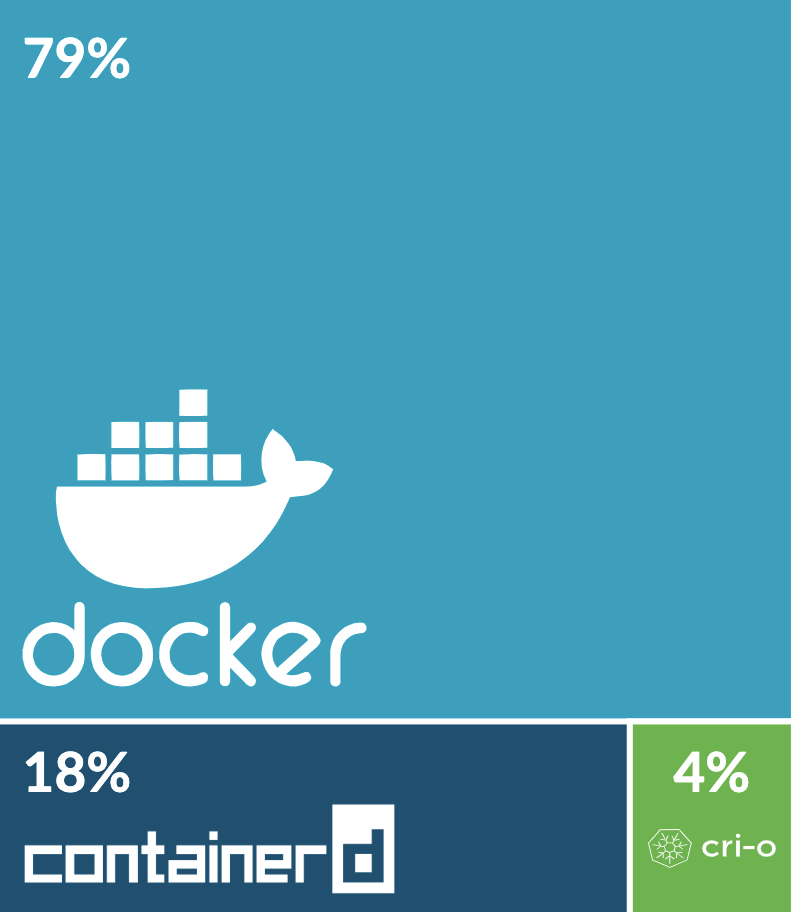
作为容器云平台的事实标准,如今已被广泛使用,俨然已成为大厂标配。Kubernetes原生支持Docker,让Docker的市场占有率一直居高不下,如图是2019年容器运行时的市场占有率。
抛弃Docker
就这样,Kubernetes 一边假装和 Docker 愉快玩耍,一边背地里不断优化 Containerd 的健壮性以及和 CRI 对接的丝滑性,现在 Containerd 的翅膀已经完全硬了,是时候卸下我的伪装,和 Docker say bye bye 了,后面的事情大家也都知道了~~
在2020年,Kubernetes突然宣布在1.20版本以后,也就是2021年以后,不再支持Docker作为默认的容器运行时,将在代码主干中去除dockershim。
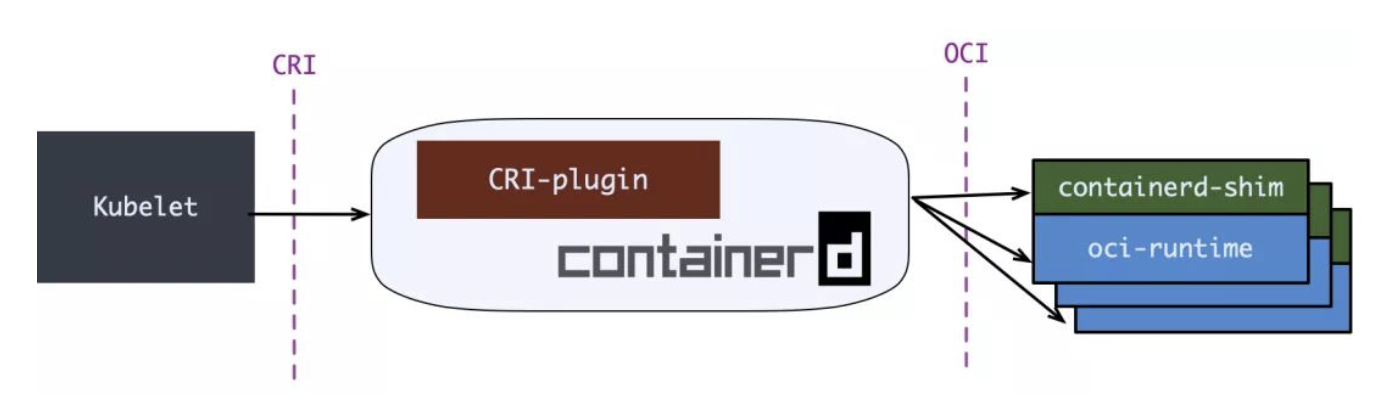
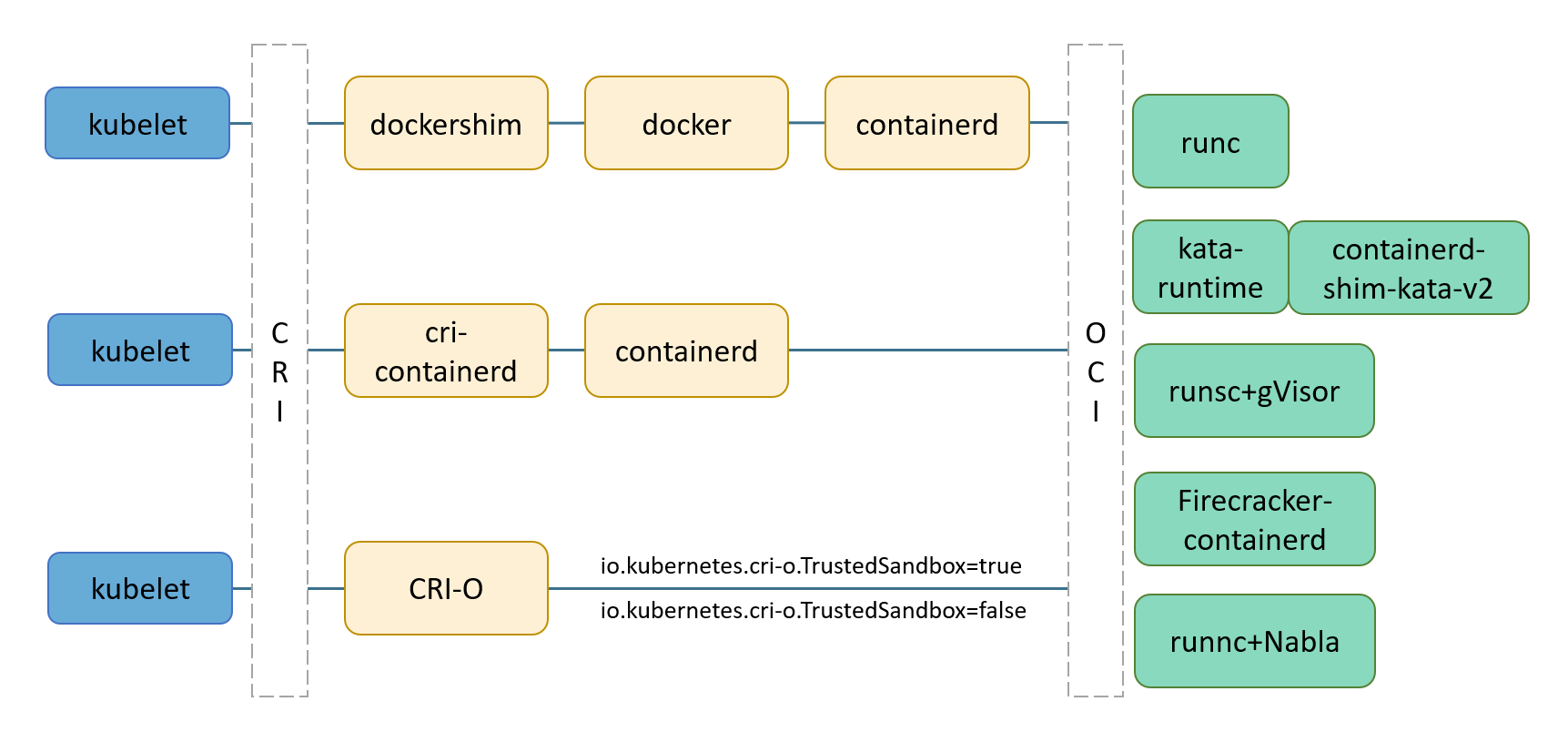
如图所示,K8s自身定义了标准的容器运行时接口CRI(Container Runtime Interface),目的是能对接任何实现了CRI接口的容器运行时,在初期,Docker是容器运行时不容置疑的王者,K8s便内置了对Docker的支持,通过dockershim来实现标准CRI接口到Docker接口的适配,以此获得更多的用户。
随着开源的容器运行时Containerd(实现了CRI接口,同样由Docker捐给CNCF)的成熟,K8s不再维护dockershim,仅负责维护标准的CRI,解除与某特定容器运行时的绑定,当然,也不是K8s不支持Docker了,只是dockershim谁维护的问题, 随着K8s态度的变化,预计将会有越来越多的开发者选择直接与开源的Containerd对接,Docker公司和Docker开源项目(现已改名为moby)未来将会发生什么样的变化,谁也说不好。
讲到这里,不知道大家有没有注意到,Docker公司其实是捐献了Containerd和runC,这俩到底是啥东西,简单的说,runC是OCI标准的实现,也叫OCI运行时,是真正负责操作容器的,Containerd对外提供接口,管理、控制着runC。
Docker公司是一个典型的小公司因一个爆款项目火起来的案例,不管是技术层面、公司经营层面以及如何跟大厂缠斗,不管是好的方面还是坏的方面,都值得我们去学习和了解其背后的故事,Docker 这门技术成功了,Docker 这个公司却失败了
容器发展
下面我们看下容器技术的发展历史
chroot的引入
与普遍的看法相反,容器技术比人们预期的要古老得多,现代容器技术的最早祖先之一是
chroot命令,它于1979年在Version 7 Unix中引入
chroot命令可用于将进程与根文件系统隔离开来,并基本上将文件从进程中“隐藏”起来,并模拟一个新的根目录,隔离环境是所谓的chroot监狱,在这种环境中,进程无法访问文件,但文件仍然存在于系统中。
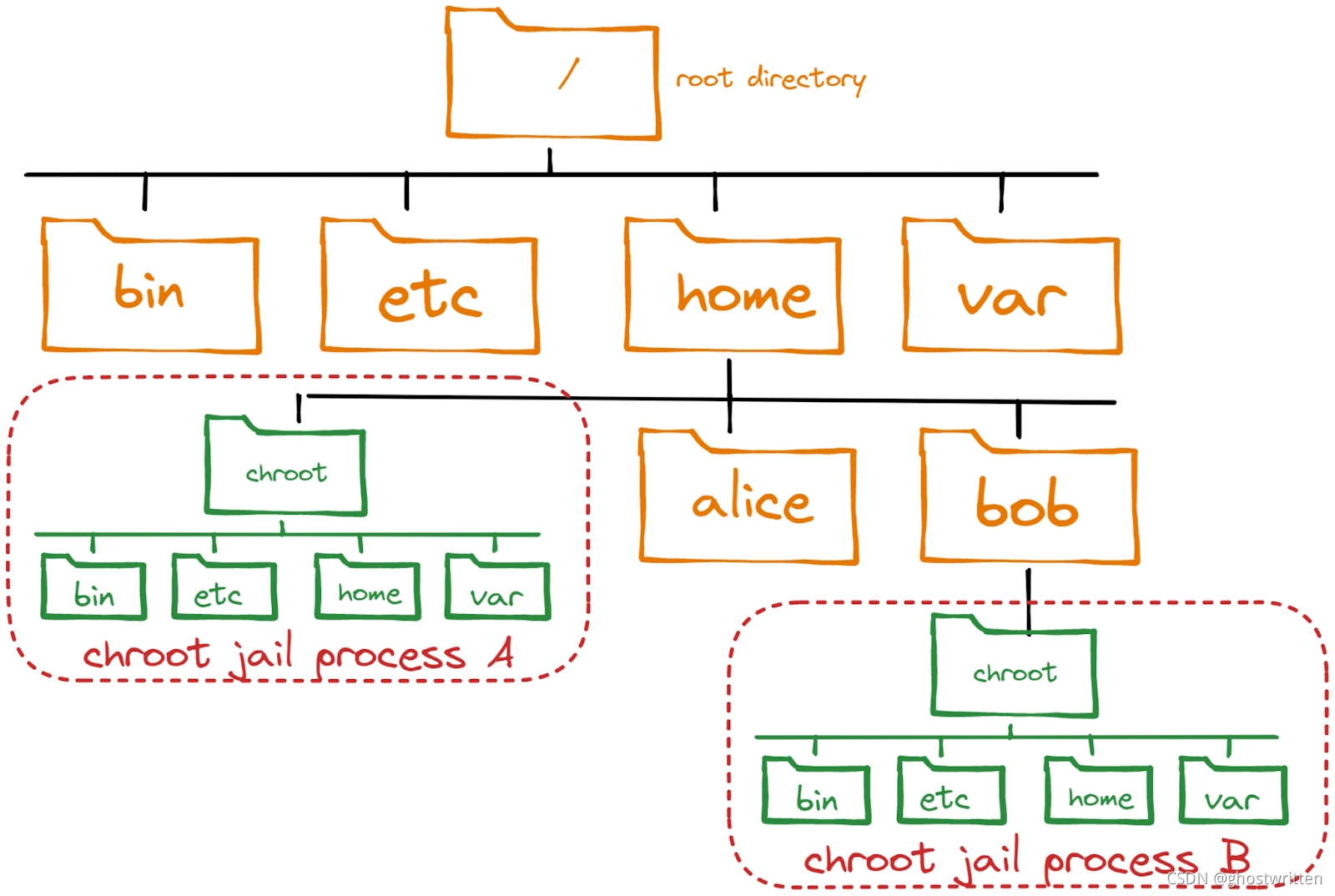
chroot的特性
虽然chroot是一项相当古老的技术,但它仍然在一些流行的软件项目中使用,我们今天拥有的容器技术仍然体现了这一概念,但是是一个现代化的版本,并且有很多特性。
为了比chroot更能隔离进程,当前的Linux内核提供了像命名空间和cgroup这样的特性。
命名空间用于隔离各种资源,例如网络,可以使用网络名称空间提供网络接口和路由表的完整抽象,这允许进程拥有自己的IP地址。
cgroup被用来组织层次结构组中的进程,并为它们分配资源,如内存和CPU,当你想限制你的应用程序容器的内存,比方说4GB, cgroup被用来确保这些限制。
LXC
LXC是
Linux containers的简称,Linux Container容器是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源

