ElasticSearch 集群管理

集群模式
Elasticsearch节点设计支持多种角色,这个是实现集群最重要的前提,节点角色各司其职,也可以任意组合,职责重合。
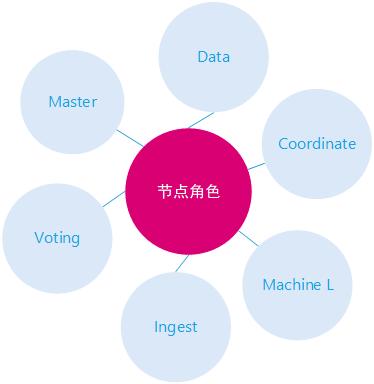
节点角色说明
- Master,集群管理
- Voting,投票选举节点
- Data,数据节点Ingest,数据编辑节点
- Coordinate,协调节点
- Machine Learning,集群学习节点
单节点
单节点模式默认开启所有节点特性,具备一个集群所有节点角色,可以认为是一个进程内部的集群
Elasticsearch在默认情况下,不用任何牌配置也可以运行,这也是它设计的精妙之处,相比其它很多数据产品集群配置,如Mongodb,简化了很多,起步入门容易。
基本高可用
elasticsearch集群要达到基本高可用,一般要至少启动3个节点,3个节点互相连接,单个节点包括所有角色,其中任意节点停机集群依然可用,为什么要至少3个节点?因为集群选举算法奇数法则。
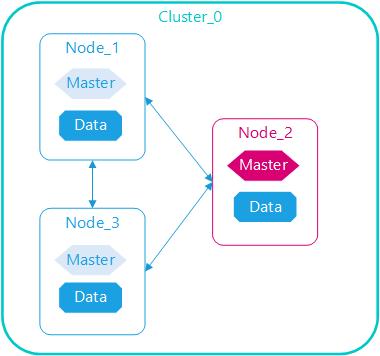
数据与管理分离
Elasticserach管理节点职责是管理集群元数据、索引信息、节点信息等,自身不设计数据存储与查询,资源消耗低;相反数据节点是集群存储与查询的执行节点
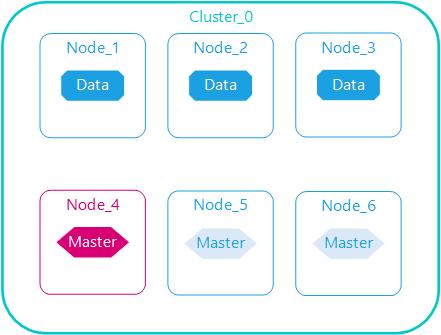
管理节点与数据节点分离,各司其职,任意数据节点故障或者全部数据节点故障,集群仍可用;管理节点一般至少启动3个,任意节点停机,集群仍正常运行。
数据与协调分离
Elasticsearch内部执行查询或者更新操作时,需要路由,默认所有节点都具备此职能,特别是大的查询时,协调节点需要分发查询命令到各个数据节点,查询后的数据需要在协调节点合并排序,这样原有数据节点代价很大,所以分离职责

协调读写分离
Elasticsearch设置读写分离指的是在协调节点上,不是数据节点上,集群大量的查询需要消耗协调节点很大的内存与CPU合并结果,同时集群大量的数据写入会阻塞协调节点,所以在协调节点上做读写分离很少必要,也很简单,由集群设计搭建时规划好即可。
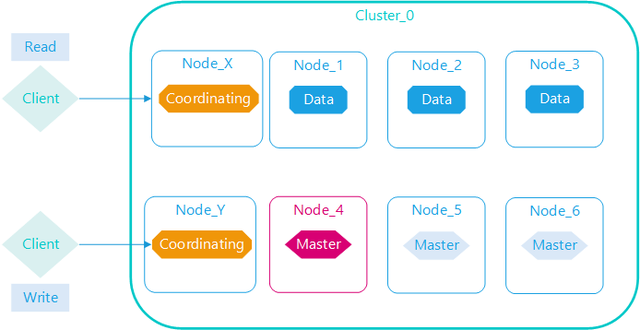
数据节点标签
Elasticsearch给数据节点标签,目的是分离索引数据的分布,在一个集群规模中等以上,索引数据用途多种多样,对于数据节点的资源需求不一样,数据节点的配置可以差异化,有的数据节点配置高做实时数据查询,有的数据节点配置低做历史数据查询,有的数据节点做专门做索引重建。
Elasticsearch集群部署时需要考虑基础硬件条件,集群规模越来越大,需要多个数据中心,多个网络服务、多个服务器机架,多个交换机等组成,索引数据的分布与这些基础硬件条件都密切相关
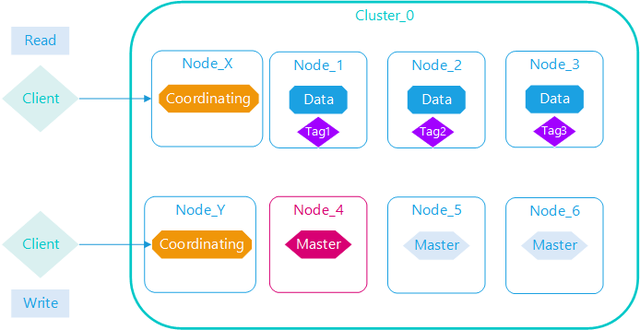
主副分片分离
Elasticsearch集群规模大了之后得考虑集群容灾,若某个机房出现故障,则可以迅速切换到另外的容灾机房
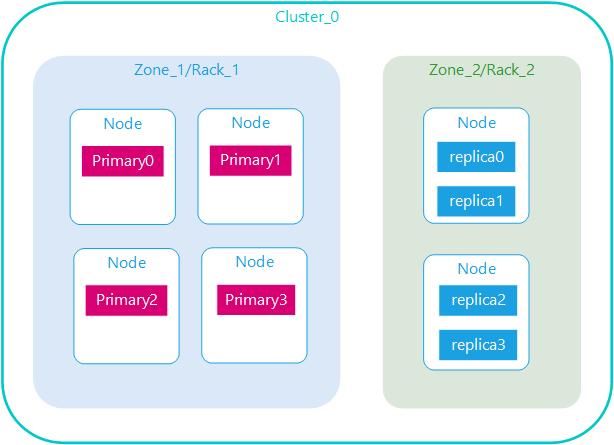
跨集群操作