完整的LXC能力在2008年合入Linux主线,所以容器的概念在2008年就基本定型了,并不是后面Docker造出来的,关于LXC的介绍很多,大体都会说“LXC是Linux内核提供的容器技术,能提供轻量级的虚拟化能力,能隔离进程和资源”,但总结起来,无外乎就两大知识点Cgroups(Linux Control Group)和Linux Namespace,搞清楚他俩,容器技术就基本掌握了。
主要技术点
Linux容器技术其实就是整合内核的功能,让其支持多个容器运行时资源相互隔离
我们知道内核的功能用户是无法直接操作的,必须得有一用户空间的软件,通过系统调用去操作内核功能;所以lxc就是用来操作Linux内核容器化的工具
- chroot:创建一个虚拟的根目录文件系统 【实质还是调用底层的文件系统】,不过是建立一个虚拟的,可以跟其他容器的虚拟文件系统相互隔离,但共享底层的文件系统
- namespaces:命名空间可以提供一个进程相互隔离的独立网络空间,不同的容器间 进程pid可以相同,进程并不冲突影响;但可以共享底层的计算和存储(cpu + mem)
- CGroups:实现了对容器的资源分配和限制,比如给容器1分配10core 30G 内存;那这个容器最多用这么大的资源;如果内存超过30G ,会启动swap,效率降低,也可能会被调度系统给kill掉
LXC的优势
与传统虚拟化技术相比,它的优势在于:
- 与宿主机使用同一个内核,性能损耗小;
- 不需要指令级模拟;
- 不需要即时(Just-in-time)编译;
- 容器可以在CPU核心的本地运行指令,不需要任何专门的解释机制;
- 避免了准虚拟化和系统调用替换中的复杂性;
- 轻量级隔离,在隔离的同时还提供共享机制,以实现容器与宿主机的资源共享。
旧版 Docker
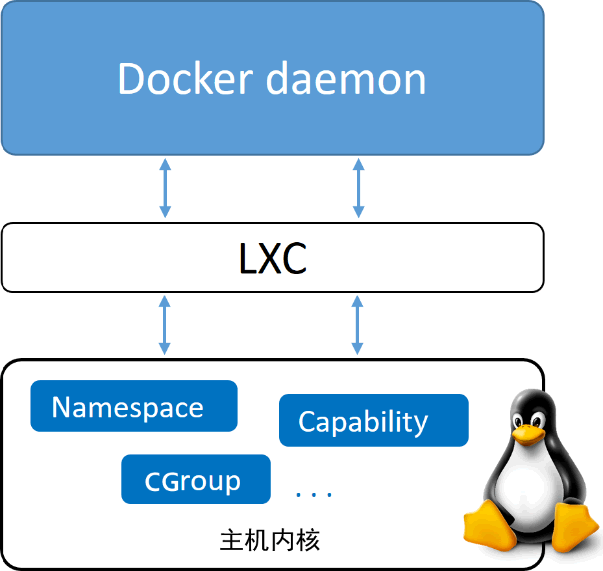
Docker 引擎首次发布的时候,由两个核心组件构成:LXC 和 Docker daemon
Docker deamon 是一个单一的二进制文件,由 Docker Client 、Docker API、容器运行时、构建镜像等组成, LXC 由命名空间 Namespace 和 控制组 CGroup 等基础工具组成,由 Linux 内核的容器虚拟化技术提供
摆脱 LXC的限制
对 LXC 的依赖自始至终都是个问题
首先,LXC 是基于 Linux 的,这对于一个立志于跨平台的项目来说是个问题。
其次,如此核心的组件依赖于外部工具,这会给项目带来巨大风险,甚至影响其发展。
因此,Docker 公司开发了名为 Libcontainer 的自研工具,用于替代 LXC,Libcontainer 的目标是成为与平台无关的工具,可基于不同内核为 Docker 上层提供必要的容器交互功能,在 Docker 0.9 版本中,Libcontainer 取代 LXC 成为默认的执行驱动,也就是现在常说的Runc。
拆分Docker daemon
随着时间的推移,Docker daemon 的整体性带来了越来越多的问题,难于变更、运行越来越慢,这并非生态(或Docker公司)所期望的。
Docker 公司意识到了这些问题,开始努力着手拆解这个大而全的 Docker daemon 进程,并将其模块化,这项任务的目标是尽可能拆解出其中的功能特性,并用小而专的工具来实现它,这些小工具可以是可替换的,也可以被第三方拿去用于构建其他工具。
这一计划遵循了在 UNIX 中得以实践并验证过的一种软件哲学:小而专的工具可以组装为大型工具,这项拆解和重构 Docker 引擎的工作仍在进行中,不过,所有容器执行和容器运行时的代码已经完全从 daemon 中移除,并重构为小而专的工具。

开放容器计划(OCI)
OCI标准制定
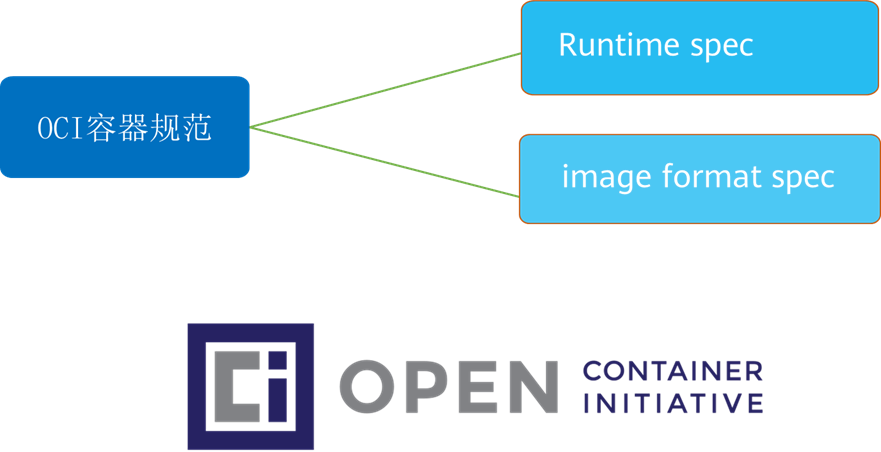
当 Docker 公司正在忙着进行 Docker daemon 进程的拆解和重构的时候,OCI 也正在着手定义两个容器相关的规范(或者说标准)
OCI目前包含两个标准: runtime-spec和image-spec,分别定义了容器运行时标准和容器镜像标准
镜像规范
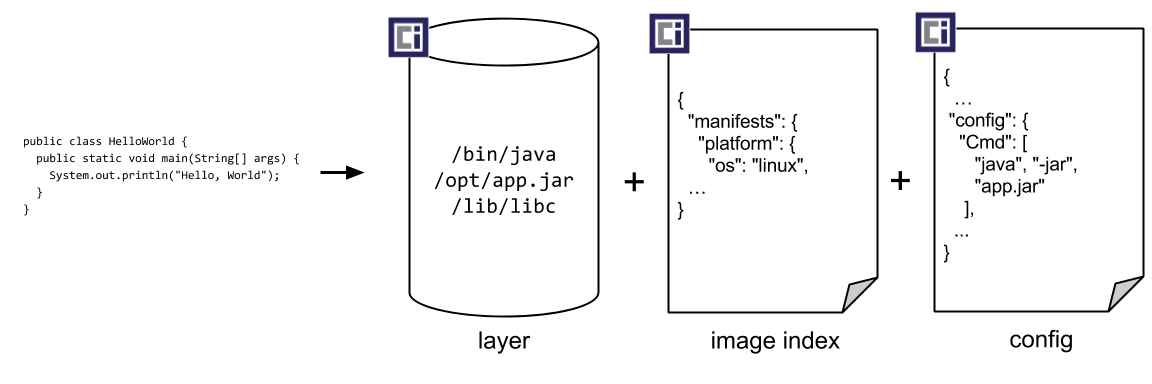
该规范的目标是创建可互操作的工具,用于构建、传输和准备运行的容器镜像,该规范的高层组件包括:
- 镜像清单— 一个描述构成容器镜像的元素的文件
- 镜像索引 — 镜像清单的注释索引
- 镜像布局— 一个镜像内容的文件系统布局
- 文件系统布局 — 一个描述容器文件系统的变更集
- 镜像配置— 确定镜像层顺序和配置的文件,以便转换成 运行时捆包
- 转换— 解释应该如何进行转换的文件
- 描述符— 一个描述被引用内容的类型、元数据和内容地址的参考资料
运行时规范
该规范用于定义容器的配置、执行环境和生命周期。
config.json 文件为所有支持的平台提供了容器配置,并详细定义了用于创建容器的字段,在详细定义执行环境时也描述了为容器的生命周期定义的通用操作,以确保在容器内运行的应用在不同的运行时环境之间有一个一致的环境。
Linux 容器规范使用了各种内核特性,包括 *命名空间(namespace)*、 *控制组(cgroup)*、 *权能(capability)*、LSM 和文件系统 *隔离(jail)*等来实现该规范。
runc
如前所述,runc 是 OCI 容器运行时规范的参考实现,Docker 公司参与了规范的制定以及 runc 的开发。
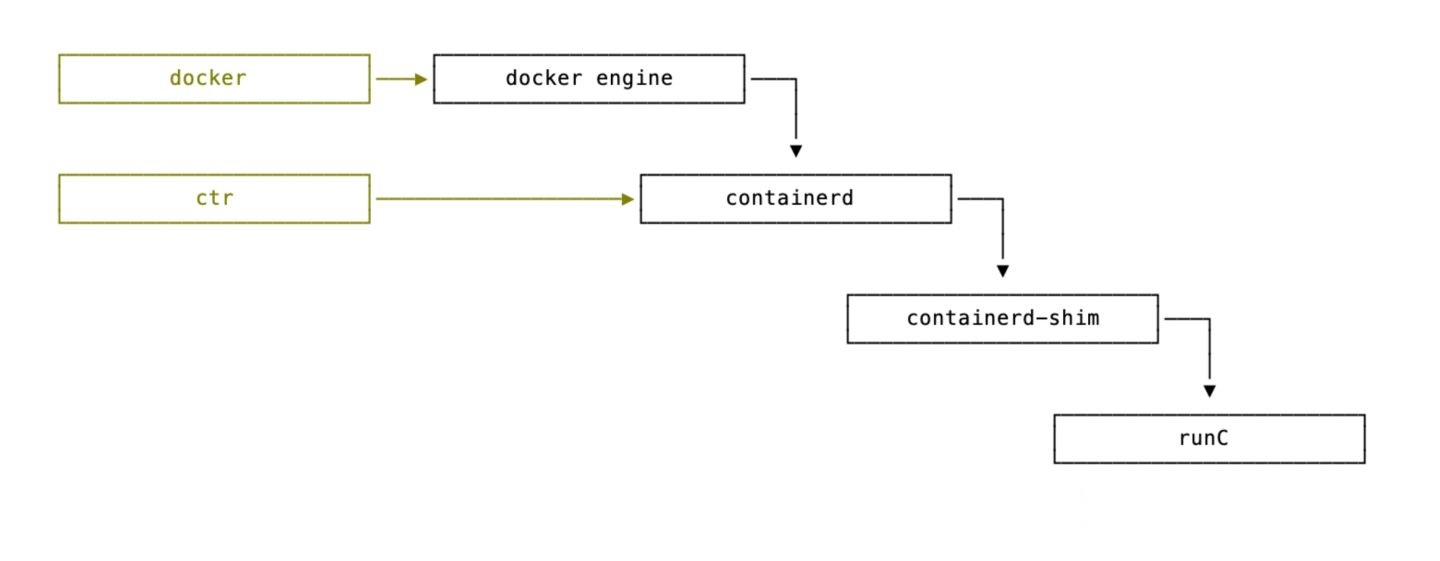
去粗取精,会发现 runc 实质上是一个轻量级的、针对 Libcontainer 进行了包装的命令行交互工具(Libcontainer 取代了早期 Docker 架构中的 LXC)
runc生来只有一个作用一创建容器,速度很快!不过它是一个CLI 包装器,实质上就是一个独立的容器运行时工具,因此直接下载它或基于源码编译二进制文件,即可拥有一个全功能的runc,但它只是一个基础工具,并不提供类似Docker引擎所拥有的丰富功能,有时也将runc所在的那一层称为“OCI 层”
containerd
在对 Docker daemon 的功能进行拆解后,所有的容器执行逻辑被重构到一个新的名为 containerd的工具中
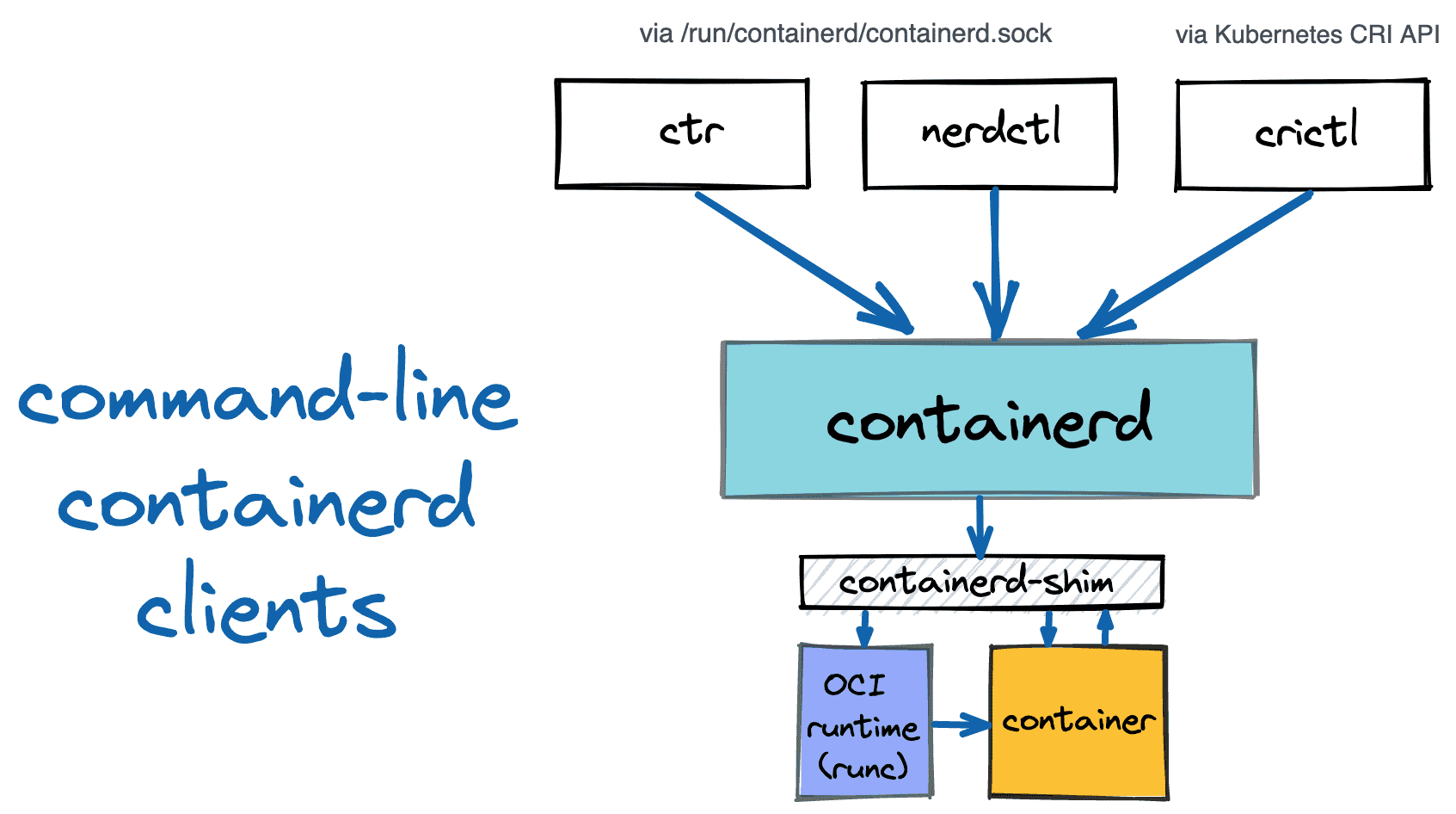
它是从 Docker 项目中分离出来,之后 containerd 被捐赠给云原生计算基金会(CNCF)为容器社区提供创建新容器解决方案的基础,所以 Docker 自己在内部使用 containerd,当你安装 Docker 时也会安装 containerd
containerd 通过其 CRI 插件实现了 Kubernetes 容器运行时接口(CRI),它可以管理容器的整个生命周期,包括从镜像的传输、存储到容器的执行、监控再到网络
containerd 在 Linux 和 Windows 中以 daemon 的方式运行,从 1.11 版本之后 Docker 就开始在 Linux 上使用它,Docker 引擎技术栈中,containerd 位于 daemon 和 runc 所在的 OCI 层之间。Kubernetes 也可以通过 cri-containerd 使用 containerd。
如前所述,containerd 最初被设计为轻量级的小型工具,仅用于容器的生命周期管理,然而,随着时间的推移,它被赋予了更多的功能,比如镜像管理。
全新的Docker引擎
Docker 引擎是用来运行和管理容器的核心软件,通常人们会简单地将其代指为 Docker 或 Docker 平台。
Docker 可以轻松地构建容器镜像,从 Docker Hub 中拉取镜像,创建、启动和管理容器,实际上,当你用 Docker 运行一个容器时实际上是通过 Docker 守护程序、containerd 和 runc 来运行它
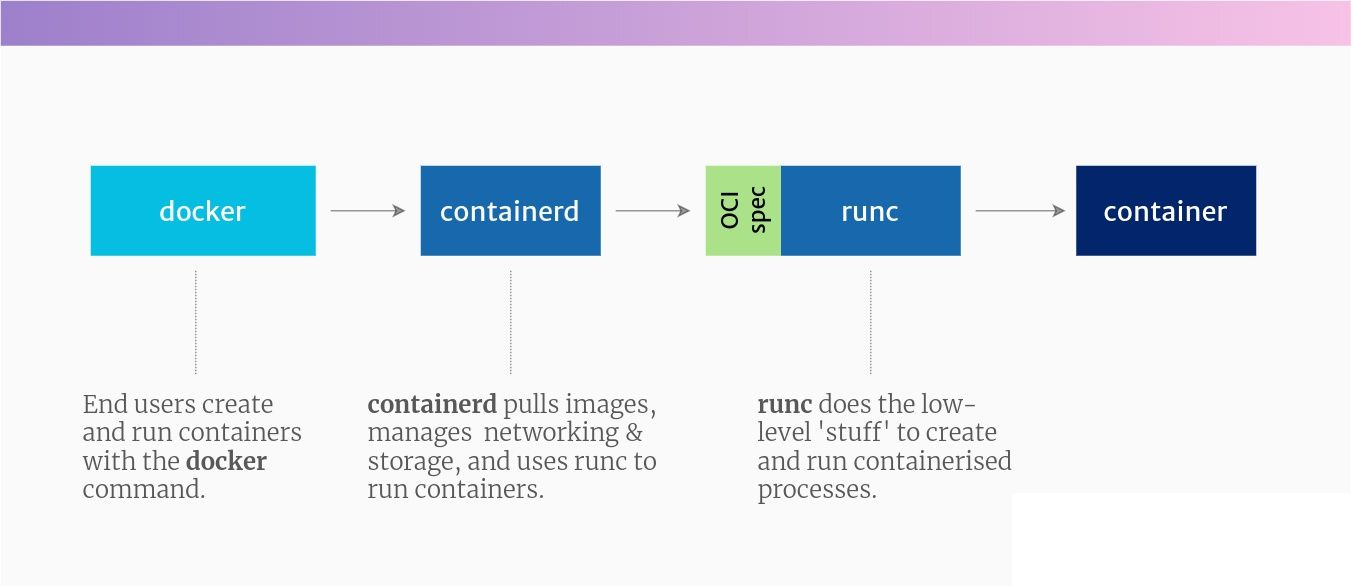
基于开放容器计划(OCI)相关标准的要求,Docker 引擎采用了模块化的设计原则,其组件是可替换的,为了实现这一切,Docker 是由这些项目组成(还有其他项目,但这些是主要的)
- docker-cli:这是一个命令行工具,它是用来完成
docker pull,build,run,exec等命令进行交互。 - containerd:这是一个管理和运行容器的守护进程,它推送和拉动镜像,管理存储和网络,并监督容器的运行