Elasticsearch单个集群规模不能无限增长,理论上可以,实际很危险,通过创建多个分集群分解,集群直接建立直接连接,客户端可以通过一个代理集群访问任意集群,包括代理集群本身数据。
Elasticsearch集群支持异地容灾,采用的是跨集群复制的机制,与同一集群主分片副本分片分离是不同的概念,2个集群完全是独立部署运行,仅数据同步复制。
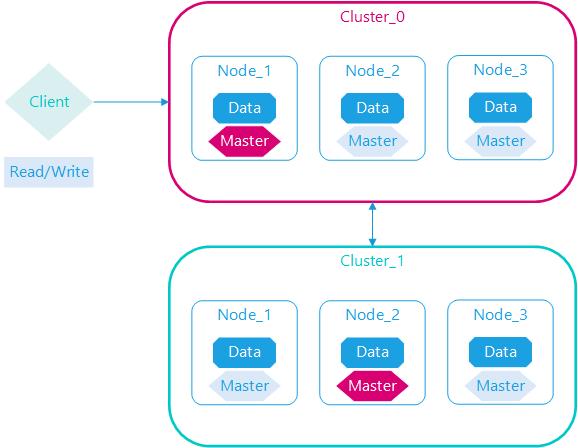
跨集群版本操作
elasticsearch版本更新很快,已知问题修复很快,新特性新功能推出很快,一日不学,如隔三秋。有的集群数据重要性很高,稳定第一,不能随意升级,有的业务场景刚好需要最新版本新功能新特性支持。
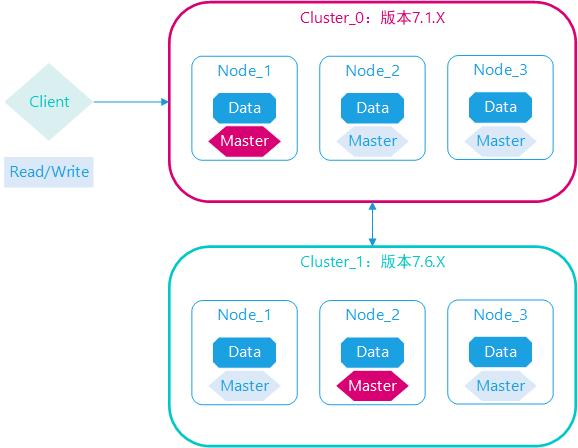
集群管理
集群健康检查
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康 , 它在
status字段中展示为green、yellow或者red
查看集群状态
可以通过如下的命令查看集群的状态
1 | GET /_cluster/health |
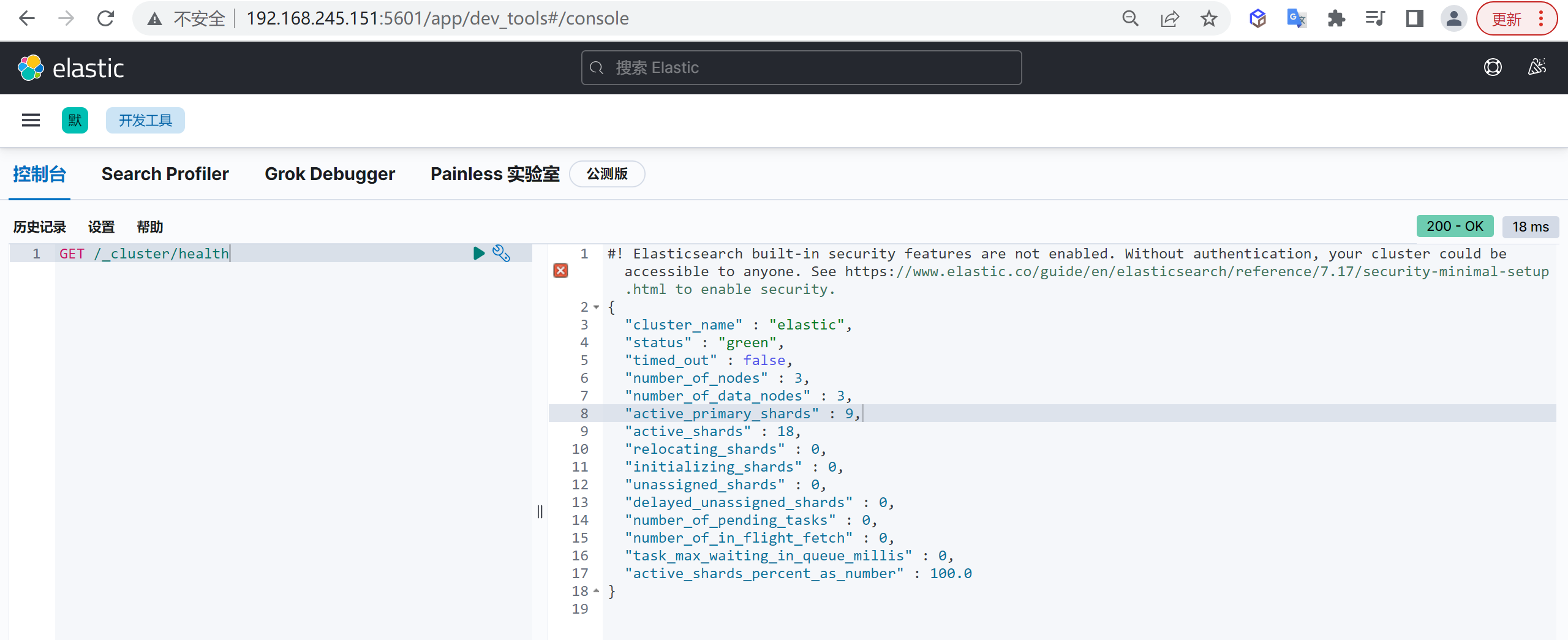
集群状态
status字段是我们最关心的,status字段指示着当前集群在总体上是否工作正常,它的三种颜色含义如下
**
green**:所有的主分片和副本分片都正常运行**
yellow**:所有数据可用,但有些副本尚未分配(集群功能完全)**
red**:有主分片没能正常运行。
注意: 当集群处于红色状态时,正常的分片将继续提供搜索服务,但你可能要尽快修复它。
分片和副本
什么是分片
因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片,每个分片放到不同的服务器上。
当你查询的索引分布在多个分片上时,ES会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在,即:这个过程对用户来说是透明的
ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节,一个分片默认最大文档数量是20亿。
分片的意义
分片存在的重要原因有以下两个:
- 允许水平分扩展容量。
- 允许在分片之上进行分布式的,并行的操作,从而提高其吞吐量。
分片的本质
分片质上是一个lucene的索引,一个分片就是一个lucene索引
一个elasticsearch索引就是一个lucene索引的集合,当进行查询时,会将查询请求发送到每一个属于当前elasticsearch索引的分片上,然后将每个分片得到的结果进行合并返回。
什么是副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。
副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片,当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
ES默认为一个索引创建5个主分片,并分别为其创建一个副本分片, 也就是说每个索引都由5个主分片成本,而每个主分片都相应的有一个copy
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
副本的意义
副本存在的两个重要原因:
- 提高可用性:注意的是副本不能与主/原分片位于同一节点。
- 提高吞吐量:搜索操作可以在所有的副本上并行运行。
分片和副本的区别
分片与副本的区别在于:
分片
当你分片设置为5,数据量为30G时,es会自动帮我们把数据均衡地分配到5个分片上,即每个分片大概有6G数据,当你查询数据时,ES会把查询发送给每个相关的分片,并将结果组合在一起。
副本
而副本,就是对分布在5个分片的数据进行复制,因为分片是把数据进行分割而已,数据依然只有一份,这样的目的是保障查询的高效性,副本则是多复制几份分片的数据,这样的目的是保障数据的高可靠性,防止数据丢失。
分片验证
下面我们验证以下分片的使用
验证一个分片
首先我们通过建立索引的方式来看下什么是分片,会产生哪些变化。
创建索引
我们首先创建一个名为
test的索引,让它有一个分片,我们看看结果,在kibana执行以下命令
1 | PUT test |
这样我们就创建了一个分片
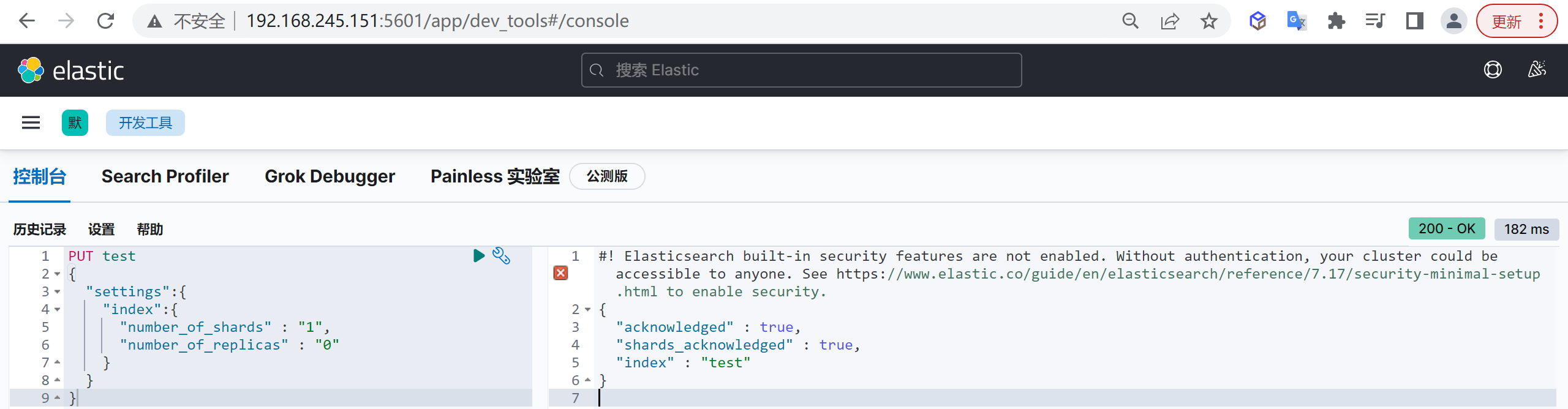
查看分片
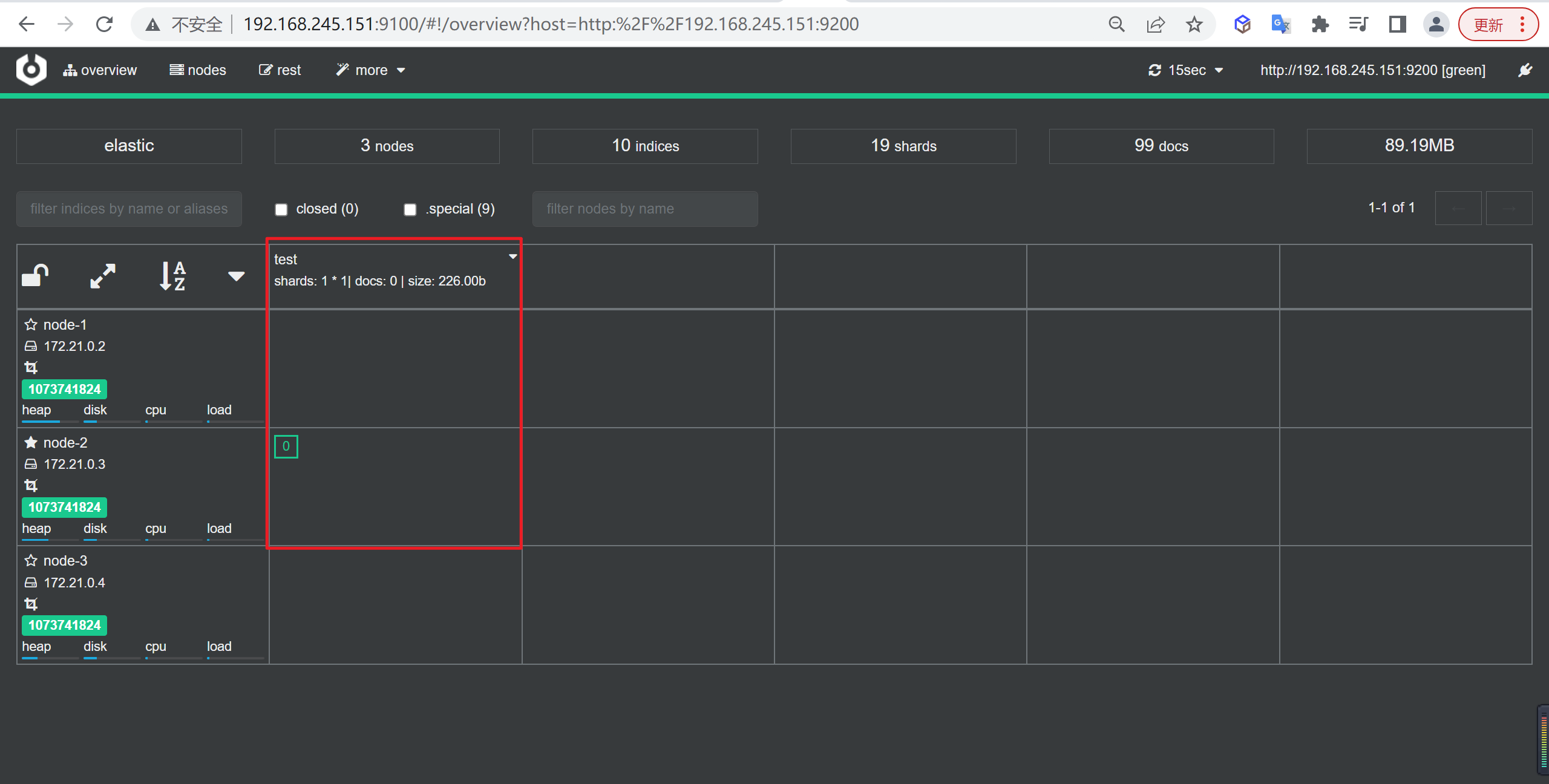
我们在
cerebro中查看结果,我们看到test只在node-2节点上:
验证两个分片
我们再来创建两个分片看看会发生上面
创建索引
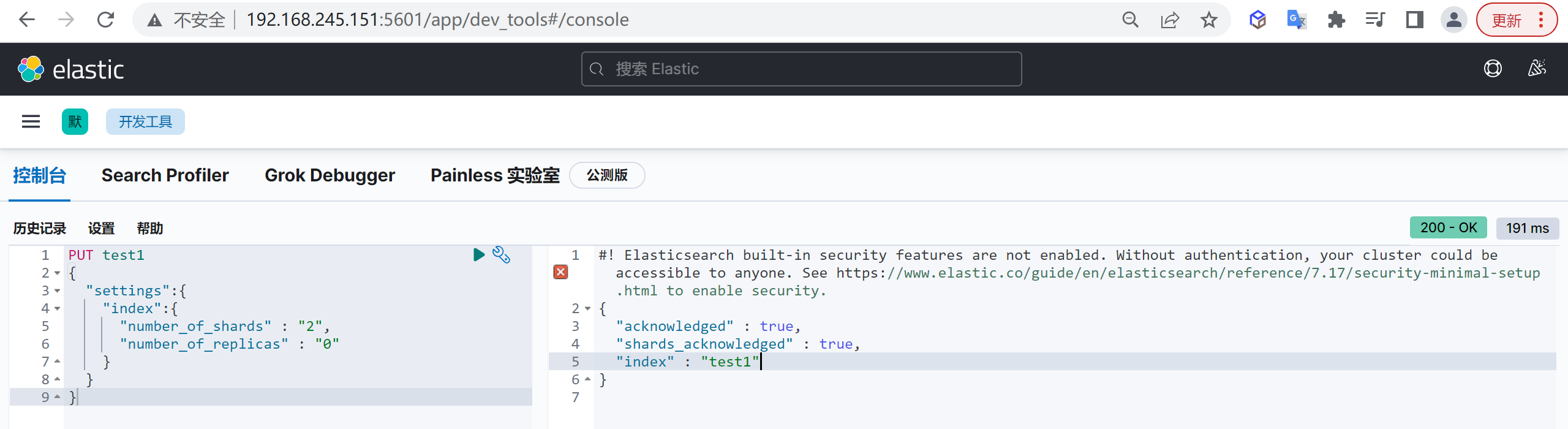
我们再次创建两个分片的test1
1 | PUT test1 |
这样我们就创建了一个索引
查看分片
我们在
cerebro中查看结果,我们看到test1在node-1和node-3上面
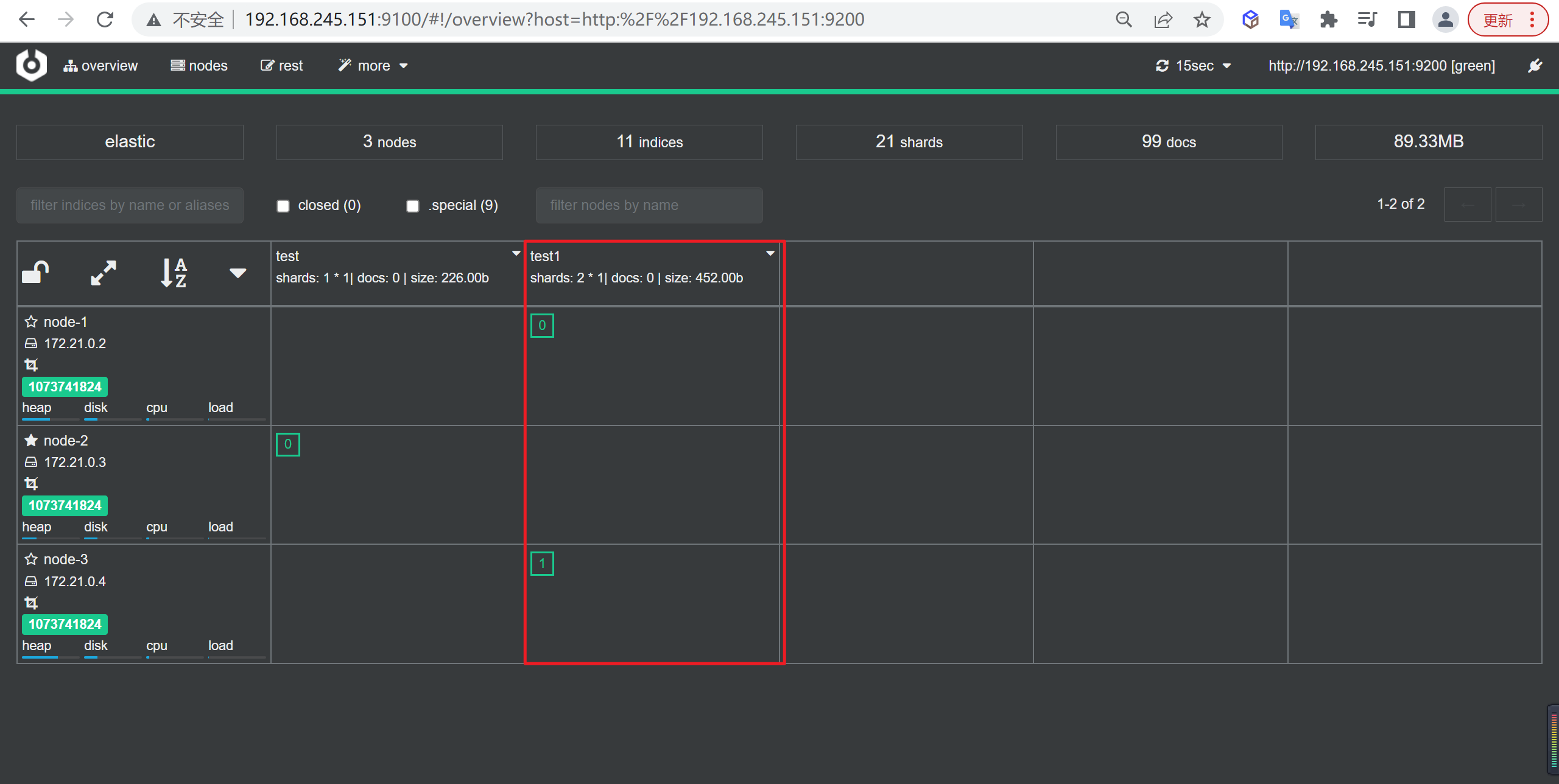
如上图看到分片分别分布在两个节点上,不用想,如果是3个那么肯定均匀分布在三个节点上
验证四个分片
如果我们创建四个分片,多于节点数会发生什么呢
创建索引
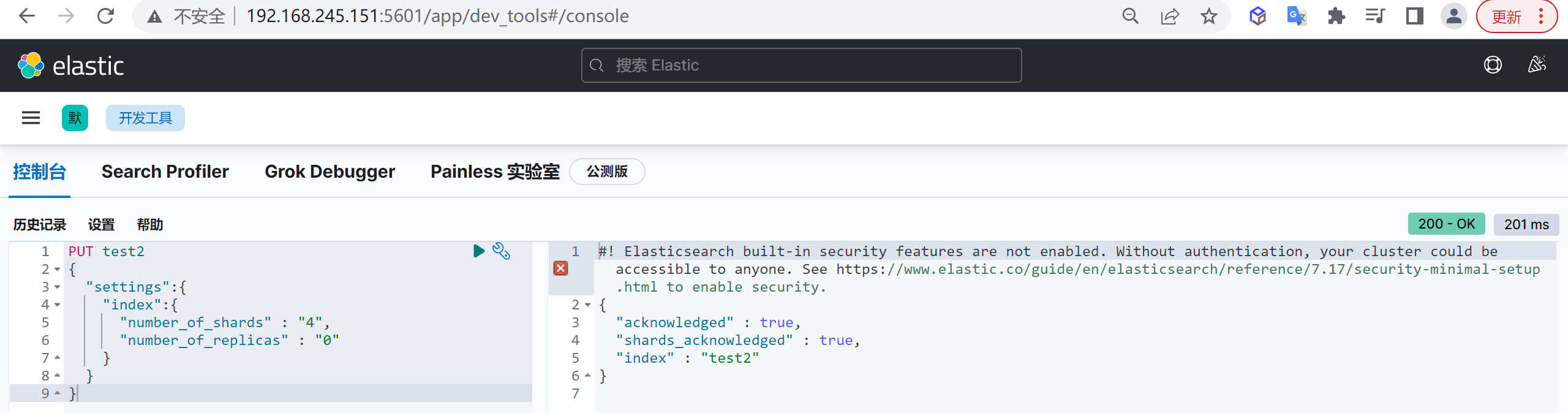
我们创建四个分片的索引
1 | PUT test2 |
这样我们就创建了一个索引
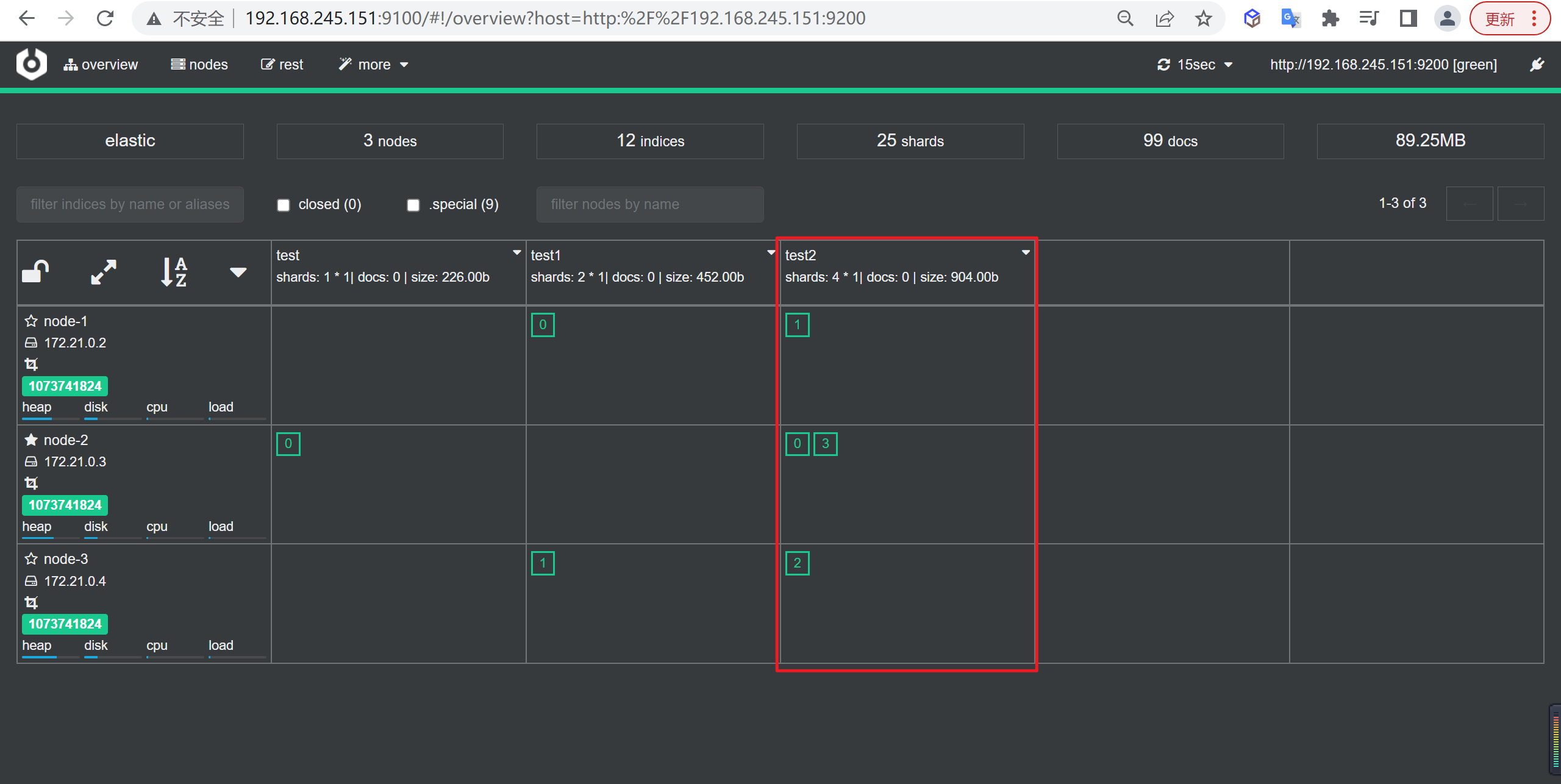
查看分片
我们发现有两个分片在
node-2的节点上
验证副本
下面我们对副本进行验证
验证两副本分片
创建索引
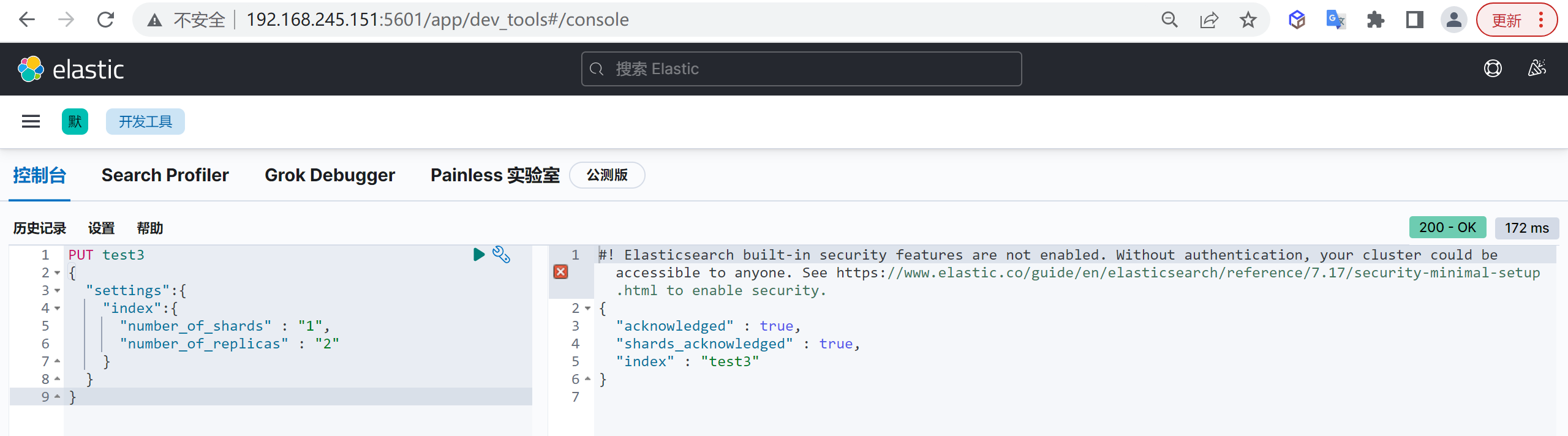
创建一个含有一个分片,两个副本的test3:
1 | PUT test3 |
这样我们就创建出来了一个分片带两个分片的索引
查看索引
如下图所示,我们看到了3个绿色的0,其中在
node-1节点的边框是粗体的,这个表示分片,而另外两个节点的0的边框是虚线的,这两个就是分片的副本。
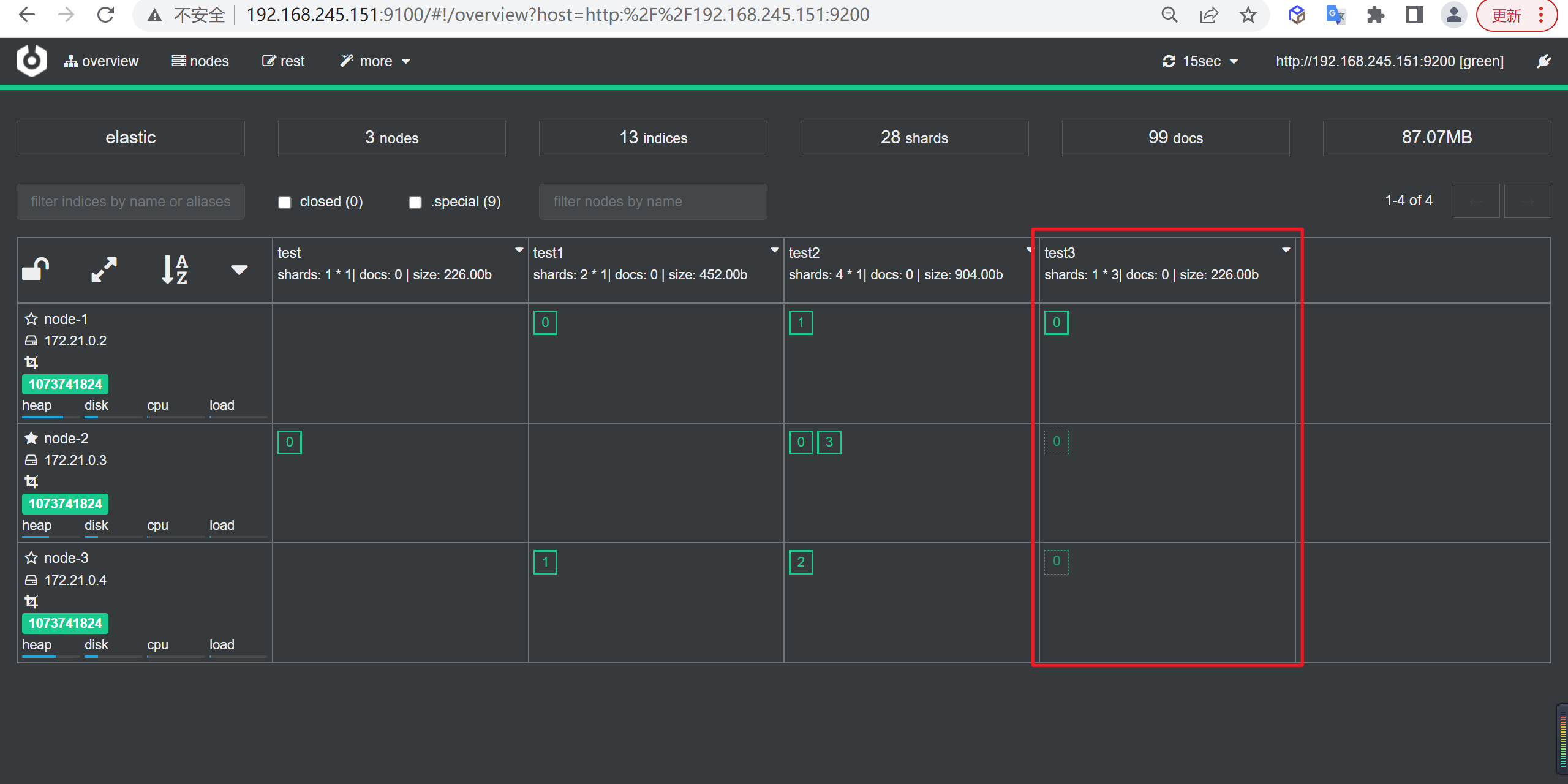
通常我们三个节点建立两个副本就可以了,三份数据均匀得到分布在三个节点
验证三副本分片
如果建立三个副本会怎么样呢?