- runc:这是低级别的容器运行时间(实际创建和运行容器的东西),它包括 libcontainer,一个用于创建容器的基于 Go 的本地实现
运行容器
要运行行业标准的容器,你不需要使用Docker,您可以只遵循OCI 规范标准
Open Container Initiative还维护一个名为runC的容器运行时引用实现,这种低级运行时被用于各种工具来启动容器,包括Docker本身。
容器的实质
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间
因此容器可以拥有自己的root文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下操作一样。
这种特性使得容器封装的应用比直接在宿主运行更加安全,也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机
容器运行过程
如果您是一名开发人员,并且了解面向对象编程,您可以想象容器映像和运行容器之间的关系,就像一个类,以及该类的实例化,安装Docker后,你可以像这样启动容器:
1 | docker run nginx |
当使用 Docker 命令行工具执行如上命令时,Docker 客户端会将其转换为合适的 API 格式,并发送到正确的 API 端点,API 是在 daemon 中实现的,这套功能丰富、基于版本的 REST API 已经成为 Docker 的标志,并且被行业接受成为事实上的容器 API。
一旦 daemon 接收到创建新容器的命令,它就会向 containerd 发出调用,daemon 已经不再包含任何创建容器的代码了,daemon 使用一种 CRUD 风格的 API,通过 gRPC 与 containerd 进行通信。
虽然名叫 containerd,但是它并不负责创建容器,而是指挥 runc 去做,containerd 将 Docker 镜像转换为 OCI bundle,并让 runc 基于此创建一个新的容器。
然后,runc 与操作系统内核接口进行通信,基于所有必要的工具(Namespace、CGroup等)来创建容器。容器进程作为 runc 的子进程启动,启动完毕后,runc 将会退出。

模型优势
可以实现容器和Docker daemon解耦,重启docker进程不会在导致所有容器销毁了
将所有的用于启动、管理容器的逻辑和代码从 daemon 中移除,意味着容器运行时与 Docker daemon 是解耦的,有时称之为“无守护进程的容器(daemonless container)”,如此,对 Docker daemon 的维护和升级工作不会影响到运行中的容器。
在旧模型中,所有容器运行时的逻辑都在 daemon 中实现,启动和停止 daemon 会导致宿主机上所有运行中的容器被杀掉。
这在生产环境中是一个大问题——想一想新版 Docker 的发布频次吧!每次 daemon 的升级都会杀掉宿主机上所有的容器,这太糟了!
shim
shim是一个真实运行的容器的真实垫片载体,每启动一个容器都会起一个新的docker-shim的一个进程
shim是实现无daemon的容器(用于将运行中的容器与daemon解耦,以便进行daemon升级等操作)不可或缺的工具
containerd 指挥runc来创建新容器,事实上,每次创建容器时它都会fork一个新的runc实例,不过,一旦容器创建完毕,对应的runc进程就会退出,因此,即使运行上百个容器,也无须保持上百个运行中的runc实例。
一旦容器进程的父进程runc退出,相关联的containerd-shim 进程就会成为容器的父进程,作为容器的父进程,shim 的部分职责如下
- 保持所有STDIN和STDOUT流是开启状态,从而当daemon重启的时候,容器不会因为管道( pipe)的关闭而终止
- 将容器的退出状态反馈给daemon
容器生态系统
容器生态系统是由许多令人兴奋的技术、大量的专业术语和大公司相互争斗组成的