创建索引
创建一个分片三个副本的索引
1 | PUT test4 |
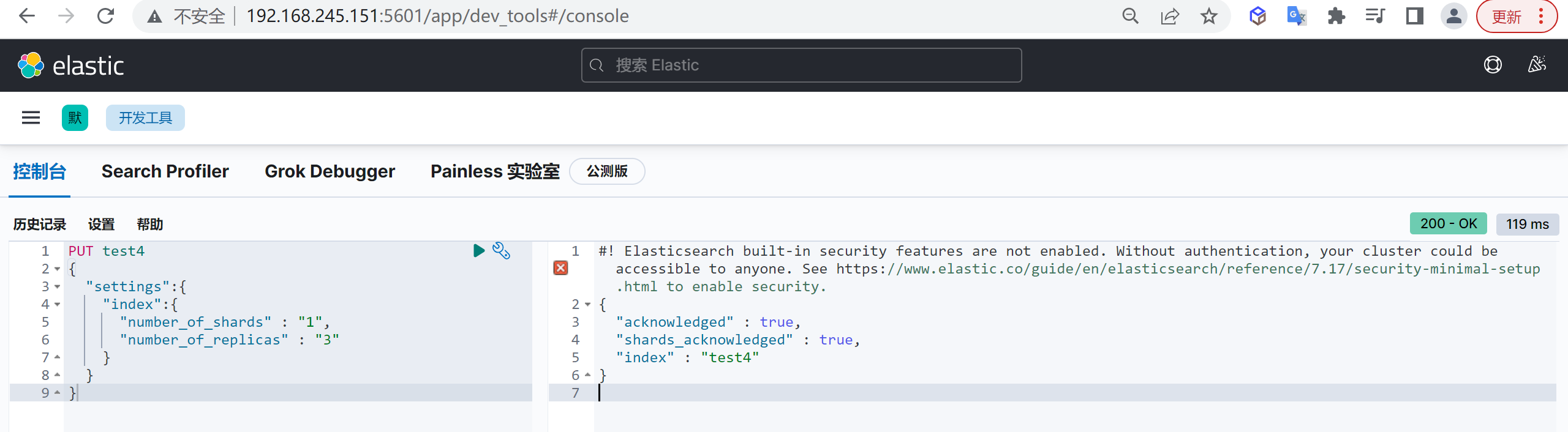
查看索引
如下所示我们看到多出一个Unassigned的副本,这个副本其实是多余的了,因为每个节点已经包含了分片的本身和其副本,多于这个没有意义!
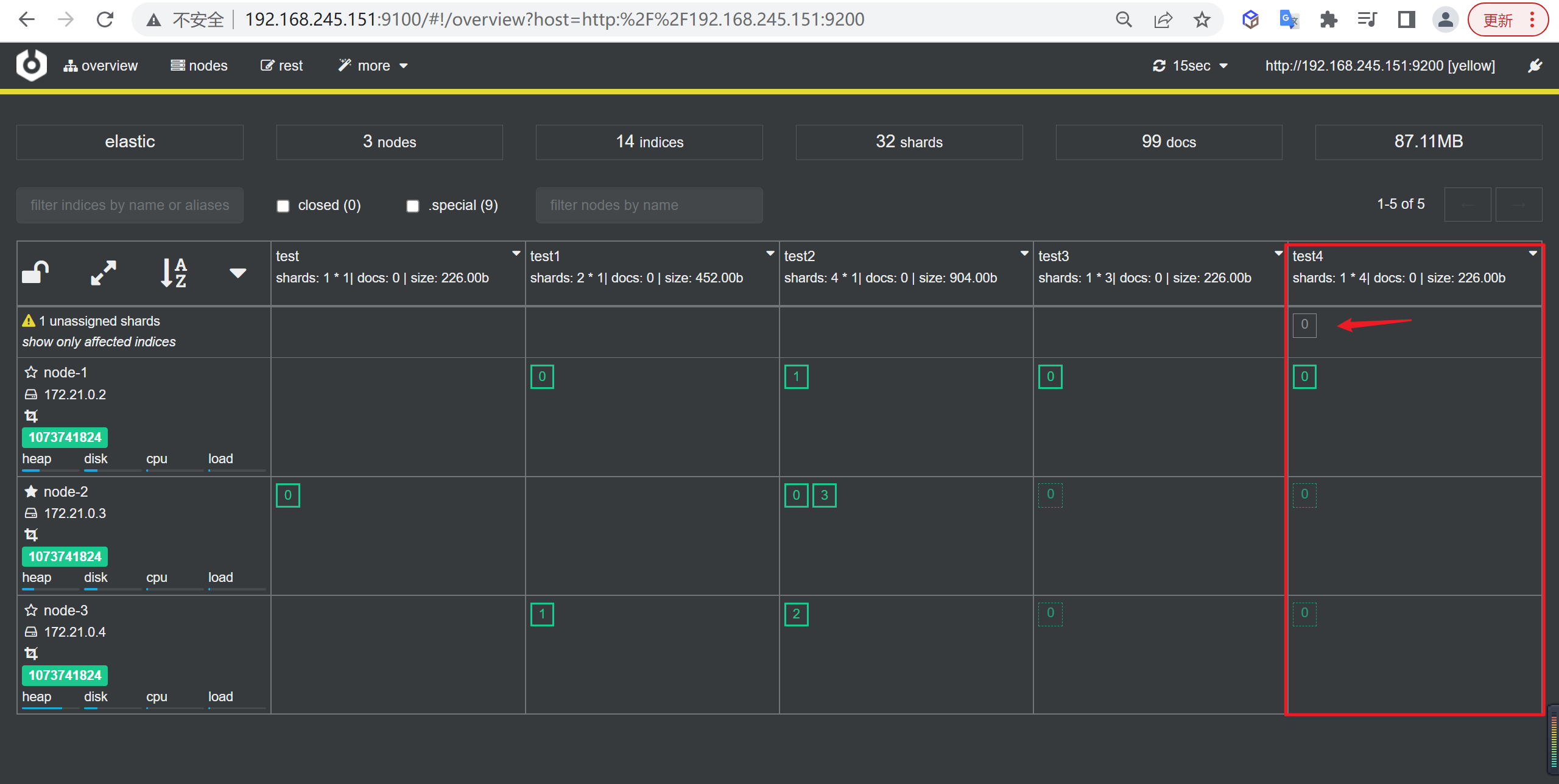
并且因为多出来了一个副本无法分配,整个集群都变成了
yellow的状态
分片与副本的组合
默认组合
如果不指定分片和副本会怎么样呢
创建索引
创建一个索引不指定副本和索引数量
1 | PUT test5 |
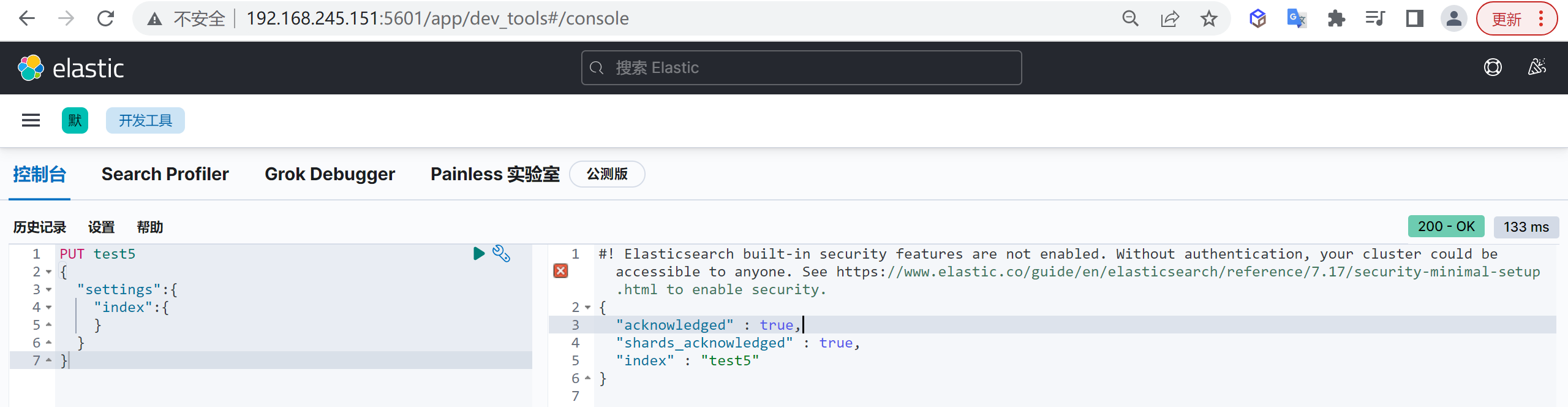
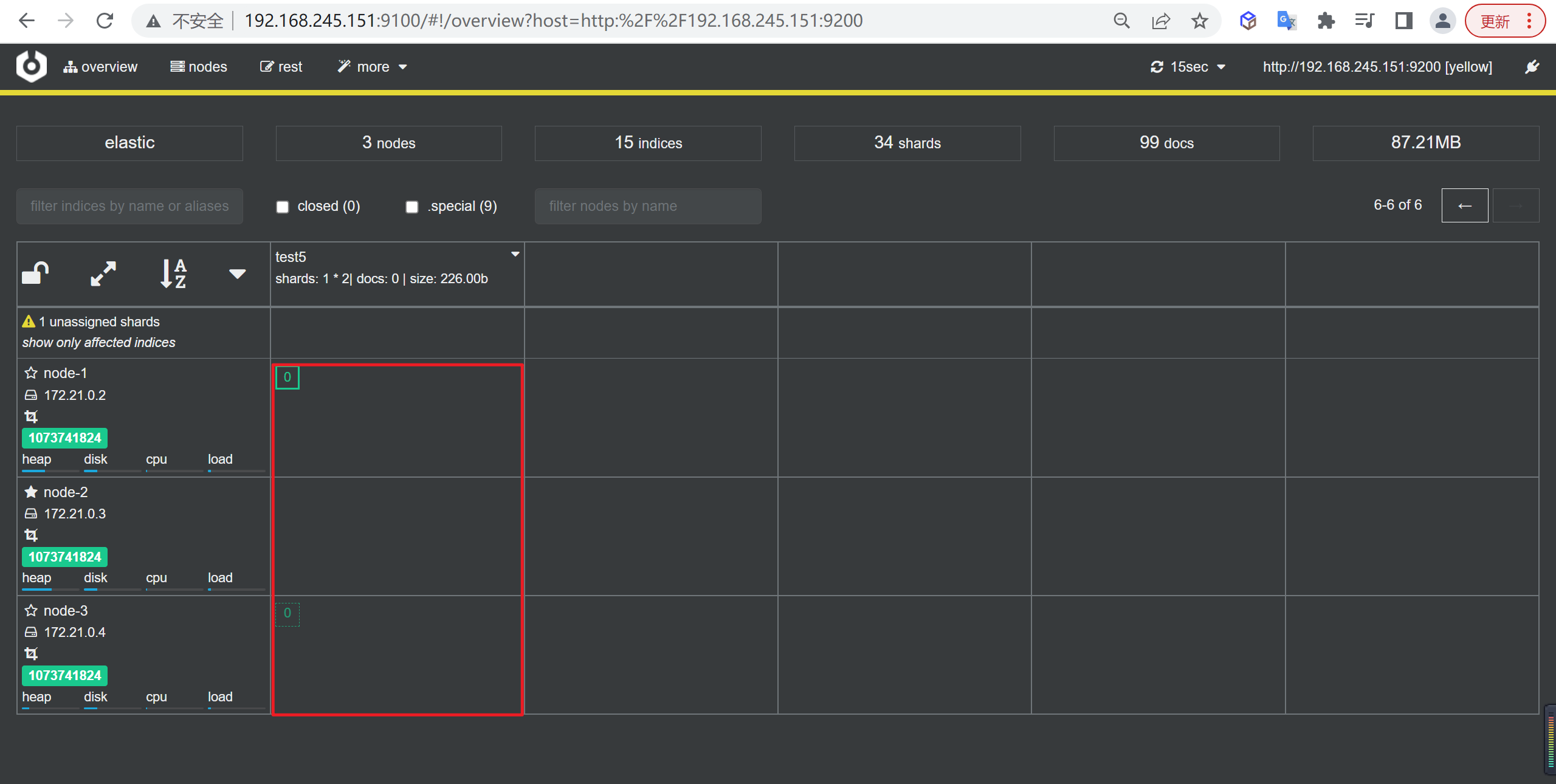
查看索引
如下图所示看到默认是有一个分片和一个副本的。
两副本两分片
下面我们试验一下两副本两分片,看看会发生什么
创建索引
下面我们创建两个分片和两个副本
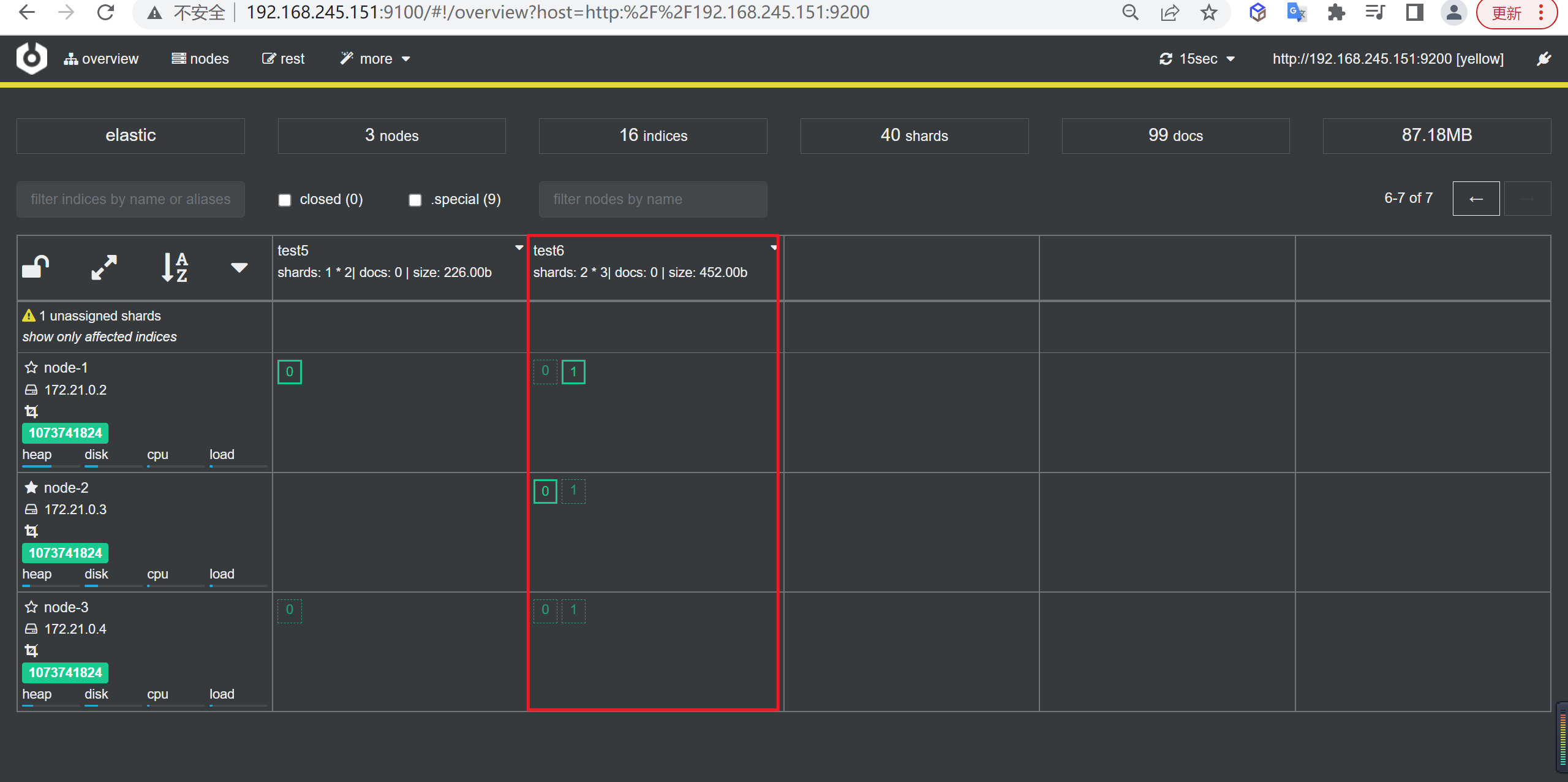
1 | PUT test6 |
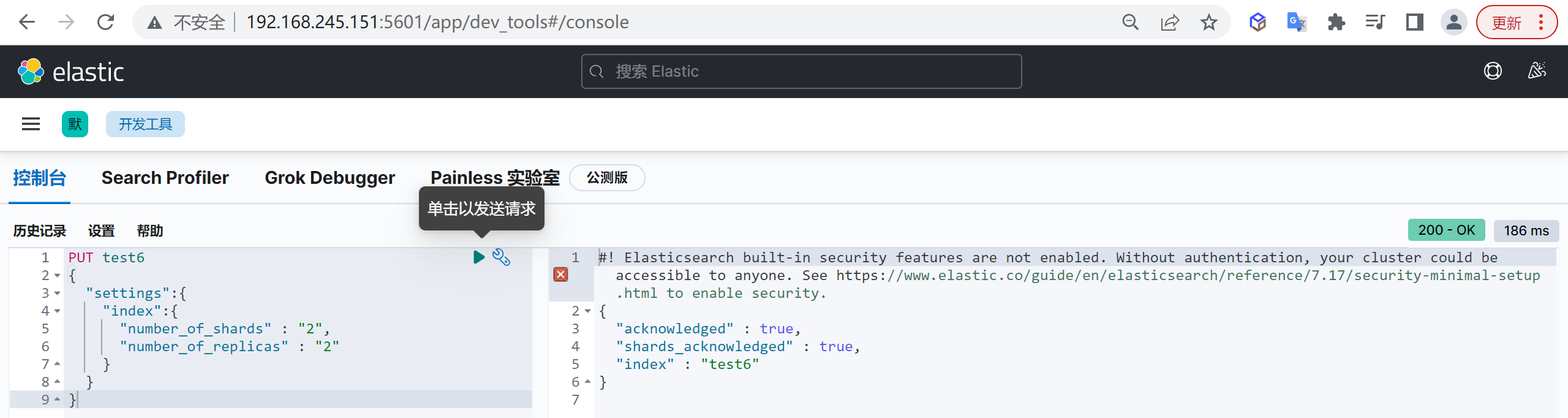
查看索引
我们看到下面就是两副本两分片的情况,每一个分片都有两个副本,如果再多一个副本就会无法再分配了
三分片两副本
下面我们验证以下三分片两副本的情况
创建索引
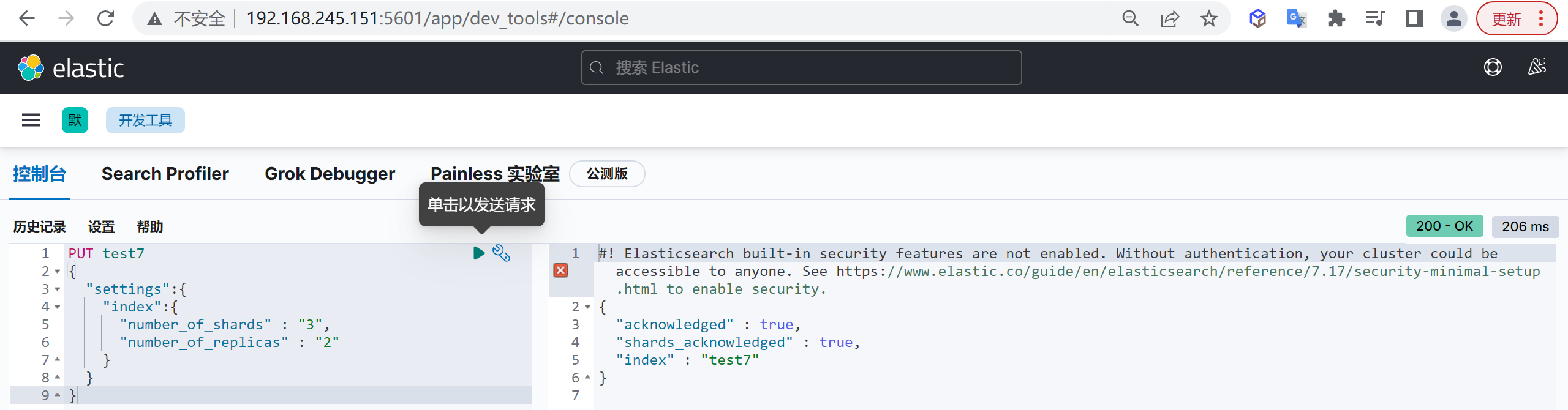
我们创建一个三个分片两个副本的索引
1 | PUT test7 |
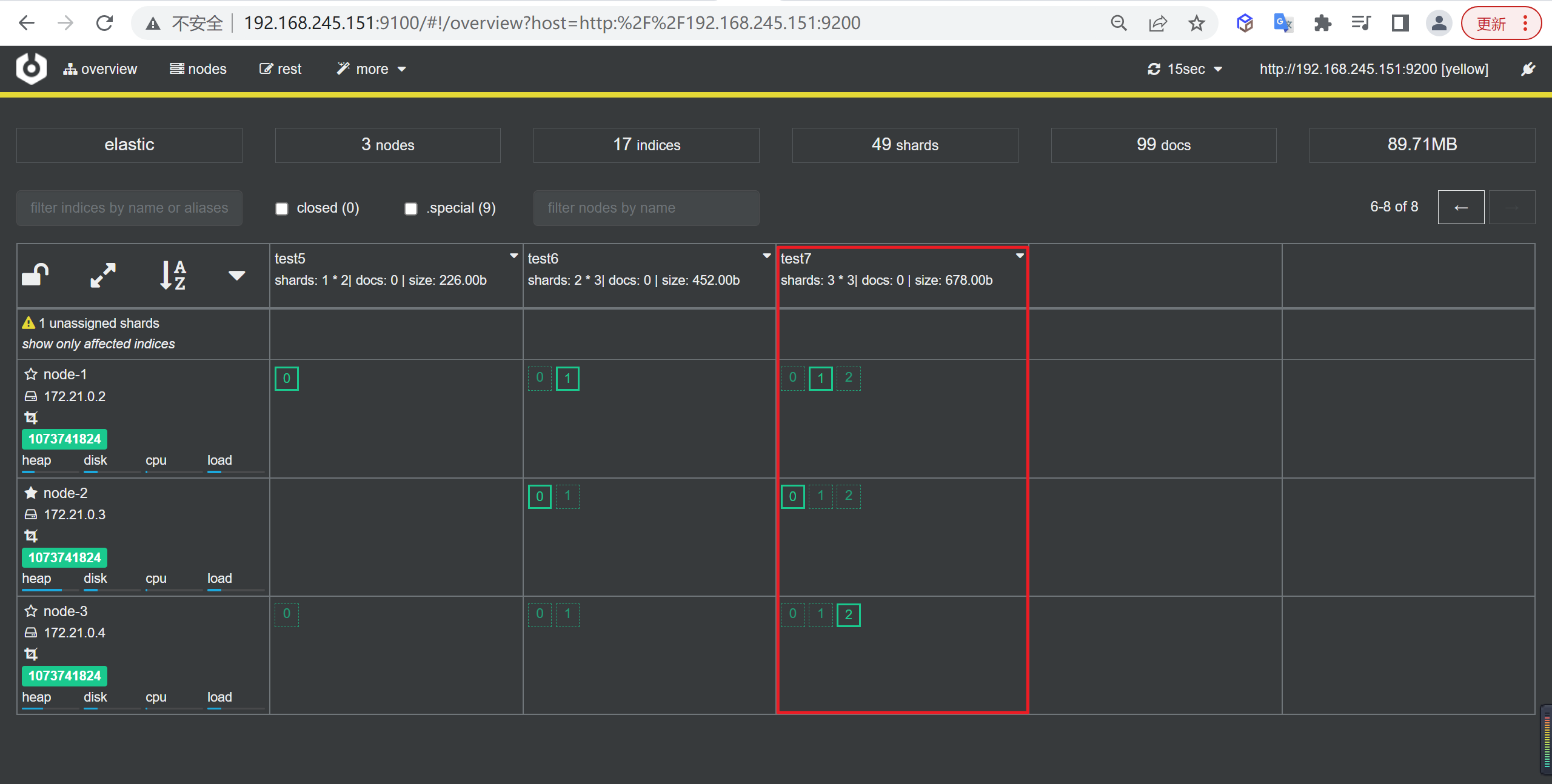
查看索引
如下所示看到分片和副本都均匀的分布在每个节点上。
故障与恢复
故障转移
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全,这个叫做故障转移。
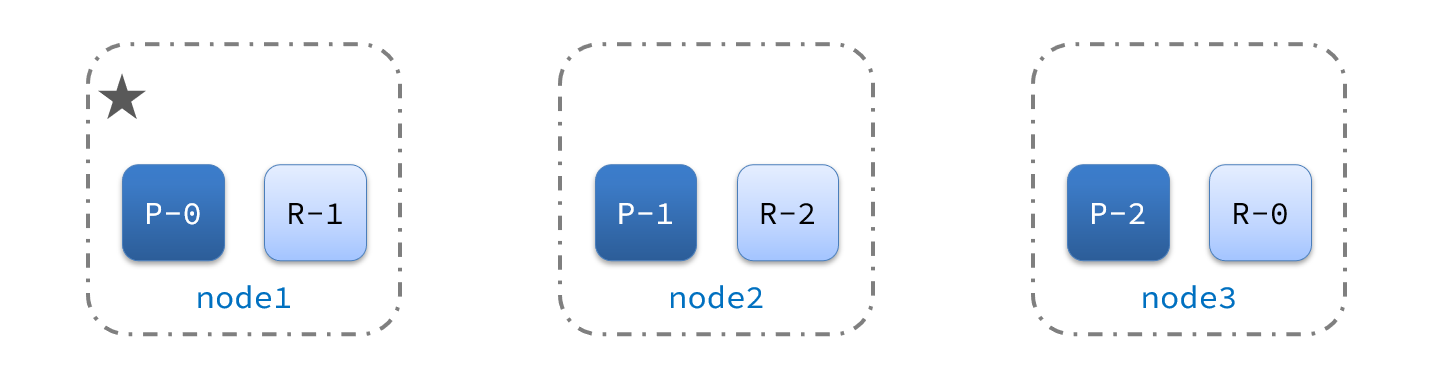
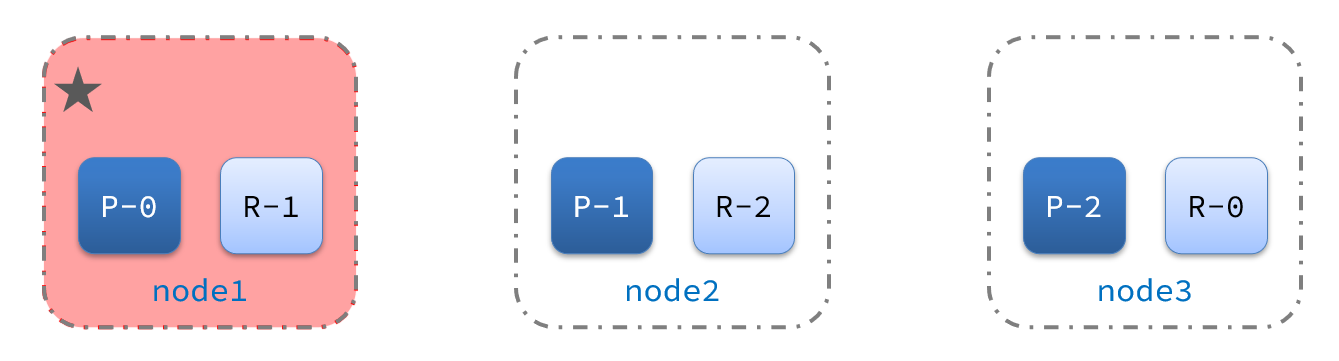
正常集群状态
下图是正常集群的状态,node1是主节点,其它两个节点是从节点
节点故障
突然,node1发生了故障
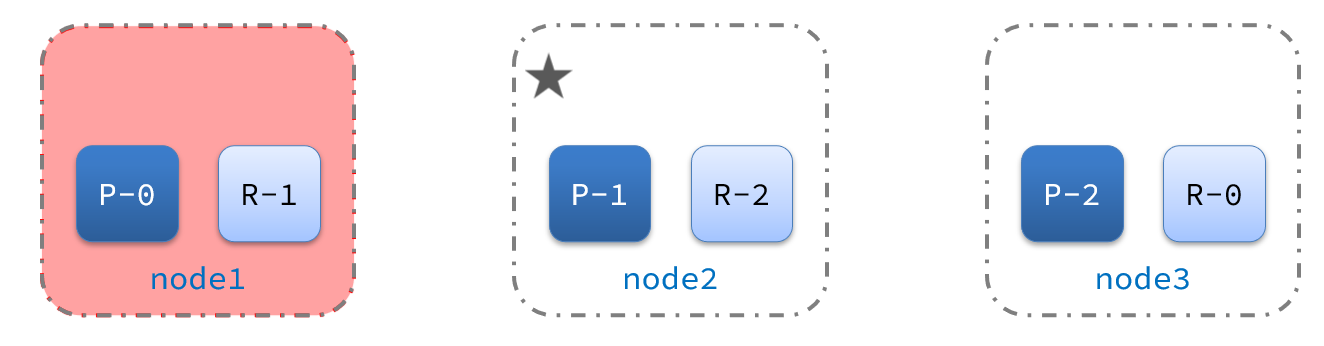
宕机后的第一件事,需要重新选主,例如选中了node2
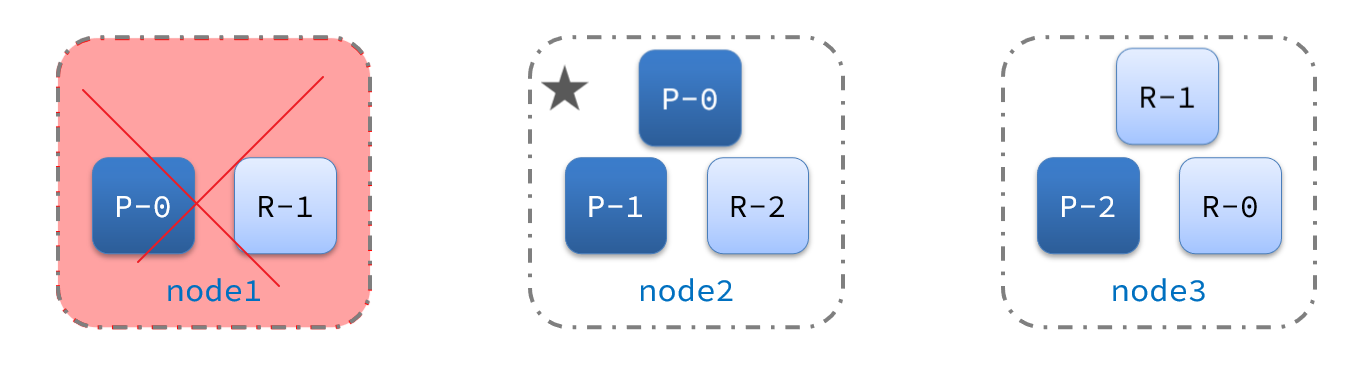
数据迁移
node2成为主节点后,会检测集群监控状态,发现:shard-1、shard-0没有副本节点,因此需要将node1上的数据迁移到node2、node3
节点故障
我们观察下如果三个节点有一个节点宕机了,上文的
test7的分片和副本会有哪些变化
关闭node2节点
我们关闭
node-2节点
执行关闭命令
我们暂停
node-2节点
1 | docker pause node-2 |
查看索引