幸运的是,这些公司偶尔会在休战中走到一起合作,商定一些标准,这些标准有助于使这个生态系统在不同的平台和操作系统之间更具互操作性,并减少对单一公司或项目的依赖。
这张图显示了 Docker、Kubernetes、CRI、OCI、containerd 和 runc 在这个生态系统中是如何结合的
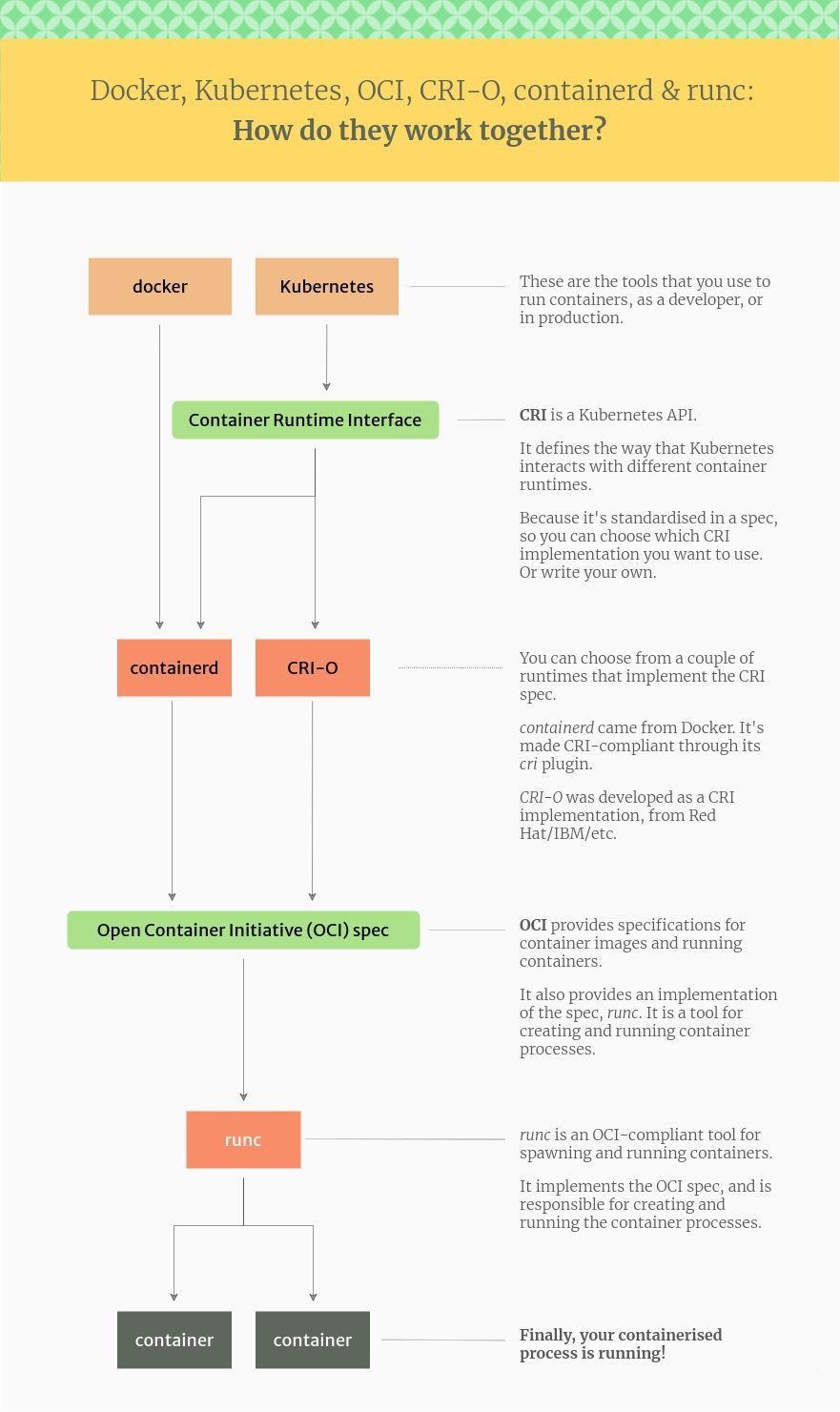
构建镜像
Docker重用了所有组件来隔离进程,比如
namespaces和cgroup,但是帮助容器实现突破的关键是容器映像的引入
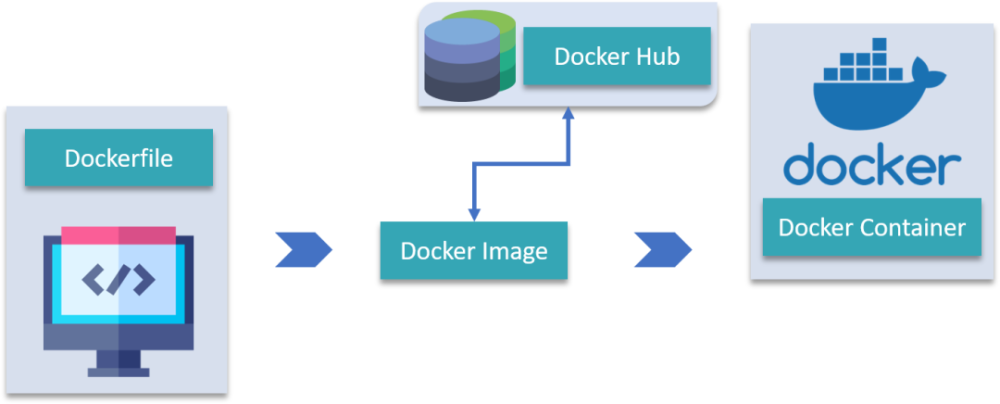
容器镜像使的容器具有可移植性,并且易于在各种系统上重用,Docker对容器镜像的描述如下:Docker容器镜像是一个轻量级的、独立的、可执行的软件包,它包含运行应用程序所需的一切:代码、运行时、系统工具、系统库和设置。
可以通过从一个名为
Dockerfile的构建文件中读取说明来构建映像,这些说明几乎与在服务器上安装应用程序时使用的说明相同
1 | FROM openjdk:8-jdk-alpine |
如果你已经在你的机器上安装了Docker,你可以用下面的命令来构建镜像:
1 | docker build -t learn-docker-storage -f Dockerfile |
分层存储
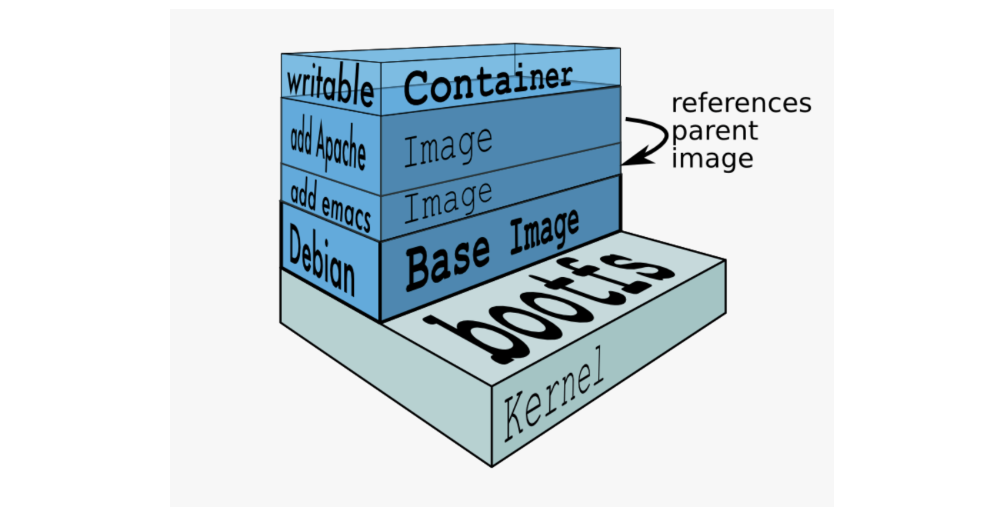
镜像只是一个虚拟的概念,其实际体现并非由一个文件组成,而是由一组文件系统组成,或者说,由多层文件系统联合组成
Union FS
联合文件系统是(Union FS)是linux的存储技术,也是Docker镜像的存储方式。
它是分层的文件系统,将不同目录拉到同一个虚拟目录下,下图展示了Docker用Union FS 搭建的分层镜像:(比如最下层是操作系统的引导,上一层是Linux操作系统,再上一层是Tomcat,jdk,再上一层是应用代码)
这些层是只读的,加载完后这些文件会被看成是同一个目录,相当于只有一个文件系统。
镜像&容器
容器技术由两部分组成:
- 镜像(特殊格式的打包文件):包含了程序、程序依赖的Lib、环境,本质上就是一个压缩包(它解决了环境一致性的问题)
- 容器(依赖内核功能创建的镜像运行空间):是内核创建的一个隔离的空间,运行镜像(它解决了隔离问题防止程序互相干扰)
容器安全
理解容器与虚拟机有不同的安全需求是很重要的,很多人依赖于容器的隔离特性,但这可能是非常危险的

内核漏洞
与虚拟机系统不同,全部容器及其主机使用的都是同一套共享内核,因此该内核中存在的任何安全漏洞都有可能造成巨大影响
如果某套容器系统导致内核崩溃,那么这反过来又会造成整台主机上的全部容器毁于一旦,在虚拟机当中,情况则要好得多:攻击者必须借道虚拟机内核与虚拟机管理程序之后,才有可能真正接触到主机内核
拒绝服务攻击
所有容器都共享同样的内核资源,如果某套容器能够以独占方式访问某些资源——包括内存以及用户ID等其它更为抽象化的资源——那么与其处于同一台主机上的其它容器则很可能因资源匮乏而无法正常运转,这正是拒绝服务攻击(简称DoS)的产生原理,即合法用户无法对部分或者全部系统进行访问
容器越权
能够访问某一容器的攻击者在原则上应该无法借此访问到其它容器或者主机。
在默认情况下,用户并不具备命名空间,因此游离于容器之外的任何进程都将在主机之上获得与容器内相同的执行权限; 而如果大家在容器内拥有root权限,那么在主机上亦将具备root身份。
这意味着大家需要对这种潜在的权限提升攻击做好准备——这类攻击意味着用户往往通过应用程序代码中需要配合额外权限的bug实现权限提升,从而使攻击者获得root或者其它级别的访问与操纵能力,考虑到容器技术目前仍处于早期发展阶段,因此我们在规划自己的安全体系时,必须要将这种容器突破状况考虑在内。
含毒镜像
那么我们要如何判断自己使用的镜像是否安全、是否存在篡改或者其宣称的来源是否可靠?
如果攻击者诱导大家运行由其精心设计的镜像,那么各位的主机与数据都将处于威胁之下,同样的,大家还需要确保自己运行的镜像为最新版本,且其中不包含任何存在已知安全漏洞的软件版本。