如下所示,原本的node-2节点变成了Unassigned
注意我标注的三个红框内的分片,这三个分片已经随着节点的宕机消息了,这就造成了数据的丢失,反观后面几个,虽然node2宕机了,但是由于我们做了分片与备份,索引仍然可以正常的工作,
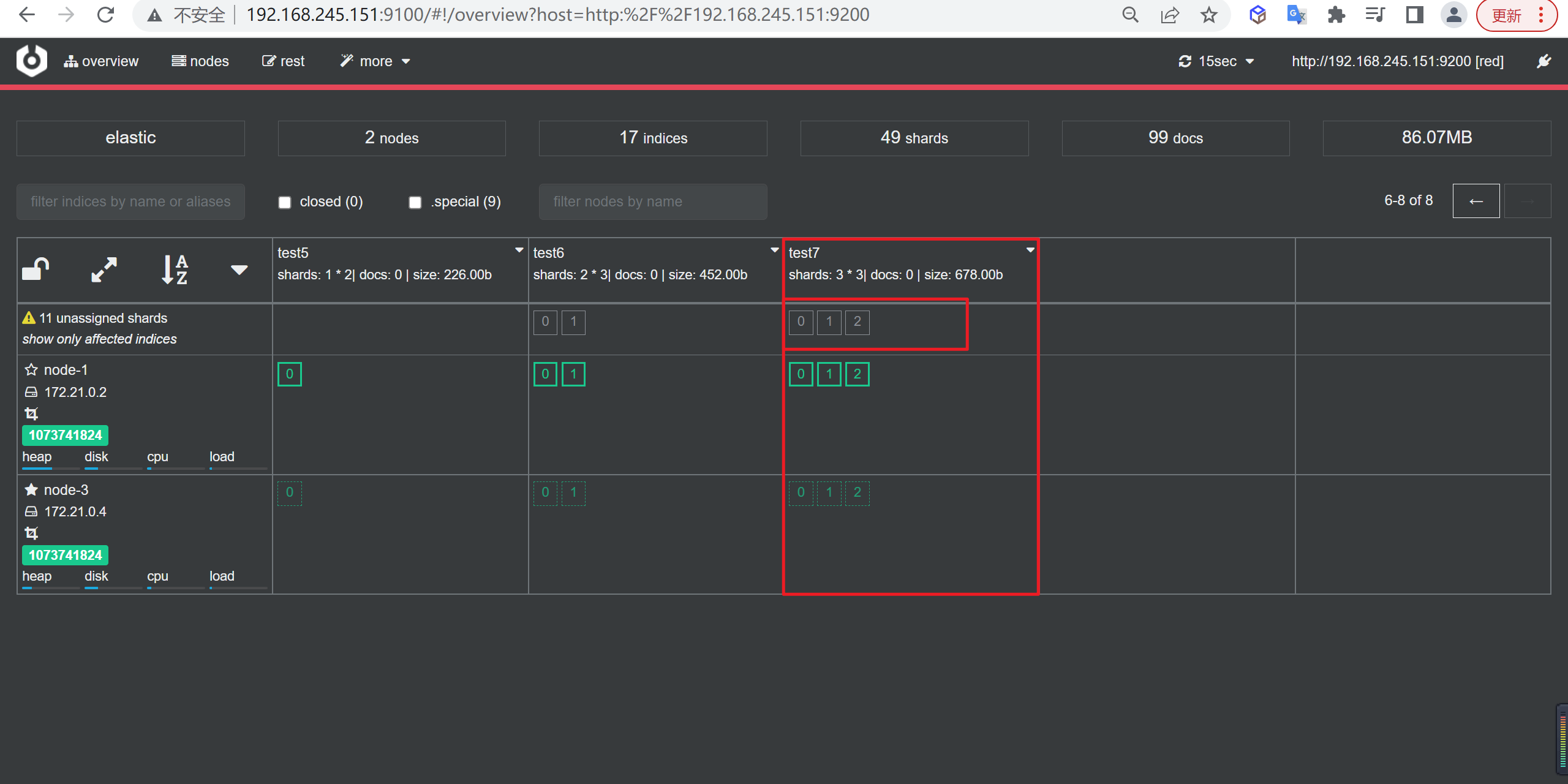
原本在node-2的2号分片移动到了node-1节点,在使用es集群的过程中,一定要注意分片和副本的使用,保证我们整个集群的高可用性
关闭node3节点
我们关闭以下node-3节点看下情况
执行关闭命令
执行如下命令暂停node-3
1 | docker pause node-3 |
查看集群状态
通过
Cerebro我们发现整个集群已经无法进行访问了
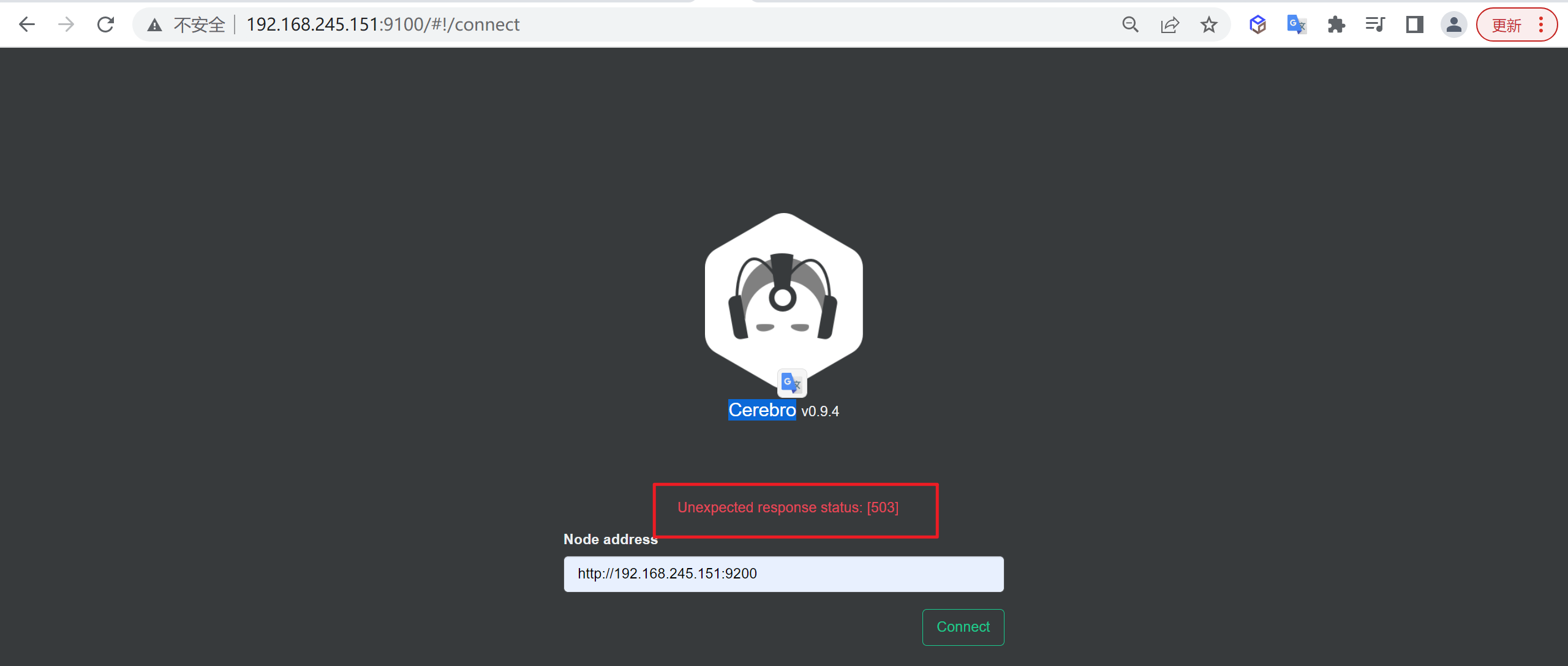
当集群中的节点数少于半数,将导致整个集群不可用
节点恢复
经过上面的宕机试验后,我们现在要对宕机的服务进行启动
启动node2节点
我们先启动node2节点
执行启动命令
执行下面的命令恢复node-2节点
1 | docker unpause node-2 |
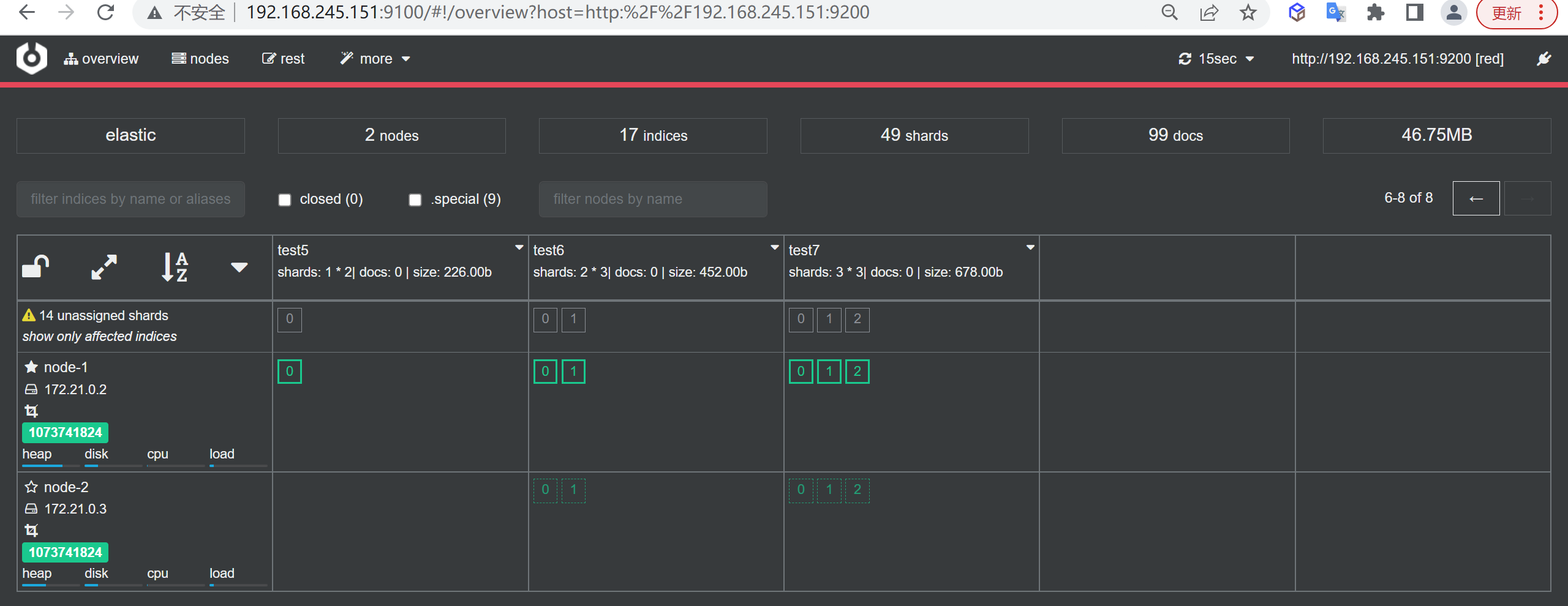
查看集群状态
如上发现集群已经能够恢复访问了
创建索引
此时我们在两个几点可用的情况下创建一个有三分片,两个副本的索引
1 | PUT test8 |
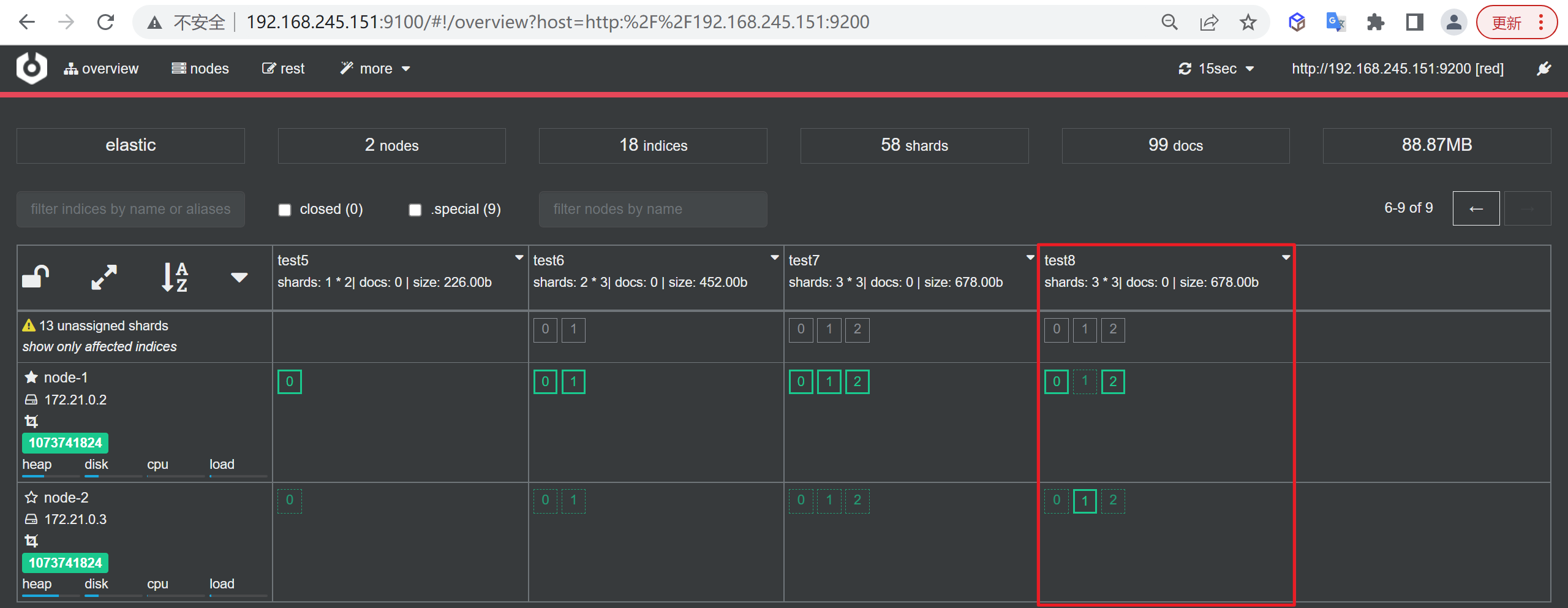