容器编排
在本地机器或单个服务器上运行几个容器是相当容易的,但是容器的使用方式带来了关于容器操作的新挑战,这个概念的高效率导致应用程序和服务变得越来越小,您会发现现代应用程序可以由许多容器组成。
如今,像Docker这样的容器平台非常流行,用于基于微服务架构的应用程序打包,可以使容器具有高度可伸缩性,可以按需创建容器,虽然这对于几个容器来说是很好的,但请想象您有数百个。
当数量随需求动态增加时,管理容器生命周期及其管理变得极为困难。
容器编排通过自动化容器的调度,部署,可伸缩性,负载平衡,可用性和联网来解决该问题。容器编排是容器和服务生命周期的自动化和管理。
理解容器编排
Docker平台以及周边生态系统包含很多工具来管理容器的生命周期。
例如,Docker Command Line Interface(CLI)满足在单个主机上管理容器的需求,但是面对部署在多个主机上的容器时就无所适从了,为了超越单个容器管理,我们必须转向编排工具,容器编排工具将生命周期管理能力扩展到部署在大量机器集群上部署的复杂的、多容器工作负载。
容器编排工具为开发人员和基础设施团队提供了一个抽象层来处理大规模的容器化部署,容器编排工具提供的特征在众多提供者之间有所不同,然而常见的公共特征包含准备、发现、资源管理、监视和部署。
容器编排作用
容器编排工具的一些关键能力概括如下
- 集群管理:将虚拟机和物理机器的集群管理为一台大型机器。这些机器在资源能力方面可能有些差异,但大体上都是以Linux作为操作系统的机器。这些虚拟集群可以建立在云上、本地或两者的混合。
- 部署:能处理有大量机器的应用程序和容器的自动部署。支持多个版本的应用程序容器,并且还支持跨越大量集群机器的滚动升级。这些工具还能够处理故障回滚。
- 可伸缩性:支持应用实例的自动和手动伸缩,以性能优化为主要目标。
- 健康:它管理集群、节点和应用程序的健康。可以从集群中移除异常的机器和应用程序实例。
- 基础结构抽象化:开发人员不必担心机器、容量等问题。完全是容器编排工具来决定如何调度和运行应用程序。这些工具也抽象化机器的细节、能力、使用和位置。对于应用程序所有者来说,它们相当于一个容量几乎无限的大型机器。
- 资源优化:这些工具以有效的方式在一组可用机器上分配容器工作负载,从而降低成本,通过从简单的到复杂的算法可有效地提高利用率。
- 资源分配:基于应用程序开发人员设置的资源可用性和约束来分配服务器。资源分配将基于约束、规则、端口要求、应用依赖性、健康等等。
- 服务可用性:确保服务在集群中正常运行。在机器故障的情况下,容器编排会自动通过在集群中的其他机器上重新启动这些服务来处理故障。
- 敏捷性:敏捷性工具能够快速分配工作负载到可用资源,或者在资源需求发生变化时跨机器移动工作量。此外,可以根据业务临界性、业务优先级等来设置约束重新调整资源。
- 隔离:一些工具提供了资源隔离。因此,即使应用程序不是容器化的,也可以实现资源隔离
常用的任务编排工具
docker-compose

docker-compose是基于docker的编排工具,使容器的操作能够批量的,可视的执行,是一个管理多个容器的工具,比如可以解决容器之间的依赖关系,当在宿主机启动较多的容器时候,如果都是手动操作会觉得比较麻烦而且容器出错,这个时候推荐使用 docker的单机编排工具 docker-compose。
Docker Swarm
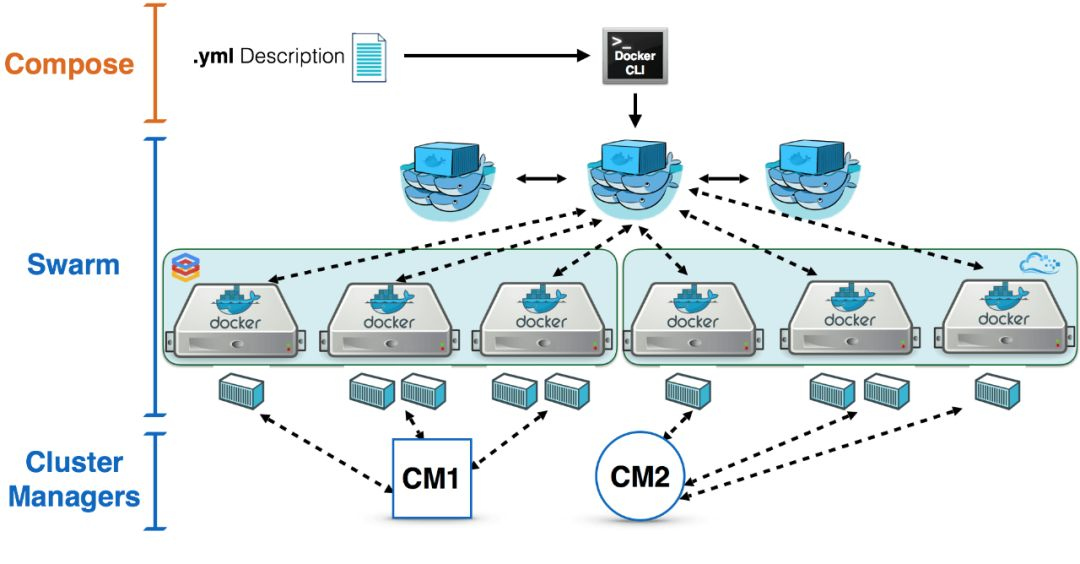
Docker生态系统包括从开发到生产部署框架的工具,在该列表中,docker swarm适用于集群管理,可以使用docker-compose,swarm,overlay网络和良好的服务发现工具(例如etcd或consul)的组合来管理Docker容器集群。
与其他开源容器集群管理工具相比,Docker swarm在功能方面仍日趋成熟,考虑到庞大的Docker贡献者,Docker swarm拥有其他工具拥有的所有最佳功能不会太久,Docker记录了在生产中使用docker swarm 的良好生产计划。
Kubernetes
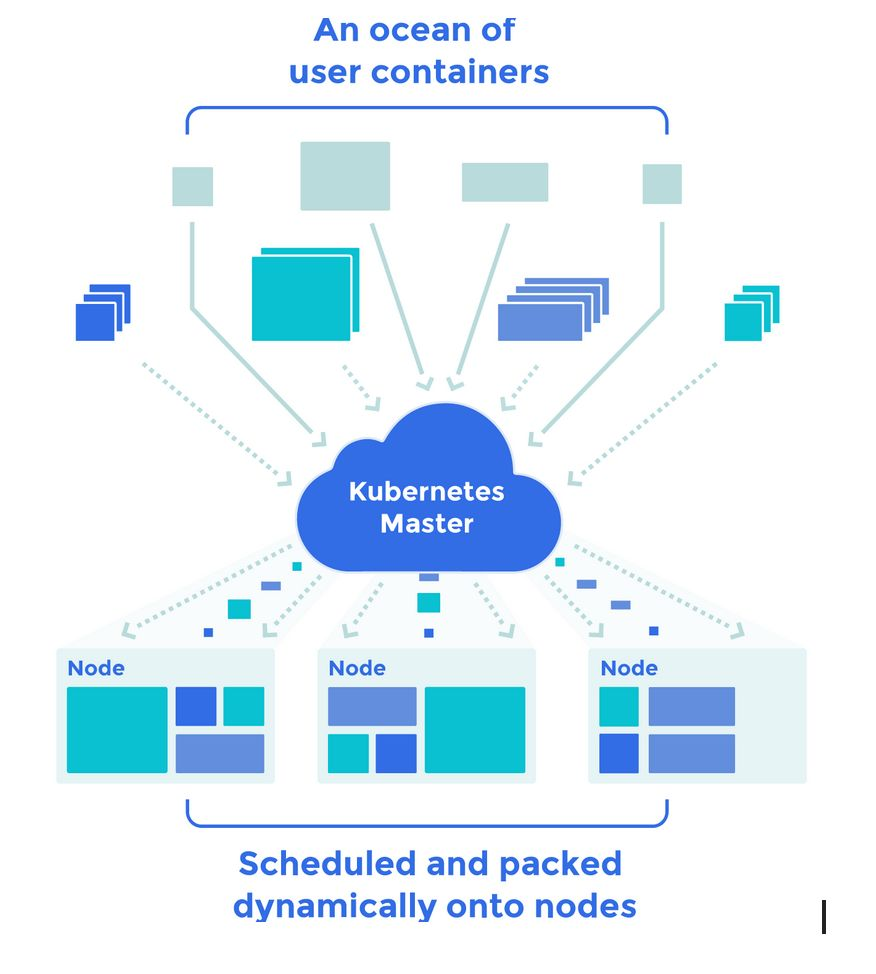
Kubernetes是一个开源的,开箱即用的容器集群管理器和业务流程,它具有出色的构建 调度器 和资源管理器,用于以更有效和高度可用的方式部署容器,Kubernetes已成为许多组织事实上的容器编排工具,kubernetes项目由google与世界各地的贡献者维护,它提供了本机Docker工具不提供的许多功能,而且,使用kubernetes很容易上手。
OpenShift
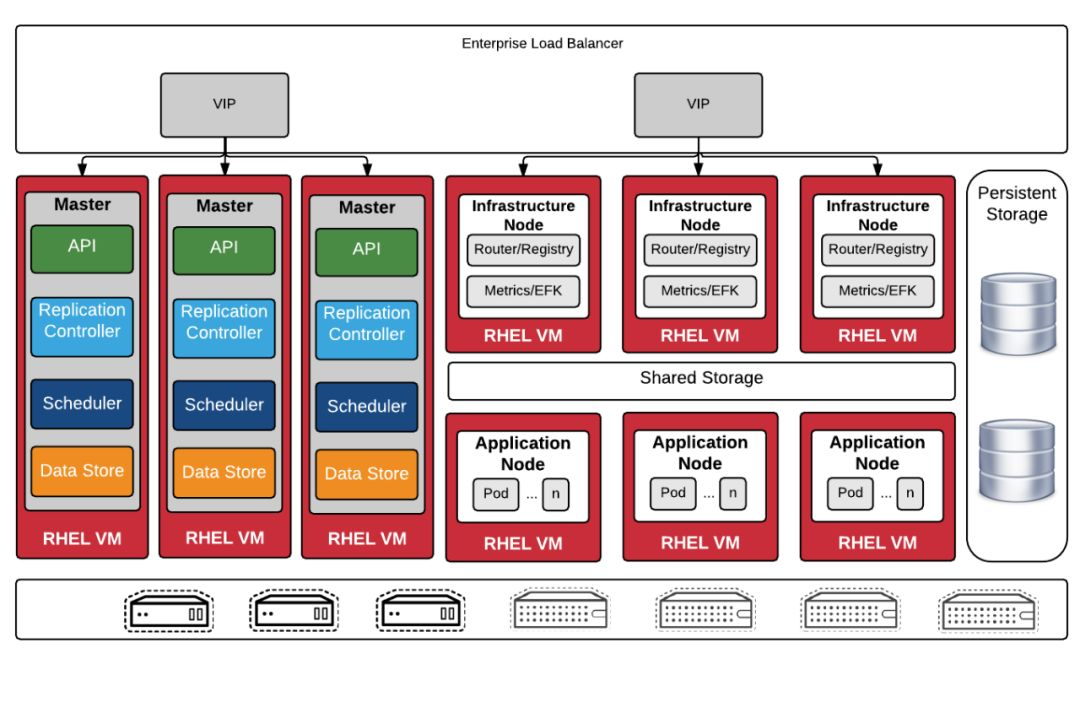
Openshift建立在kubernetes之上,Openshift项目由Redhat维护,它同时具有开源(openshift orgin)和企业版(openshift容器平台),连同核心的Kubernetes功能,它提供了用于容器管理和编排的开箱即用组件。
持续集成
DevOps是一种方法或理念,它涵盖开发、测试、运维的整个过程
什么是持续集成
DevOps(Deveplopment和Operations的简称),中译为开发运维一体化,可定义为是一种过程、方法、文化、运动或实践
主要是为了通过一条高度自动化的流水线来加强开发和其他IT职能部门之间的沟通和协作,加速软件和服务的交付,在一个较成熟的软件和服务交付的团队里,就技术层面来说主要分为三个组成部分:开发、测试和运维。DevOps的作用就是将这三个部分紧密的连接起来,提供一条从软件开发到质量保障到技术运营的自动化流水线,加强不同角色之间的沟通和协作,基于用户需求实现软件和服务的快速交付。
DevOps落地
技术层面
DevOps不是一个工具,但它需要被工具来实现,好在现今已经有了很多商业版和开源版的软件来形成一个有效的工具链来作为DevOps技术层面的支撑。
但是光有工具还不够,再好的工具没人会用也没意义,所以需要有熟悉这个工具链的IT人员来提供技术支持,利用工具实现DevOps的高度自动化。
流程层面
DevOps是一条从开发到运维的流水线,想要流水线能够高效的自动运行,必须要设定一系列的流程和规范来进行管控。
IT的管理者需要有基于软件或服务交付的全局观,能够清晰的认识到交付周期中不同角色的痛点在哪里,进而定制出合适的协作流程。
组织层面
DevOps并不是简单的将开发部门和运维部门合并,而是加强开发部门和运维部门之间的协作和沟通。
这需要管理者们对企业的IT部门有着足够的重视并且愿意去推动DevOps这种开发和运维间高效协作的模式,并且开发和运维的人员之间也需要有开放、接纳和协作的意识。
DevOps是一个虚无缥缈的玩意儿,它并不能被工具或软件来简单的定义或量化,但工具或软件却是实现DevOps的一个重要组成部分,而Docker就是实现DevOps最合适的工具之一。
容器实现DevOps的优势
环境标准化
开发、测试和生产环境的统一化和标准化
镜像作为标准的交付件,可在开发、测试和生产环境上以容器来运行,最终实现三套环境上的应用以及运行所依赖内容的完全一致。
解决环境异构
解决底层基础环境的异构问题
基础环境的多元化造成了从Dev到Ops过程中的阻力,而使用Docker Engine可无视基础环境的类型,不同的物理设备,不同的虚拟化类型,不同云计算平台,只要是运行了Docker Engine的环境,最终的应用都会以容器为基础来提供服务。
使用简单
易于构建、迁移和部署。
Dockerfile实现镜像构建的标准化和可复用,镜像本身的分层机制也提高了镜像构建的效率,使用Registry可以将构建好的镜像迁移到任意环境,而且环境的部署仅需要将静态只读的镜像转换为动态可运行的容器即可。
轻量和高效
相对于虚拟机来说轻量和高效
和需要封装操作系统的虚拟机相比,容器仅需要封装应用和应用需要的依赖文件,实现轻量的应用运行环境,且拥有比虚拟机更高的硬件资源利用率。
快速部署
工具链的标准化和快速部署。
将实现DevOps所需的多种工具或软件进行Docker化后,可在任意环境实现一条或多条工具链的快速部署。
容器网络
微服务架构在很大程度上依赖于网络通信,与单片应用程序不同,微服务实现了一个接口,可以调用该接口来发出请求