查看索引状态
如下所示,分片与副本的分布没有问题,有三个副本未分配
启动node3节点
下面我们就启动node3节点
执行启动命令
执行下面的命令恢复node-2节点
1 | docker unpause node-3 |
查看索引
所有的未分配副本移动到了node-3节点,并没有将分片移动到node-2上
扩缩容
服务布局
我们整体采用Docker方式进行布局,以下是我们需要部署的服务,标红色的我们需要新增的节点
| 服务名称 | 服务名称 | 开放端口 | 内存限制 |
|---|---|---|---|
| ES-node1 | node-1 | 9200 | 1G |
| ES-node2 | node-2 | 9201 | 1G |
| ES-node3 | node-3 | 9202 | 1G |
| ES-node4 | node-4 | 9203 | 1G |
| ES-cerebro | cerebro | 9000 | 不限 |
| kibana |
扩容节点
创建节点目录
创建ES的节点目录
1 | mkdir -p /tmp/data/elasticsearch/node-4/{config,plugins,data,log} |
添加IK分词器
只要将其他节点的IK分词器复制过来就可
1 | cp -R ik/ /tmp/data/elasticsearch/node-4/plugins/ |
编写配置文件
我们边界node4节点的配置文件
1 | vi /tmp/data/elasticsearch/node-4/config/elasticsearch.yml |
1 | #集群名称 |
编写部署文档
我们在部署脚本增加node-4节点
1 | vi docker-compose.yml |
1 | version: "3" |
启动服务
我们完成配置后就可以启动服务了
1 | docker-compose up -d |
查看节点信息
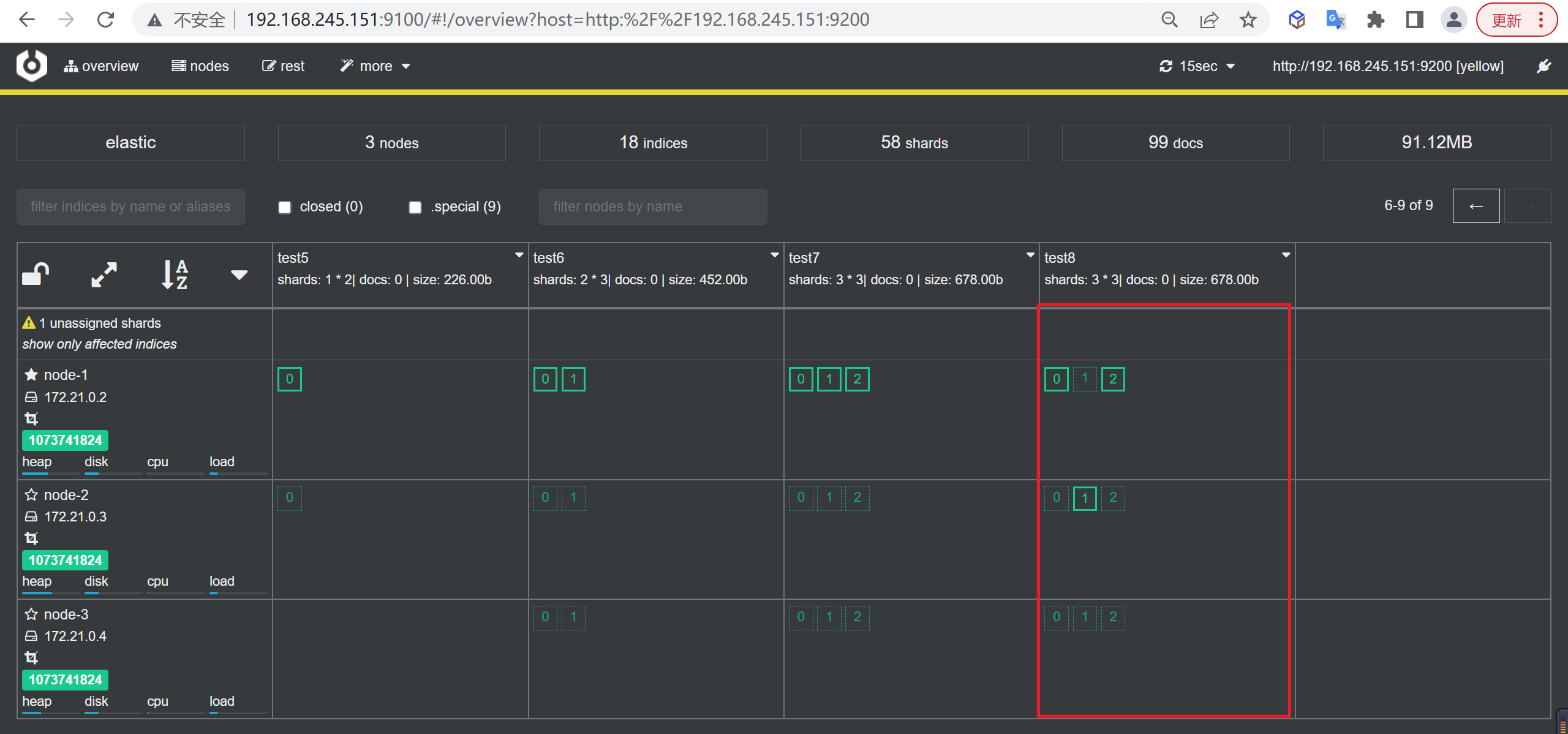
我们可以在监控界面看到节点的信息,我们发现节点4已经加入进来了
节点缩容
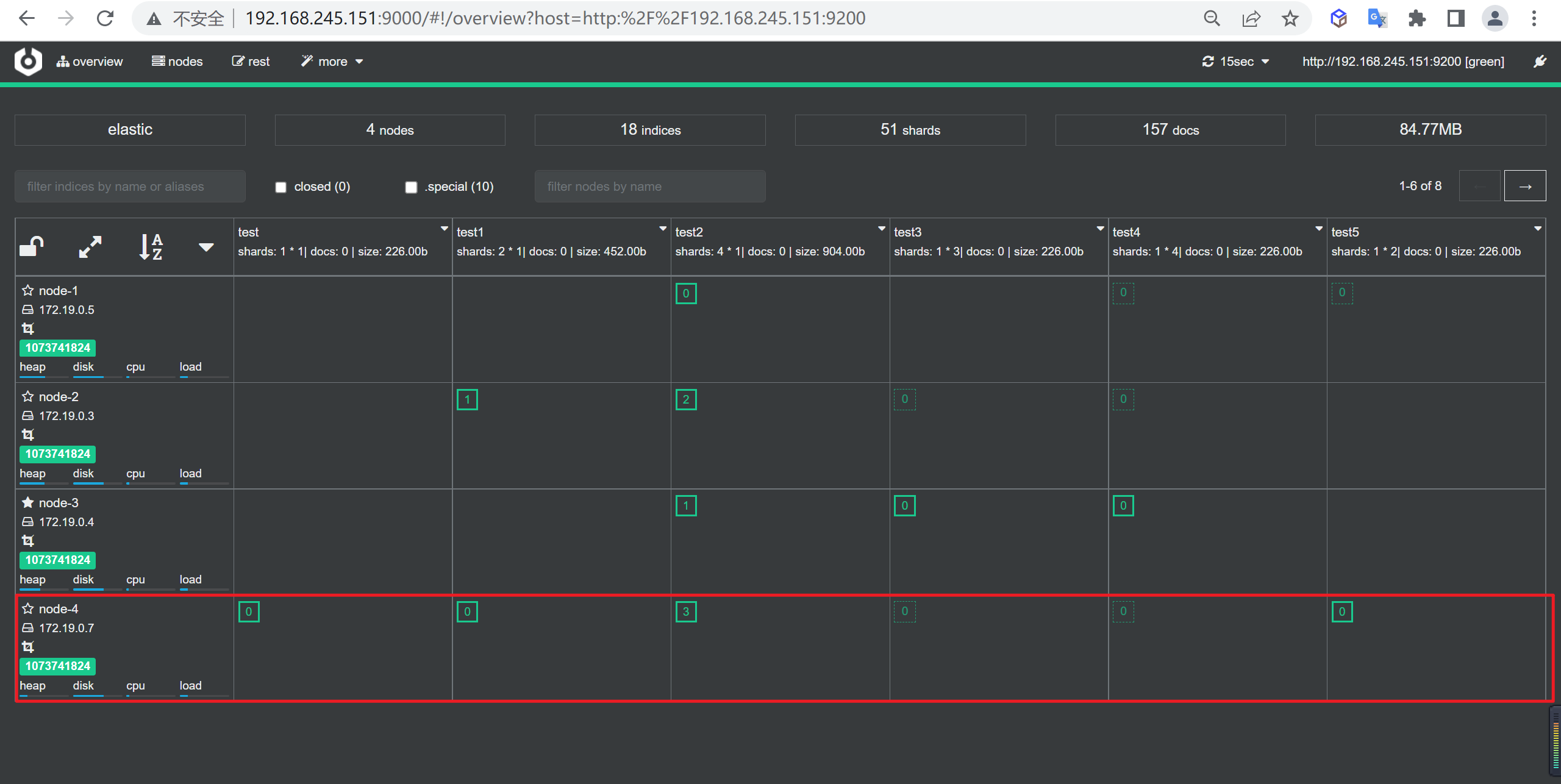
接下来我们要将node4节点去掉完成缩容操作
禁止数据分配
我们先排除node-4节点,禁止数据在该节点分配数据,然后才能停止节点,如果想正常缩容,这里填上所有要缩容的节点名称就可以了
1 | PUT /_cluster/settings |
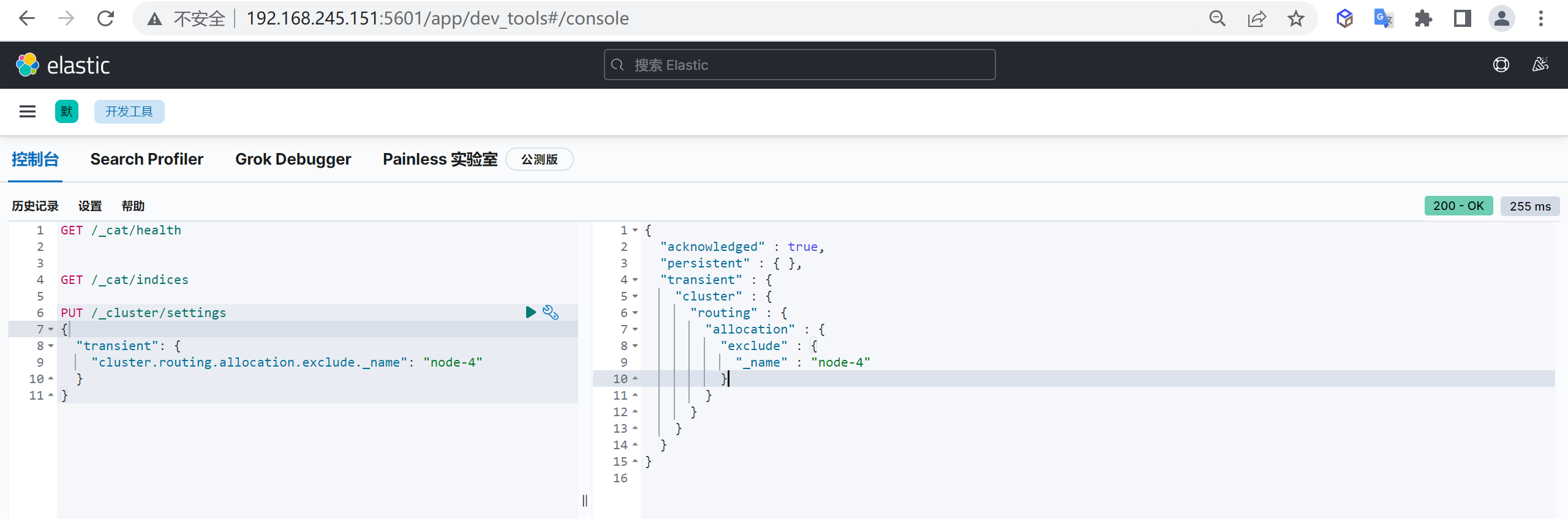
检查数据分配
接下来检查一下缩容节点的数据迁移情况,我们发现数据已经全部迁移完成了
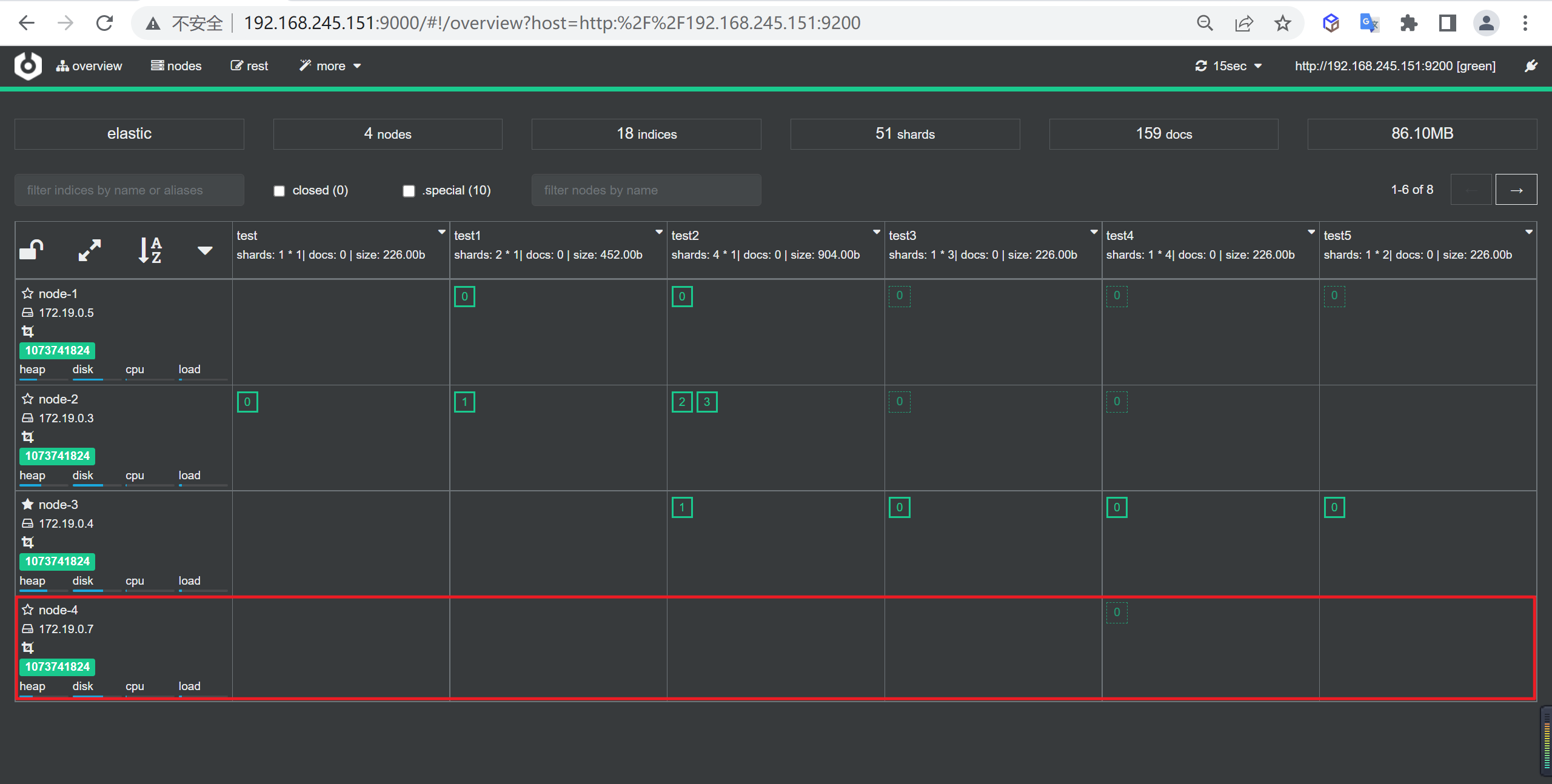
关闭节点
等到数据全部迁移完成后就可以进行缩容节点了
1 | docker-compose stop node-4 |

查看集群情况
接下来看一下集群的情况,我们发现已经缩容成功了,并且没有出现主分片丢失的情况