网络命名空间允许每个容器拥有自己唯一的IP地址,因此多个应用程序可以打开相同的网口,例如,您可以有多个容器化的web服务器,它们都开放端口8080,为了使应用程序可以从主机系统外部访问,容器能够将容器中的一个端口映射到主机系统中的一个端口,为了允许容器跨主机进行通信,我们可以使用overlay network,将它们放在跨越主机系统的虚拟网络中。
这使得容器之间的通信非常容易,而系统管理员不需要在主机和容器之间配置复杂的网络和路由,大多数覆盖网络还需要处理IP地址管理,如果手动实现,这将是大量的工作,在这种情况下,覆盖网络管理哪个容器获得哪个IP地址,以及流量如何流动以访问各个容器。
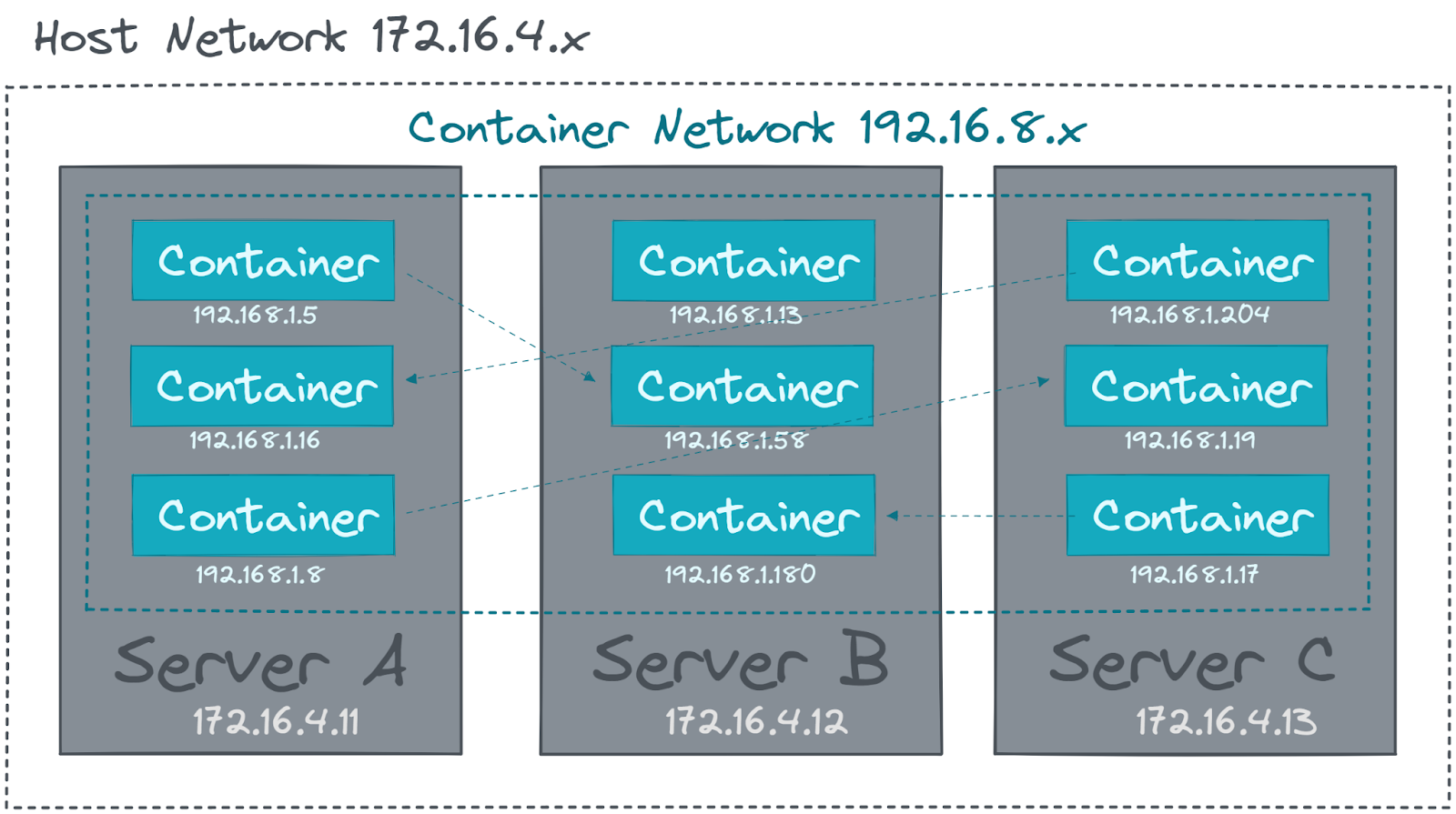
四种网络
基于docker run创建容器时,可以使用–net选项指定容器的网络模式:Docker默认有以下4种网络模式:
- bridge模式,使用–net=bridge指定,默认设置
- host模式,使用–net=host指定
- none模式,使用–net=none指定
- container模式,使用–net=container:NAME_or_ID指定
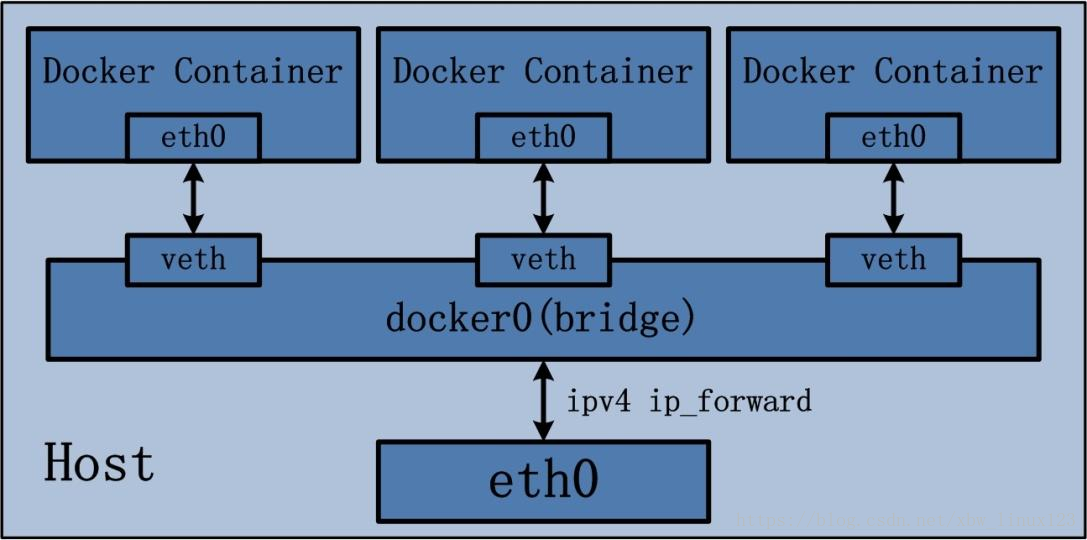
桥接网络
docker bridge网络模式会为每个容器分配地址,当docker启动时会自动创建一个docker0的网卡,它在内核层连通了其他的物理或虚拟网卡,这就将所有容器和宿主机都放到同一个二层网络
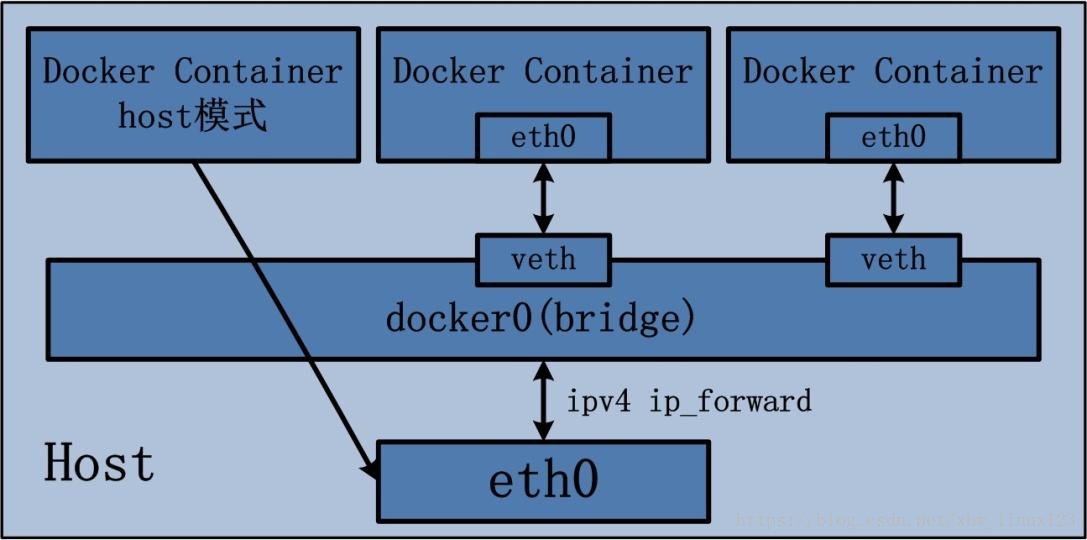
host网络
host网络模式其实就是容器和主机host共享一个网络
容器完全使用主机的网络,不对网络容器做任何隔离,优点是性能好,缺点是容器网络缺少隔离性,增加风险,由于容器和宿主机使用同一网络,当宿主机容器多时,网络资源会受到限制
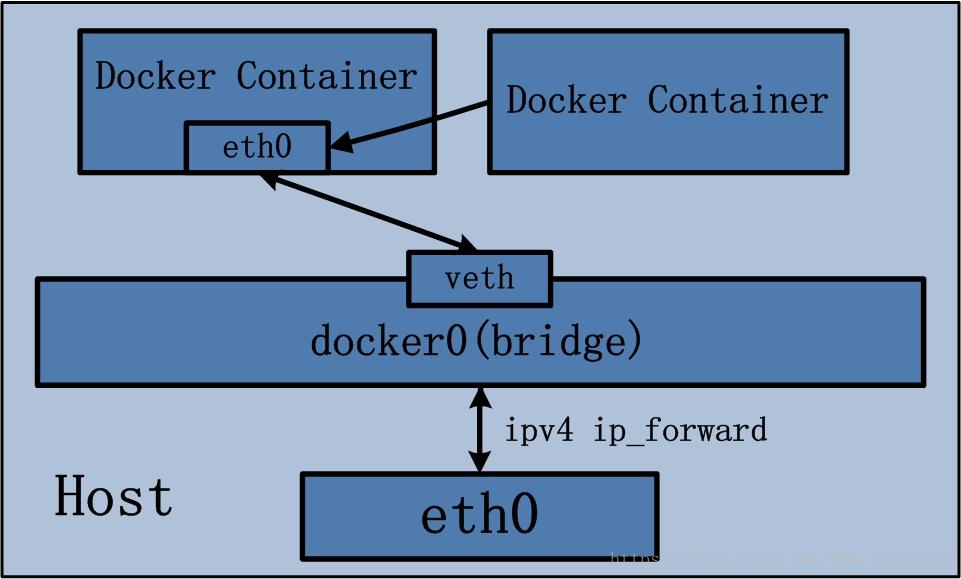
container模式
docker的container模式就是在容器创建时指定另一个容器,与它共享一个网络
none网络
none网络模式会使容器禁用网络功能,只保留一个回环网卡。
none模式不参与网络配置,如果想针对none模式做网络配置,需要第三方的服务。none模式使容器不再局限于docker自带的网络模式
容器存储
文件系统结构
Docker镜像由多个只读层叠加而成,启动容器时,docker会加载只读镜像层并在镜像栈顶部加一个读写层;
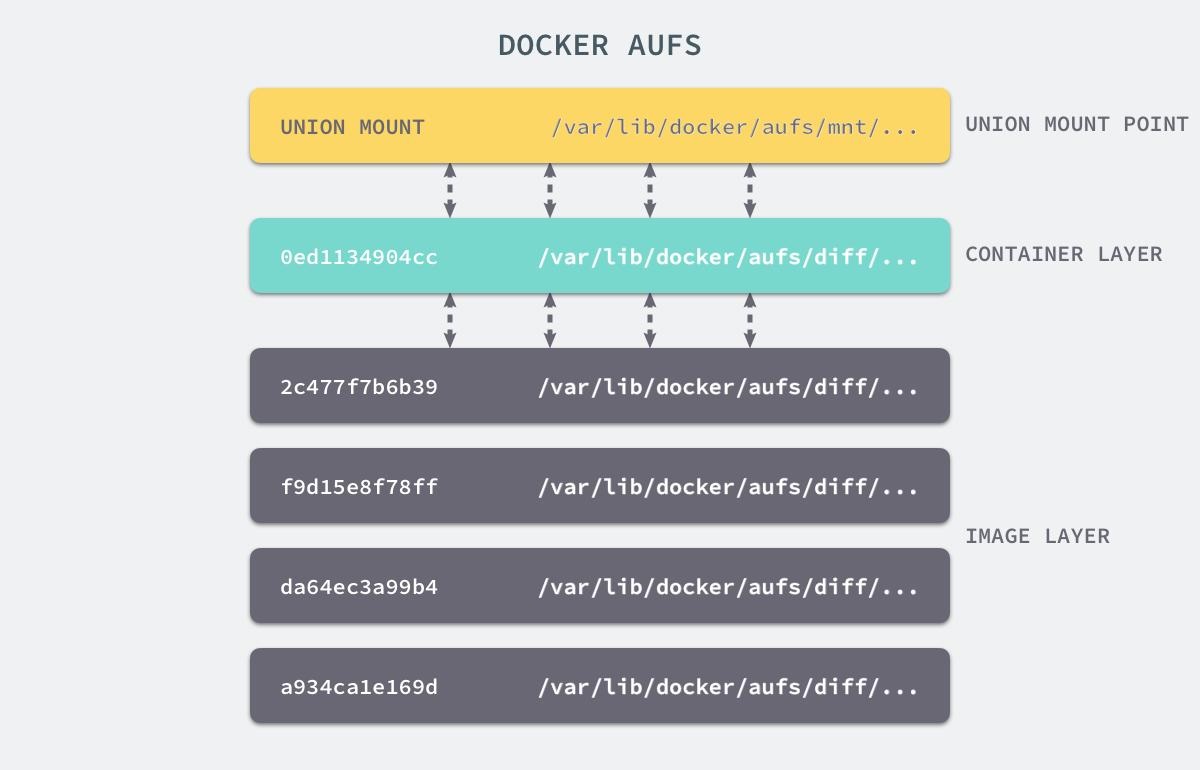
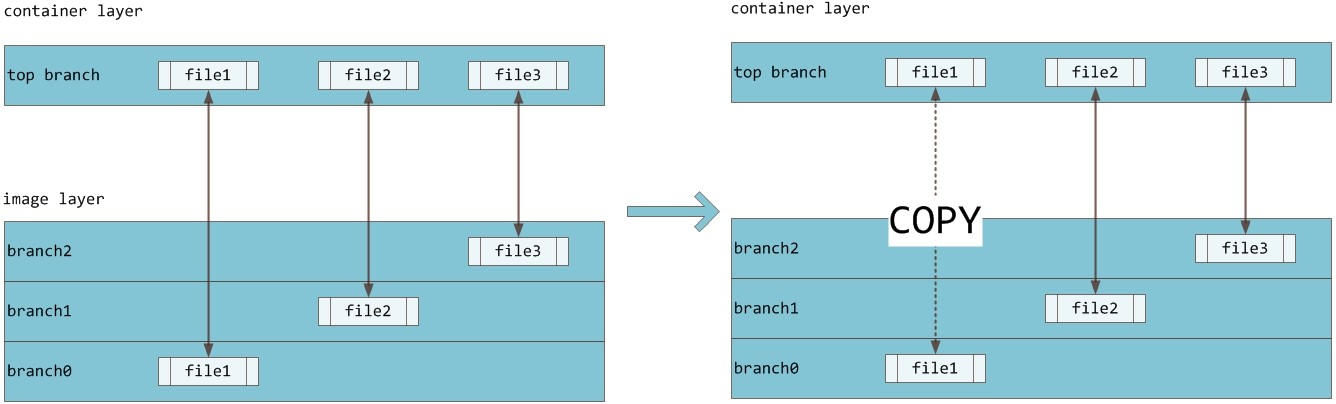
如果运行中的容器修改了现有的一个已经存在的文件,那该文件将会从读写层下面的只读层复制到读写层,该文件版本仍然存在,只是已经被读写层中该文件的副本所隐藏,此即“写时复制(COW)”机制。
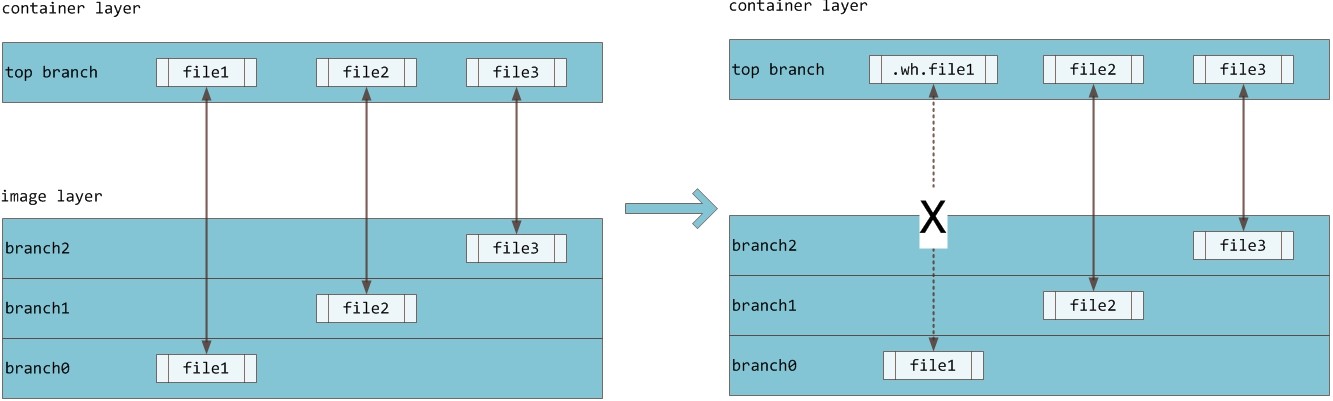
如果一个文件在最底层是可见的,如果在layer1上标记为删除,最高的层是用户看到的Layer2的层,在layer0上的文件,在layer2上可以删除,但是只是标记删除,用户是不可见的,总之在到达最顶层之前,把它标记来删除,对于最上层的用户是不可见的,当标记一删除,只有用户在最上层建一个同名一样的文件,才是可见的。
单机存储
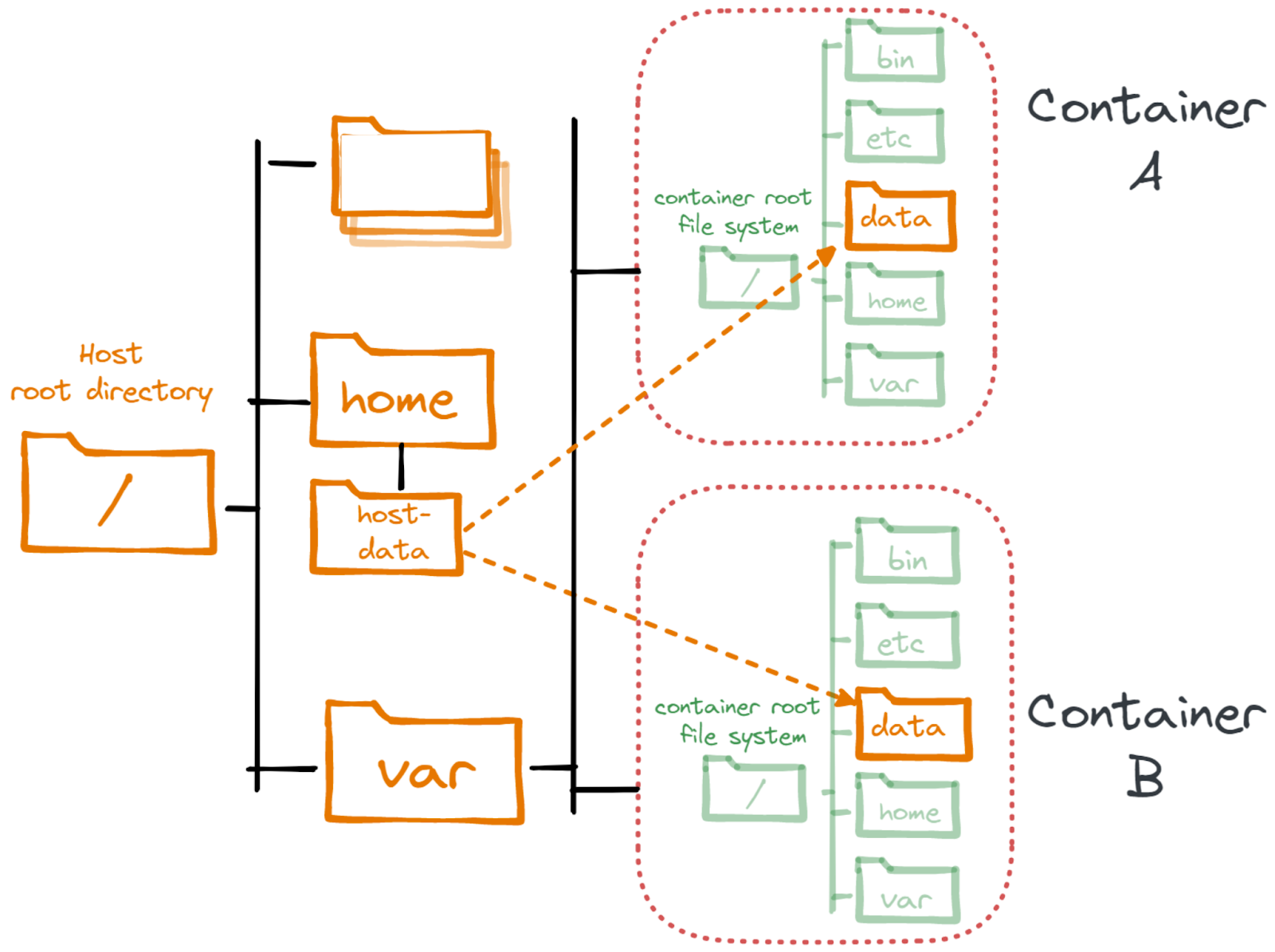
如果容器需要在主机上持久化数据,可以使用卷来实现这一点。
其概念和技术非常简单:不是隔离进程的整个文件系统,而是将驻留在主机上的目录传递到容器文件系统中。如果你认为这会削弱容器的隔离性,你是对的。当使用容器卷时,可以有效地访问主机文件系统。
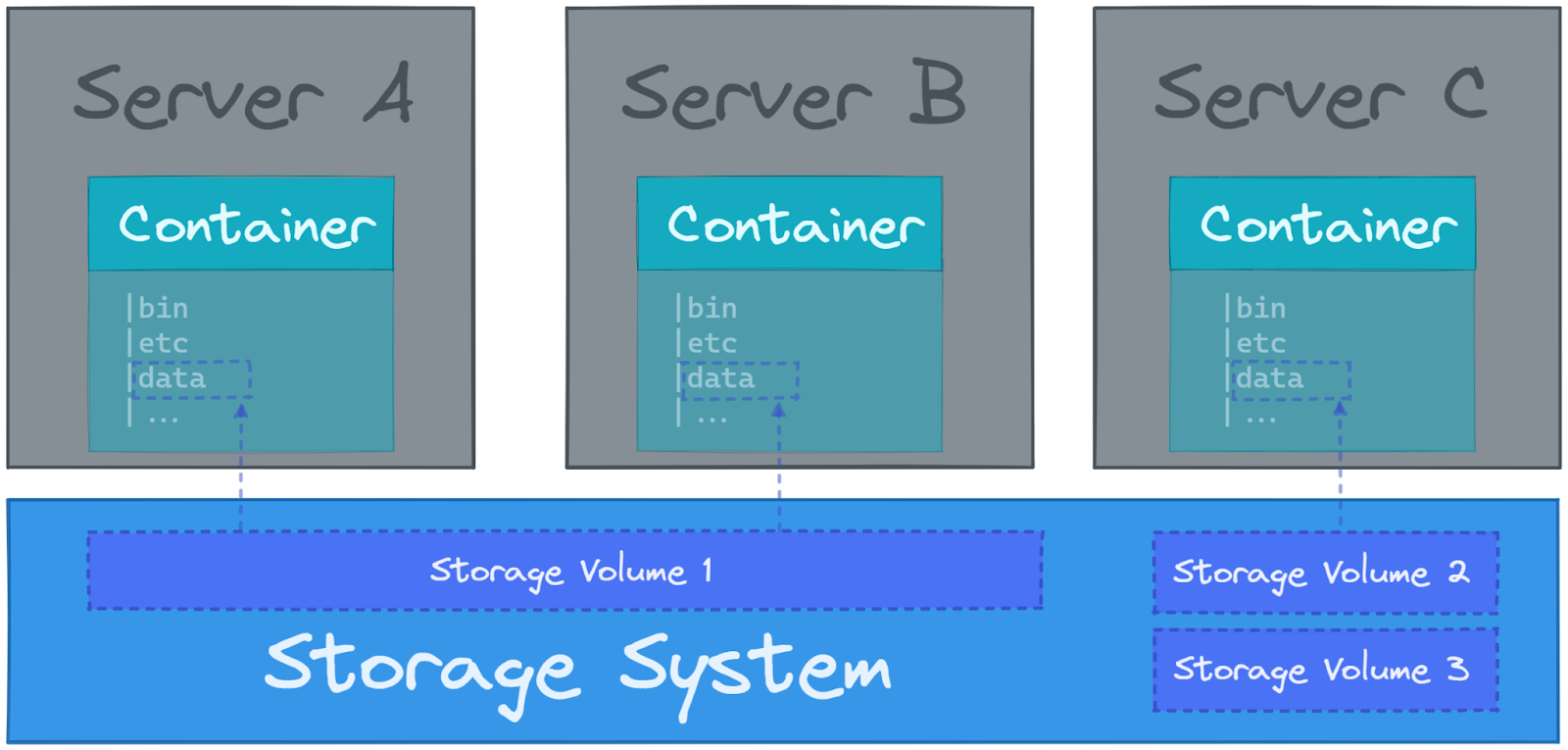
云存储
当您编排许多容器时,在启动容器的主机上持久化数据可能不是惟一的挑战。
通常,数据需要由在不同主机系统上启动的多个容器访问,或者当一个容器在不同主机上启动时,它仍然可以访问它的卷,像Kubernetes这样的容器编排系统可以帮助缓解这些问题,但总是需要一个连接到主机服务器的健壮存储系统。